Одна модель или парк моделей: как считать издержки
Одна модель или парк моделей - сравнение расходов на чат, поиск, классификацию и суммаризацию, с понятной схемой расчёта и типовыми ошибками.
Где начинается дорогой выбор
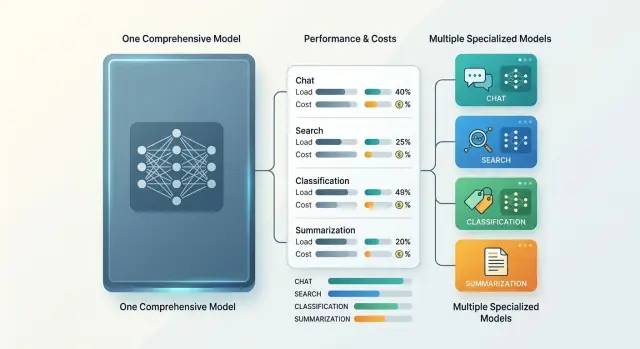
Дорогой выбор начинается в тот момент, когда команда решает, что одна и та же схема подойдет и для чата, и для поиска, и для классификации, и для суммаризации. На бумаге это удобно: один поставщик, одна модель, меньше настроек. На практике такой подход часто дает либо переплату за лишнюю мощность, либо просадку качества там, где ошибка особенно заметна.
Вопрос "одна модель или парк моделей" часто сводят к цене за токен. Этого мало. Счет растет не только из-за инференса. На него влияют промпты, ретраи, кэширование, мониторинг, ручные проверки, инциденты в продакшене и время команды, которая держит схему в рабочем состоянии.
Считайте отдельно три метрики:
- качество для конкретной задачи
- цену одного успешного результата
- скорость и стабильность под реальной нагрузкой
Если смешать эти метрики в одну, решение почти всегда получается неточным. Модель может хорошо вести диалог, но тормозить в поиске по каталогу. Или дешево классифицировать обращения, но сыпаться на длинной суммаризации.
Ошибка в выборе быстро бьет по двум местам. Финансы видят рост затрат на API и инфраструктуру. Команда получает больше скрытой работы: чинит маршруты, разбирает жалобы, заново меряет качество, пересматривает лимиты и правила обработки данных.
Для российских команд есть еще один слой расходов. При работе с чувствительными данными приходится считать не только модель, но и то, где хранятся логи, как маскируется PII и как проходит аудит запросов. Даже если вы используете единый шлюз вроде RU LLM и меняете только base_url, сохраняя SDK, код и промпты, экономику все равно решает не интерфейс, а то, насколько точно каждая задача попадает в свою модель.
Из чего складывается счет
Операционные издержки ИИ-моделей редко равны цене за миллион токенов. Команда смотрит на прайс провайдера, а деньги уходят еще и на повторы, ручные проверки и поддержку всей схемы.
У любого сценария есть несколько слоев затрат: входные токены, выходные токены, повторные вызовы после ошибок, работа людей и режим нагрузки. Вход обычно считают хуже всего. На практике он часто дороже выхода. В чате растет история диалога. В поиске в запрос добавляют фрагменты документов. В суммаризации прилетает длинный текст. Иногда выгоднее сократить вход на 20%, чем менять модель.
Потом начинаются скрытые потери. Одна неудачная попытка из-за таймаута превращает один запрос в два или три. Если после ошибки система уходит на фолбэк, счет растет еще быстрее. В пиковые часы это особенно заметно: задержка выше, повторов больше, а днем у вас как раз основной трафик.
Отдельная статья расходов - люди. Кто-то проверяет спорные ответы, размечает ошибки, правит промпт и сверяет метрики после обновления модели. Если у вас парк моделей, сами вызовы могут быть дешевле, но промптов, тестов и мониторинга обычно больше. Если модель одна, сопровождение проще, зато вы платите за лишнюю мощность там, где хватило бы более дешевого варианта.
Ночные батчи считайте отдельно. Для классификации архива или суммаризации большого массива документов можно взять более медленную модель и срезать счет. Для онлайн-чата так не получится: там каждая лишняя секунда превращается в повторный запрос или жалобу.
Чат: когда одна модель удобна, а когда нет
В чате одна сильная модель часто выигрывает за счет простоты. Команда держит один набор промптов, один способ тестирования и меньше спорит о том, почему одинаковый вопрос в разных ветках попал в разные модели. Для сложного диалога это удобно: пользователь уточняет детали, меняет тему, просит сравнение, и сильная модель реже теряет нить разговора.
