Обновление эмбеддингов при смене модели без просадки поиска
Обновление эмбеддингов без провала качества поиска: как замерить базу, переиндексировать поэтапно и уйти от двойного хранения данных.
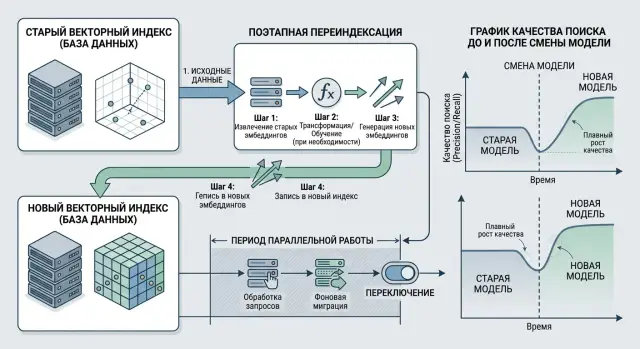
Где ломается поиск после смены модели
Самая частая ошибка при обновлении эмбеддингов проста: команда меняет модель и оставляет индекс смешанным "на время". Так не работает. Старые и новые векторы живут в разных пространствах, и сравнивать их напрямую нельзя, даже если размерность совпадает. Запрос, закодированный новой моделью, начинает странно ранжировать документы, которые были закодированы старой.
Снаружи это редко выглядит как явная поломка. Поиск все еще что-то находит, но верх выдачи уже шумит: вместо точного ответа всплывает общий обзор, старая инструкция или документ с похожими словами, но с другим смыслом. В базе знаний поддержки это особенно заметно на коротких запросах вроде "401 токен", "лимит запросов" или "счет в рублях".
Даже если вы не смешиваете векторы в одном индексе, старые пороги похожести все равно перестают работать как раньше. Значение cosine similarity само по себе ничего не гарантирует. Для одной модели 0.82 может быть сильным совпадением, для другой - обычным шумом. Команда оставляет прежний threshold, rerank cutoff или правила отбора кандидатов и получает либо слишком много мусора, либо пустую выдачу там, где раньше был уверенный матч.
Обычно проблема выглядит так:
- знакомые запросы меняют топ результатов без явной причины;
- статьи с шаблонным текстом поднимаются выше точных ответов;
- редкие термины, коды ошибок и смешанные RU/EN запросы ищутся хуже;
- средние метрики выглядят терпимо, а пользователи уже жалуются.
Есть и более неприятный сценарий. На тестовом наборе все спокойно, потому что он маленький и "чистый". В живом трафике приходят короткие фразы, опечатки, внутренние названия и старые формулировки из тикетов. Именно там смена модели сильнее всего сдвигает релевантность.
Если вы переключаете модель через совместимый API-шлюз вроде RU LLM, смена маршрута в коде может занять минуты. Но сам поиск от этого не становится совместимым автоматически. Индекс, пороги и набор контрольных запросов все равно нужно проверять отдельно.
Обычно сбой замечают поздно. Не мониторинг, а поддержка или клиенты пишут: "раньше нужная статья находилась с первого запроса, теперь надо листать". В этот момент проблема уже не в новой модели как таковой, а в том, что логика поиска осталась привязана к старому распределению векторов.
Что замерить до первой переиндексации
До первой переиндексации важно зафиксировать не "среднее качество модели", а текущее поведение поиска на живых данных. Иначе после смены модели вы увидите просадку, но не поймете, где именно она появилась: в самих векторах, в чанкинге, в фильтрах или в ранжировании.
Первая ошибка тут очень типовая: команда берет десять придуманных запросов вроде "как сбросить пароль" и считает, что этого хватит. Не хватит. Нужны реальные запросы из логов хотя бы за 2-4 недели. В них уже есть опечатки, короткие формулировки, внутренний жаргон и смешанные запросы. Именно они потом и ломают качество поиска.
Если запросы идут через шлюз с аудит-трейлами, как RU LLM, такую выборку проще собрать без ручной склейки из нескольких систем. Но и обычных логов поиска достаточно, если в них есть текст запроса, фильтры и данные о том, что пользователь открыл после выдачи.
Дальше нужна рабочая разметка. Не надо сразу размечать тысячи примеров. Возьмите несколько сотен запросов и для каждого отметьте хотя бы один правильный документ. Лучше два или три, если задача допускает несколько хороших ответов. Без этого обсуждение быстро скатывается в спор по ощущениям.
Полезно заранее зафиксировать несколько показателей:
- recall@k или hit rate@k;
- MRR или nDCG, если порядок документов действительно важен;
- долю пустых ответов;
- долю запросов, где пользователь открывает документ из top-k;
- среднюю и p95 задержку поиска.
Считайте их на одной и той же выборке до любых изменений. Иначе сравнение получится грязным.
Отдельно посмотрите на операционные параметры: сколько весит текущий индекс, сколько часов занимает полная сборка, сколько стоит хранить старый и новый индекс параллельно, сколько трафика и CPU съедает переиндексация. На практике именно эти числа часто решают, можно ли уложиться в выходные или миграцию придется растянуть.
Еще один полезный срез - разбивка по типам запросов. Короткие запросы из двух слов, длинные вопросы, запросы с кодами ошибок, запросы с названиями продуктов. Новая модель может поднять среднюю метрику и при этом испортить один важный класс. Для базы знаний поддержки это быстро превращается в жалобы операторов и лишнюю ручную работу.
Когда у вас есть реальная выборка, разметка, метрики качества и цифры по индексу, вы уже оцениваете не абстрактную "новую модель", а цену перехода и его риск.
Как выбрать схему перехода
Схема перехода зависит не столько от модели, сколько от размера коллекции, доли "живых" документов и того, сколько времени поиск может работать в смешанном режиме. Если у вас 200 тысяч коротких документов и есть ночное окно на обслуживание, полная переиндексация обычно проще и дешевле. Команда один раз считает новые векторы, меняет индекс и быстро получает чистую картину без лишней логики в рантайме.
Другая ситуация начинается на десятках миллионов записей или при частых обновлениях базы. Тогда разумнее переносить данные частями. Такой подход меньше нагружает GPU, очередь задач и векторное хранилище. Ошибок тоже обычно меньше: проще проверить один сегмент, чем переписать весь поиск за раз.
Сегменты чаще всего делят по приоритету. Сначала идут документы, которые чаще всего участвуют в поиске. Затем свежие записи, где ошибка заметнее всего. Архив и редко используемые коллекции переносят в конце. Длинные PDF, таблицы и другой сложный контент лучше вынести в отдельный этап.
Горячие данные почти всегда стоит переносить раньше архива. На практике 10-20% документов дают большую часть поискового трафика. Если обновить их первыми, вы быстрее увидите реальную разницу в релевантности и не потратите недели на старый архив, по которому почти никто не ищет.
Два индекса полезны, но только как временная страховка. Держать старый и новый индекс кварталами дорого и вредно: растут расходы, путаются метрики, а команда все откладывает окончательное переключение. Лучше заранее назначить короткий срок проверки, например 7-14 дней, и зафиксировать условия отключения старой версии: порог по качеству, стабильность задержки и отсутствие критичных жалоб.
Для большинства команд выбор сводится к трем вопросам: сколько документов надо пересчитать, какие из них реально влияют на пользовательские запросы и сколько дней вы готовы платить за второй индекс. Если объем небольшой и есть простое окно работ, берите полную переиндексацию. Если объем большой, а поиск нельзя останавливать, делайте поэтапный перенос и завершайте его быстро. Смена модели редко ломается из-за самой модели. Гораздо чаще проблема в затянувшемся переходе, когда старые и новые векторы слишком долго живут рядом.
Пошаговый план миграции
Самый чистый переход начинается не с новой модели, а с фиксации базы для сравнения. Возьмите одну версию документов, один пайплайн очистки текста и один способ чанкинга. Если вы одновременно меняете и модель, и разбиение текста, потом уже нельзя понять, что именно испортило качество.
План на практике
Сначала соберите честное сравнение. Потом дайте новой схеме реальный трафик. И только после этого убирайте старые данные.
- Соберите теневой индекс на той же выборке документов, которая уже участвует в поиске. Не подтягивайте новые статьи, не меняйте overlap и не трогайте правила удаления дублей до конца теста.
- Возьмите один и тот же набор запросов для старого и нового индекса. Включите частые запросы, редкие формулировки и фразы с шумом из живого трафика. Смотрите не только на среднюю метрику, но и на состав top-k по каждому запросу.
- Разберите руками случаи, где новый индекс дал заметно другой результат. Часто проблема не в модели, а в слишком мелких чанках, служебном тексте, повторах или плохих заголовках. Пятьдесят таких запросов обычно дают больше пользы, чем одна красивая цифра в отчете.
- Переключайте трафик частями, а не одним релизом. Начните с малого процента и поднимайте долю, если поиск держится стабильно. Смотрите на пустые ответы, задержку, ошибки в пайплайне и жалобы из поддержки, а не только на офлайн-метрики.