Но у чата есть неприятная особенность: цена растет вместе с историей. Если пользователь написал 15 сообщений, вы платите не только за новый ответ, но и за длинный контекст, который система снова читает. В поддержке, где половина обращений сводится к типовым вопросам вроде "где счет" или "как сменить тариф", большая модель быстро начинает стоить слишком много.
На таких сценариях малая модель часто дает ту же практическую пользу дешевле. Если ответ короткий, правила известны, а риск ошибки невысокий, переплачивать за запас интеллекта нет смысла. Разница по качеству бывает почти незаметной, а разница в счете видна уже через несколько дней.
Обычно лучше работает не выбор между крайностями, а простой фолбэк. Чат сначала идет в дешевую модель, а дорогая подключается только в понятных случаях:
- длинный диалог с несколькими условиями
- жалоба, где цена ошибки высока
- низкая уверенность в ответе
- просьба объяснить сложный процесс
Такой подход часто заметно режет средний чек без сильной просадки по качеству. Если 80% обращений закрывает малая модель, дорогая нужна только для трудных 20%.
Поиск: расходы прячутся не в ответе
В поиске деньги уходят не только на текст, который видит пользователь. До ответа система успевает посчитать эмбеддинги, найти похожие документы, отсеять слабые совпадения, переранжировать кандидатов и собрать контекст для модели. Если смотреть только на цену генерации, реальный счет почти всегда будет выше ожиданий.
Хороший пример - вопрос к базе знаний: "Как вернуть товар без чека?" Финальный ответ может занять 120 токенов. Но до него поиск уже обработал запрос эмбеддинг-моделью, просмотрел десятки фрагментов, прогнал верхние результаты через reranker и передал в модель ответа 1200-2000 токенов контекста. Часто именно эта подготовка и съедает заметную долю бюджета.
Обычно в расходах на поиск сидят четыре статьи: эмбеддинги для запросов и новых документов, хранение и обновление векторного индекса, переранжирование фрагментов и лишние токены в контексте. Одна большая модель на всю цепочку выглядит удобно, но на простых вопросах простаивает. Ей не нужна вся ее мощность, чтобы понять, что документ A ближе к запросу, чем документ B.
Поэтому набор из отдельных моделей часто обходится дешевле. Одна модель считает эмбеддинги, компактная делает reranking, а сильная генеративная модель подключается только на финальном шаге и только для сложных случаев. Дорогой ресурс включается реже, и это хорошо видно в счете.
Классификация: лишняя мощность быстро дорожает
Маршрут заявок, модерация контента и расстановка тегов обычно не требуют самой сильной модели. В этих задачах ответ короткий, вариантов немного, а правила понятны заранее. Если гонять весь поток через дорогую универсальную модель, команда платит за запас, который почти не нужен.
Разница быстро растет на объеме. Допустим, сервис обрабатывает 300 000 сообщений в месяц и для каждого просит модель выбрать один из 12 классов. Даже небольшая переплата за запрос превращается в заметную строку расходов. Для чата это еще можно терпеть. Для классификации такая схема часто слишком дорога.
Именно здесь особенно хорошо видно, что вопрос упирается не в "лучшую" модель, а в цену точности. Если дорогая модель дает прирост на доли процента, этот прирост нужно отдельно оправдать деньгами или риском ошибки.
Обычно поток лучше разделить. Очевидные случаи закрывают правила и словари, основной объем забирает недорогая модель, а сильная подключается только при низкой уверенности. Редкие спорные сообщения можно оставить на ручную проверку. Такая схема выглядит приземленно, зато обычно работает лучше любого "универсального" варианта.
Считать нужно не только цену запроса. Ошибка в маршрутизации заявки отправляет клиента не в ту очередь и добавляет, например, 10 минут ожидания. Ошибка модерации может пропустить рискованный текст или заблокировать нормальное сообщение. Сравнивайте цену всей цепочки с ценой ошибки, а не только тариф модели.
Суммаризация: платят за длину
В суммаризации бюджет чаще всего съедает не сам ответ, а длинный вход. Если вы просите модель пересказать 40 страниц отчета, часовой созвон или пачку писем, вы платите прежде всего за чтение. Поэтому одна и та же модель может казаться недорогой в чате и резко дорожать на документах.
Здесь выбор между одной моделью и парком моделей обычно зависит от длины и разброса входных данных. Когда документы короткие, похожи друг на друга и приходят редко, одна модель удобнее. Команде не нужно строить лишнюю логику, тестировать маршруты и следить за разным качеством на каждом шаге.