- Заранее задайте порог, после которого старый индекс больше не нужен. Обычно это нормальная релевантность на контрольном наборе, отсутствие всплеска пустых результатов и несколько дней спокойной работы под частью боевого трафика. Как только порог пройден, удаляйте старые векторы сразу.
Частая ошибка при смене модели - держать оба индекса "на всякий случай" и откладывать решение. Если сравнение было честным, а новый индекс прошел порог, старые векторы только съедают бюджет и усложняют поддержку.
Как сократить срок двойного хранения
Дольше всего при миграции живет не переиндексация, а привычка хранить две полные копии базы "на всякий случай". В большинстве случаев это лишнее. Тексты, ID документов и служебные поля лучше хранить в одном месте, а временно дублировать только векторы для той части коллекции, которую вы переносите прямо сейчас.
Так вы не платите месяцами за два одинаковых набора документов и не путаетесь, какая копия рабочая. Для обновления эмбеддингов это один из самых простых способов сократить расходы без заметного риска.
Хорошо работает перенос партиями. Не по алфавиту и не по принципу "как выгрузилось", а по приоритету трафика. Если у вас база знаний поддержки, сначала переиндексируйте разделы, которые дают больше всего поисковых запросов: ошибки входа, оплата, доставка, возвраты. Именно там пользователи быстрее всего замечают разницу.
Как резать миграцию на партии
Обычно хватает такой очередности:
- разделы с самым частым поиском;
- коллекции, где больше всего жалоб на нерелевантность;
- длинный хвост редко используемых документов;
- архив и справка с низким трафиком.
После каждой партии не идите дальше автоматически. Сначала проверьте метрики и несколько живых сценариев руками. Если новая модель не просадила качество, старые шарды для этой партии лучше удалить сразу, а не откладывать "до конца проекта". Иначе временное хранилище быстро становится постоянным.
Еще одна полезная мелочь: версию эмбеддингов храните в метаданных документа, а не в названии таблицы или индекса. Поле вроде embedding_version=2025_05 проще для фильтров, выборочных прогонов и отката. Таблицы вида kb_v1_final_new2 почти всегда заканчиваются путаницей.
Если вы работаете через единый шлюз, например RU LLM, приложение не нужно заново перестраивать под новые маршруты модели. Это не отменяет миграцию индекса, но упрощает саму смену модели и тесты через один OpenAI-совместимый эндпоинт.
Нормальный ориентир простой: двойное хранение должно жить днями или неделями, но не кварталами. Если оно затянулось, проблема обычно не в размере индекса, а в том, что партии слишком большие и старые данные никто не удаляет сразу после проверки.
Пример на базе знаний поддержки
У службы поддержки есть база знаний на 200 тысяч статей. Полная переиндексация в один день красиво выглядит только на схеме. На практике она часто бьет по поиску: часть запросов начинает лучше понимать новый смысл, а часть внезапно теряет точные совпадения.
Проблема в неравномерном трафике. Большая часть запросов крутится вокруг 15 тысяч популярных материалов: FAQ, инструкции по частым ошибкам, статьи про оплату, доступы и настройки. Если начать с них, команда проверит самое важное раньше и не будет месяцами держать два полных набора векторов.
Первая волна документов обычно включает FAQ и короткие ответы операторов, свежие статьи, материалы с самым частым поисковым трафиком и документы, которые операторы часто открывают вручную.
Новые эмбеддинги считают только для этой части базы и кладут в отдельный индекс. Поиск сначала идет в новый индекс по популярным и свежим материалам. Если уверенного совпадения нет, система обращается к старому индексу, где пока лежит архив. Такой вариант дает заметный эффект сразу, а объем двойного хранения остается разумным.
Дальше команда смотрит не только на метрики. Операторы поддержки вручную проверяют спорные запросы: короткие фразы, опечатки, внутренние сокращения, старые названия функций. Именно на них видно, понимает ли новая модель рабочий язык компании или просто выдает семантически близкий, но бесполезный текст.
Проверка простая: оператор берет реальный запрос клиента и сравнивает первые три результата старой и новой модели. Если новая версия чаще поднимает точную инструкцию, а не общую статью, ее оставляют. Если она путает похожие темы, запрос или документ попадает в список на доработку.
Через неделю такой сверки старая модель уже не нужна для активной части базы. Ее оставляют только для архива: старых релизных заметок, устаревших интеграций и редких кейсов. В итоге основная выдача работает на новой модели, архив не пропадает, а команда не платит за двойное хранение всей коллекции еще несколько месяцев.