Но на потоке все меняется. Представьте поддержку, где за день накапливаются звонки, письма и внутренние заметки. Если каждый длинный текст сразу отправлять в дорогую модель, счет растет почти линейно с объемом текста. При этом качество далеко не всегда растет так же заметно, как расходы.
Часто дешевле работает каскад. Сначала более простая модель делает короткие выжимки по частям: по звонку, по письму, по разделу отчета. Потом вторая модель собирает финальное резюме из уже сжатого материала. Такой подход уменьшает вход в несколько раз и обычно дает более предсказуемый формат ответа.
Простой пример: 100 писем по клиентскому кейсу не обязательно скармливать целиком в одну модель. Сначала каждая цепочка писем сжимается до 5-7 строк, потом сильная модель делает итог на страницу. Разницу в цене вы обычно заметите раньше, чем разницу в качестве.
Когда одна модель лучше, а когда парк
Одна модель часто побеждает в самом начале. Команда быстрее запускает продукт, пишет меньше обвязки и держит в голове меньше правил. Тесты проще, обучение новых людей тоже: один набор лимитов, один стиль ответов, одна схема мониторинга.
Это особенно заметно, если поток небольшой, а задачи похожи друг на друга. Например, внутренний чат для сотрудников и короткую суммаризацию тикетов можно довольно долго вести на одной модели без лишней боли. Часть запросов будет решаться с запасом по мощности, но операционно это иногда все равно дешевле, чем постоянная настройка маршрутов.
С одной моделью легче жить и в системе оценок. У вас один набор тестов, одна история деградаций и меньше споров о том, какая версия сломала результат. Для команд, которым важны контроль и предсказуемость, это серьезный плюс.
Парк моделей начинает выигрывать, когда задачи заметно различаются по цене ошибки и по нужной мощности. Чат, поиск, классификация и суммаризация редко требуют одного и того же уровня качества. Если вы отправляете простую классификацию в ту же дорогую модель, что и сложный диалог с клиентом, счет растет очень быстро.
Типичная схема проста: дешевая модель разбирает короткие метки и простые правила, средняя делает суммаризацию и извлечение полей, сильная берет сложные диалоги, спорные случаи и длинный контекст. Но у парка есть своя цена. Нужно явно описать маршрутизацию, держать версии и следить за тем, чтобы дешевая модель не забирала слишком много сложных запросов. Ошибка в этих правилах быстро съедает экономию.
Если задачи похожи и команда мала, одна модель часто выигрывает. Если 60-80% трафика можно безопасно увести на более дешевые варианты, парк почти всегда окупается.
Как считать на своих данных
Не смотрите на средние цифры из чужих кейсов. Возьмите хотя бы неделю живых запросов по каждому сценарию: чат, поиск, классификация, суммаризация. Один день легко искажает картину, особенно если у вас есть пики по часам, длинные документы или сезонные темы.
Потом разделите поток на простые, средние и сложные случаи. Иначе дорогая модель для редких тяжелых запросов "размажется" по всей выборке, и вы решите, что она нужна везде. Уже на этом шаге обычно видно, какую часть задач можно отдать более дешевой модели без заметной потери качества.
Для каждой группы считайте одно и то же:
- входные и выходные токены на запрос
- среднюю задержку и задержку в длинном хвосте
- долю ошибок, отказов и ответов, которые человек потом исправляет
- время ручной доработки после ответа модели
- полную цену одного успешного результата в рублях
Ручную доработку лучше считать отдельно, а не "на глаз". Если сотрудник тратит 4 минуты на исправление плохой суммаризации, а его час стоит 1 200 рублей, такая правка обходится в 80 рублей. Часто это дороже, чем разница между двумя моделями.
После этого соберите две таблицы. В первой весь поток идет в одну модель. Во второй вы раскладываете задачи по ролям: простая классификация идет в дешевую модель, длинная суммаризация - в модель с большим контекстом, сложный чат - в более сильную. Тогда сравнение становится честным.
Если вы работаете через единый OpenAI-совместимый эндпоинт, такой тест проще провести без переписывания интеграции. Для команд в РФ это особенно удобно, когда нужно быстро сравнить несколько провайдеров и сохранить текущие SDK. В RU LLM на rullm.com для этого достаточно поменять base_url на api.rullm.com, а дальше сравнивать маршруты уже по реальным логам и стоимости успешного результата.
Где команды теряют деньги
Деньги обычно уходят не там, где их ждут. Команда смотрит на цену за миллион токенов и думает, что почти все уже посчитала. Но в счете сидят еще повторные запросы, длинный контекст, фолбэки и задачи, которые крутятся по расписанию без внимания к бюджету.
Самая частая ошибка проста: команда проверяет подход на десятке удачных примеров. Такие тесты почти всегда чище продакшена. В реальном трафике есть короткие реплики, пустые поля, шумный поиск, странные документы и запросы, где дорогая модель не дает заметной прибавки, а счет растет каждый день.
Еще один промах - отправлять весь поток в самую дорогую модель. Для сложного чата это иногда оправданно. Для классификации обращений, извлечения пары полей или короткой суммаризации это обычно лишние траты. Команда платит за запас мощности, который не использует.
С фолбэками ситуация еще хуже. Если включить резервную модель без порога качества и без лимита, любой таймаут или неудачный ответ запускает второй платный вызов. На бумаге надежность растет. По факту часть запросов обходится вдвое дороже, а команда даже не видит, какой процент трафика ушел в запасной сценарий.
Отдельно считайте ночные пакетные задачи. Именно там часто сгорает много токенов: переиндексация поиска, массовая классификация новых записей, суммаризация длинных документов, повторная обработка архивов после смены промпта. Если смотреть только на дневной чат, картина получится слишком приятной.
Короткая проверка перед решением
Решение часто ломается не на качестве ответа, а на рутине: кто следит за правилами, как быстро растет контекст и сколько денег уходит на редкие, но дорогие ошибки. Перед выбором полезно пройти короткую проверку и записать ответы в цифрах, а не в общих словах.
- Сравните требования к качеству по потокам. Для чата ошибка портит опыт, но для классификации заявок даже 1-2% промаха иногда бьют по SLA и ручной разборке.
- Отделите простые случаи заранее. Если половина запросов - это короткие FAQ, простая модель закроет их дешевле, а тяжелую можно оставить для спорных диалогов.
- Посмотрите на длину контекста за последние месяцы. Суммаризация, поиск по базе знаний и длинные переписки дорожают тихо, потому что токенов становится больше с каждым релизом продукта и каждой новой инструкцией.
- Оцените цену ошибки в каждом потоке. Неверный ответ в чате и неверная метка в антифроде стоят разных денег.
- Проверьте, есть ли у команды ресурс на маршрутизацию. Правила, A/B-тесты, мониторинг и откат маршрутов требуют времени. Если этим некому заниматься, парк моделей быстро превращается в набор исключений.
Небольшой пример: у поддержки есть чат, поиск по статьям и автотеги обращений. Если автотеги простые, их не стоит гонять через ту же дорогую модель, что и длинные диалоги с клиентом. Если по этим пунктам у вас пока нет чисел, соберите хотя бы неделю данных: длину запросов, долю простых случаев, цену ошибки и время команды на поддержку схемы. После этого выбор обычно становится заметно проще.
Пример для команды поддержки
Представим обычную поддержку: операторы отвечают в чате, система ищет статьи в базе знаний, новый тикет уходит в нужную очередь, а в конце смены менеджер получает короткую сводку. На старте хочется взять одну сильную модель на все. Так проще: один API, один формат промптов, меньше правил.
Но рутина быстро раздувает счет. Если дорогая модель стоит в 8-10 раз больше малой на тысячу токенов, переплата появляется не на сложных диалогах, а на самых частых действиях. Простая классификация темы тикета или ответ на вопрос вроде "где мой счет" не требуют той же мощности, что конфликтный чат или длинная сводка по инцидентам.
Условный день поддержки может выглядеть так:
- 8 000 чат-сообщений от клиентов
- 3 000 поисков по базе знаний
- 2 000 новых тикетов на раскладку по очередям
- 30 сводок по сменам и очередям
Если одна большая модель делает все, команда выигрывает в простоте, но платит премиальную цену даже за мелочь. Особенно заметно это на классификации и коротких ответах. Там токенов мало, зато запросов много, и сумма за месяц набегает тихо.
Парк моделей обычно выглядит практичнее. Малая модель ведет большую часть чатов и извлекает намерение клиента. Отдельная модель для поиска или ранжирования выбирает фрагменты из базы знаний. Дешевый классификатор раскладывает тикеты. Дорогая модель включается как фолбэк, когда клиент злится, вопрос нетипичный или ответ из базы противоречив.
В такой схеме средняя цена запроса падает, а качество на сложных случаях не проседает. Для поддержки это часто самый трезвый вариант: одна модель удобна для пилота, парк выгоднее в продакшене, когда поток однотипных задач уже стабилен.