Ошибки, которые портят релевантность
Самая дорогая ошибка при обновлении эмбеддингов - менять модель и одновременно менять разбиение текста. После такого эксперимента уже нельзя понять, что именно испортило поиск. Новая модель могла дать более точные векторы, а новый размер чанка - потерять нужный контекст. Или наоборот. Если хотите чистое сравнение, сначала оставьте старое разбиение и замените только модель.
Вторая частая проблема - тест на десятке "удобных" запросов. Обычно это длинные, понятные формулировки, которые команда сама использует в демо. Они редко похожи на живой трафик. Настоящие запросы часто короткие, с ошибками и без контекста: "Иванов", "акт март", "лимит 2024", "тариф старт". На таких фразах просадка видна быстрее всего.
Старые пороги похожести тоже нельзя переносить как есть. У новой модели меняется распределение расстояний между векторами. Порог, который раньше отсекал шум, теперь может выкидывать хорошие совпадения. Или, наоборот, пропускать слишком много мусора в top-k. После смены модели нужно заново калибровать не только similarity threshold, но и число кандидатов, которые вы отдаете в ранжирование или в контекст LLM.
Самый опасный shortcut - смешать в одном индексе векторы от разных моделей. Даже если размерность совпадает, пространство у них все равно разное. Для ANN-индекса это не "почти одно и то же", а две разные системы координат. В итоге соседями становятся документы, которые вообще не должны стоять рядом. Если вы тестируете через единый OpenAI-совместимый контур, например через RU LLM, проще держать отдельные индексы или хотя бы жестко разделять версии модели в маршрутизации запросов.
Что ломается первым
Отдельной выборкой лучше проверить случаи, которые команда часто забывает:
- одно- и двухсловные запросы;
- фамилии, имена и названия продуктов;
- даты, номера договоров и версии документов;
- короткие служебные формулировки из поддержки;
- запросы, где важна одна точная сущность, а не общий смысл.
Если новая модель выигрывает только на длинных описательных запросах, а на именах и датах начинает ошибаться, это уже регресс. Для базы знаний поддержки такой сдвиг быстро бьет по качеству: сотрудник видит "похожую" статью вместо нужной и тратит лишние минуты на ручной поиск.
Короткий список проверок перед релизом
Перед запуском новой модели обычно ломаются не средние метрики, а мелкие рабочие сценарии. Один и тот же запрос вдруг начинает прыгать по выдаче, фильтр по доступу режет нужные документы, а свежая статья поддержки появляется в поиске через час, когда она нужна сразу.
Перед релизом полезно пройти короткий набор проверок и зафиксировать результат в одном документе. Часто этого достаточно лучше, чем длинного отчета с красивыми графиками.
- Прогоните один и тот же набор запросов несколько раз подряд и сравните верх выдачи. Небольшие перестановки на 8-10 местах не страшны. Если меняется топ-3, пользователи заметят это сразу.
- Проверьте фильтры отдельно от similarity. Возьмите запросы с ограничением по дате, типу документа и правам доступа. Ищите не только пропуски, но и обратную ошибку, когда система показывает документ тому, кто не должен его видеть.
- Добавьте в индекс несколько новых документов и замерьте фактическую задержку до появления в поиске. Лучше делать это на реальных пайплайнах, а не на тестовой очереди.
- Отрепетируйте откат. Команда должна знать, кто переключает трафик, где лежит старая конфигурация и сколько минут занимает возврат на прошлую модель. Если этот путь не проверяли руками, его почти нет.
- Зафиксируйте правило удаления старого индекса. Например: удаляем старую версию после 7 дней без откатов и после контрольной выборки из 100 запросов.
Отдельно проверьте смешанные сценарии, где старые и новые векторы короткое время живут рядом. Именно там часто всплывает тихая проблема: документы уже переиндексировали, а ранжирование или фильтры все еще смотрят на старую схему.
Хороший признак перед релизом простой: инженер может за пять минут объяснить, что увидит пользователь, как быстро новый документ попадет в поиск и как команда вернется назад, если релевантность просядет вечером после выката.
Что сделать после запуска
После релиза смотрите не на сам факт успешной переиндексации, а на поведение пользователей. Миграцию можно считать удачной только тогда, когда поиск чаще приводит к нужному документу, а команда реже вмешивается вручную. Если клики просели, операторы чаще исправляют ответы, а сложные случаи уходят на эскалацию, проблема уже в проде, даже если офлайн-метрики выглядели хорошо.