Что делать дальше
Начните не с большой схемы, а с одного живого сценария. Возьмите чат поддержки или суммаризацию обращений и замерьте три вещи: цену одного запроса, долю удачных ответов и время команды на поддержку этой схемы. Уже на этом шаге обычно видно, где вы платите за лишнюю мощность, а где экономия ломает качество.
Фолбэк добавляйте только там, где просадка заметна в цифрах. Если базовая модель нормально закрывает 92% запросов в классификации, не стоит сразу строить сложный маршрут на весь трафик. Чаще всего хватает простого правила: дешевая модель идет первой, более сильная включается только для спорных случаев, длинных текстов или низкой уверенности.
Чтобы схема не расползалась, полезно держать в одном месте правила маршрутизации, версии промптов, пороги фолбэка и даты изменений с их результатом. Тогда проще понять, почему счет вырос на 18% или почему качество просело после замены модели.
Смотрите не на "модную" схему, а на общий итог. Если одна модель дает чуть хуже ответ, но экономит часы команды и держит бюджет в рамках плана, это нормальный выбор. Если парк моделей дает прирост только в одном сценарии, ограничьте его этим сценарием, а не тяните на всю систему.
Часто задаваемые вопросы
Когда лучше оставить одну модель на все задачи?
Одна модель обычно выгодна на старте, когда поток небольшой, а задачи похожи друг на друга. Вы быстрее запускаете продукт, держите меньше правил и тратите меньше времени на поддержку. Если разница в цене не съедает бюджет, простота часто окупает лишние токены.
В какой момент парк моделей начинает экономить деньги?
Парк моделей окупается, когда у вас много простых запросов и малая часть реально сложных. Тогда дешевую модель можно пустить на рутину, а дорогую включать только там, где ошибка стоит дорого или нужен длинный контекст. Чаще всего это заметно в поддержке, поиске и массовой классификации.
Как правильно считать цену успешного результата?
Считайте не тариф за токены, а цену одного нормального ответа. В эту сумму включайте входные и выходные токены, повторы после ошибок, фолбэки, ручные правки и время команды на поддержку схемы. Если сотрудник потом тратит минуты на исправление ответа, это тоже часть счета.
Нужен ли фолбэк в чате?
Не всегда. Фолбэк полезен там, где базовая модель часто ошибается на сложных диалогах или длинной истории. Если включить его без порога и контроля, любой таймаут превратит один запрос в два платных вызова и быстро раздует счет.
Почему поиск часто стоит дороже, чем кажется по прайсу модели?
В поиске деньги уходят не только на финальный ответ. Система еще считает эмбеддинги, ищет фрагменты, ранжирует результаты и передает в модель длинный контекст. Часто именно подготовка съедает заметную часть бюджета, даже если ответ для пользователя короткий.
Что сильнее всего влияет на цену суммаризации?
Чаще всего счет раздувает длинный вход. Модель читает отчет, переписку или созвон целиком, и вы платите именно за это чтение. Поэтому суммаризацию обычно выгодно делать в два шага: сначала сжимать части, потом собирать общий итог.
Как понять, что для классификации дорогая модель не нужна?
Смотрите на цену прироста точности, а не на слово "лучше" в описании модели. Если дорогая модель дает почти тот же результат, что дешевая, на потоке переплата быстро становится заметной. Для маршрутизации, тегов и модерации это особенно частая ошибка.
Сколько данных нужно, чтобы честно сравнить одну модель и парк?
Обычно хватает недели живого трафика по каждому сценарию. За это время вы увидите пики, длинные хвосты по задержке, реальные ошибки и долю простых случаев. Тест на десяти удачных примерах почти всегда рисует слишком приятную картину.
Что важно учесть российской команде при работе с логами и PII?
Если у вас есть чувствительные данные, считайте не только модель, но и всю обработку вокруг нее. Нужно заранее проверить, где хранятся логи, как вы маскируете PII и кто потом смотрит аудит запросов. Иначе дешевая схема на бумаге обернется лишней работой и риском для команды.
С чего начать, если не хочется переделывать всю интеграцию?
Начните с одного живого потока, а не со всей системы сразу. Возьмите чат поддержки или суммаризацию, сравните одну модель с простым маршрутом и замерьте цену, качество и ручную доработку. Если вы уже работаете через OpenAI-совместимый эндпоинт, такой тест можно провести без переписывания SDK и основного кода.