В первые дни держите перед глазами три сигнала:
- долю кликов по первым результатам;
- число ручных исправлений после выдачи поиска;
- долю эскалаций в поддержку или на вторую линию.
Смотреть на них лучше по сценариям, а не только в среднем. Один провал в поиске по тарифам легко теряется в общей статистике, но заметно бьет по поддержке и продажам.
Раз в неделю пересматривайте плохие запросы из логов. Берите не только частотные фразы, но и дорогие для бизнеса случаи. Редкий запрос вроде "условия перевыпуска карты для зарплатного проекта" может быть важнее сотни простых навигационных запросов. Для каждого такого кейса полезно сравнить старый и новый топ результатов и коротко записать причину сбоя: плохой чанк, устаревший документ, слабая модель или ошибка в фильтрах.
Не меняйте одновременно эмбеддинги, ранжирование и промпты. Иначе через неделю никто не скажет, что именно помогло, а что сломало поиск. После запуска лучше заморозить остальные части пайплайна хотя бы на одну-две недели и вносить правки по одной.
Если данные и логи должны оставаться в РФ, контур оценки новой модели нужно проверить заранее и после запуска не выносить разбор в сторонние системы. Иначе команда либо теряет доступ к реальным запросам для проверки, либо нарушает внутренние правила. Для банков, телекома и госсектора это обычное ограничение, а не формальность.
Когда нужно быстро перепроверить гипотезу, удобно прогнать одну и ту же выборку на нескольких моделях без переделки интеграции. В RU LLM для этого можно использовать единый OpenAI-совместимый эндпоинт и не менять SDK во время тестов. Это экономит время: команда быстрее понимает, проблема в модели, в индексе или в данных.
Если через две-три недели метрики держатся ровно, плохих запросов становится меньше, а ручных правок не прибавилось, старые векторы можно убирать из плана отката и закрывать миграцию.
Часто задаваемые вопросы
Можно ли смешивать старые и новые эмбеддинги в одном индексе?
Нет. Старые и новые векторы нельзя держать в одном индексе, даже если размерность совпадает. Запросы начнут ранжировать документы странно, и шум полезет в верх выдачи.
Нужно ли заново настраивать пороги похожести после смены модели?
Да, почти всегда нужно. После смены модели меняется распределение расстояний, поэтому старый similarity threshold, top-k и rerank cutoff часто дают либо мусор, либо пустую выдачу.
Что нужно замерить до первой переиндексации?
Берите живые запросы из логов хотя бы за несколько недель, а не придуманные примеры. Затем размечайте несколько сотен запросов, фиксируйте hit rate или recall, долю пустых ответов, клики по top-k и задержку.
Когда лучше делать полную переиндексацию, а не переносить данные частями?
Полная переиндексация подходит, когда коллекция не очень большая и у команды есть окно на работы. В таком случае вы быстрее получаете чистый индекс и не тащите лишнюю логику в рантайм.
В каких случаях лучше переносить индекс по частям?
Переход по партиям нужен, когда документов много, база часто меняется или поиск нельзя останавливать. Так команда проверяет качество на сегментах и не перегружает хранилище и очередь задач одним большим прогоном.
Какие документы переносить первыми при поэтапной миграции?
Начинайте с горячих документов: популярных статей, свежих материалов и разделов, по которым чаще всего ищут. Обычно именно они дают основную часть трафика, поэтому вы раньше увидите реальный эффект.
Можно ли одновременно менять модель эмбеддингов и чанкинг?
Не стоит. Если вы сразу меняете и модель, и разбиение текста, потом уже нельзя понять, что именно испортило поиск. Сначала замените модель на старом чанкинге, а новые размеры чанков проверяйте отдельно.
Как понять после релиза, что новая модель действительно улучшила поиск?
Смотрите не только на офлайн-метрики. Если пользователи чаще открывают первый результат, операторы реже правят ответы вручную, а эскалаций не стало больше, переход идет нормально.
Когда можно удалять старый индекс и старые векторы?
Удаляйте его сразу после честной проверки, а не держите месяцами про запас. Часто хватает 7–14 дней стабильной работы без откатов, нормальной релевантности на контрольной выборке и без заметных жалоб.
Если я переключаю модель через RU LLM, нужно ли менять код поиска?
Нет, приложение обычно не нужно переписывать: вы можете сменить маршрут модели через тот же OpenAI-совместимый эндпоинт. Но сам поиск это не спасает — индекс, пороги и контрольные запросы все равно надо проверить отдельно.