MIG или отдельные GPU-пулы: где меньше конфликтов
Разбираем MIG или отдельные GPU-пулы: как выбрать схему под инференс, обучение и batch-задачи, чтобы не терять загрузку и не ловить шум соседей.
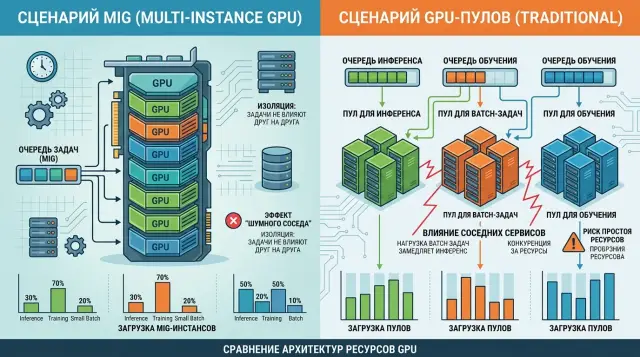
Почему выбор между MIG и пулами быстро упирается в конфликты
Проблема обычно начинается не с нехватки GPU, а с того, что на одной карте живут сервисы с разным ритмом. Один отвечает пользователю за сотни миллисекунд, другой гонит длинный batch по несколько минут. На графике средняя загрузка может выглядеть спокойно, но пользователи уже видят рывки по задержке.
Такой конфликт легко пропустить. Команда смотрит на среднюю загрузку 50-60% и думает, что запас есть. Но среднее значение скрывает хвосты: обычно ответ идет за 300 мс, а когда рядом стартует тяжелая задача, тот же запрос внезапно ждет 2-3 секунды.
Чаще всего страдают короткие онлайн-запросы. Им нужен предсказуемый доступ к вычислениям и памяти, а длинный batch держит карту занятой дольше и неровнее. Даже если памяти формально хватает всем, сосед все равно может забить пропускную способность памяти, очереди запуска и время вычислительных блоков.
Это особенно заметно в LLM-инференсе, где рядом часто живут чат, эмбеддинги, reranking и ночные пакетные прогоны. Для чата важен ровный отклик. Для batch-задачи важнее общая пропускная способность. Когда их смешивают без жестких границ, одна прожорливая нагрузка портит картину для всей команды.
Обычно это выглядит так:
- средняя загрузка GPU нормальная, но p95 и p99 скачут
- жалобы приходят не постоянно, а в определенные часы или после запуска batch-задач
- autoscaling почти не помогает, потому что источник проблемы сидит внутри общей карты
- одна команда думает, что все в порядке, пока другая не включает тяжелый сценарий
Из-за этого выбор "MIG или отдельные GPU-пулы" быстро перестает быть вопросом удобства. Это уже вопрос радиуса повреждения: насколько сильно один сервис может мешать соседу и как дорого вам обходится этот шум. Если у вас единый OpenAI-совместимый слой, как в RU LLM, и через него идут разные типы запросов к моделям, такие конфликты всплывают очень рано. Тогда и приходится решать, что для вас хуже: потерять часть загрузки GPU или потерять предсказуемость сервиса.
Что MIG решает хорошо
MIG полезен там, где одна большая GPU-карта кормит несколько сервисов, а команде нужны понятные границы. Технология делит карту на фиксированные части, и каждая часть получает свой кусок памяти и вычислений. За счет этого соседний сервис уже не так легко "съедает" ресурсы в неожиданный момент.
На практике это сразу снижает классическую проблему noisy neighbor. Один сервис может внезапно поднять batch size, другой - прогреть новую модель, третий - получить всплеск запросов. Без разделения они начинают мешать друг другу. С MIG поведение становится ровнее: если инстансу дали определенный профиль, он не вылезет за него и не продавит соседей по памяти.
Это особенно удобно для команд, которые хотят закрепить квоты не на словах, а на уровне железа. Например, прод-окружению можно отдать один профиль, тестовому - другой, а отдельной команде оставить небольшой инстанс под фоновые задачи. Споров меньше, потому что лимиты видны сразу и их трудно обойти случайно.
MIG обычно подходит, если несколько сервисов постоянно живут на одной карте, нагрузка более или менее известна заранее, для каждого сервиса нужен свой потолок по памяти, а простой учет квот важнее редких пиков производительности.
Для LLM-инференса это часто удобно на стабильных маршрутах. Скажем, один сервис всегда гоняет короткие классификационные запросы, а другой отвечает за embeddings. Если посадить их в разные MIG-инстансы, планирование становится проще: команда знает, сколько памяти есть у каждого сервиса, и быстрее понимает, где искать причину просадки.
В споре "MIG или отдельные GPU-пулы" у MIG сильная сторона одна и очень практичная: предсказуемость. Она нужна не только SRE, но и финансам, и владельцам сервисов. Проще считать емкость, проще обещать SLA внутри компании, проще объяснить, почему тестовый контур не должен отбирать ресурс у продакшена.
Минус тоже прямой. Гибкость падает. Если профиль инстанса не подходит задаче, карта может простаивать кусками, а сервис все равно упрется в свой лимит. MIG хорошо режет конфликты, но плохо подстраивается под неровную нагрузку.
Когда отдельные GPU-пулы удобнее
Отдельные GPU-пулы удобнее там, где задачи живут в разном ритме. Онлайн-инференс просит короткий и ровный ответ. Batch-задачи хотят забрать как можно больше ресурса на часы. Обучение и fine-tune вообще не любят, когда их прерывают посреди длинного прогона.
В такой схеме команда не пытается уместить все в одну общую GPU-среду. Она сразу разводит нагрузки по разным пулам: один для прод-инференса, второй для ночных batch-задач, третий для обучения. Это проще не только для планировщика, но и для людей, которые дежурят и выпускают обновления.
Если спор идет в формате "MIG или отдельные GPU-пулы", пулы часто выигрывают при сильной разнице между задачами. MIG хорошо режет карту на части, но не отменяет того факта, что у соседей разные цели. Одному сервису нужна низкая задержка, другому - максимальная загрузка GPU, третьему - вся память карты целиком.
Отдельный пул обычно лучше, если онлайн-сервис нельзя тормозить даже короткими batch-пиками, модель растет и ей уже тесно в фиксированном профиле GPU, обучение идет часами и команде нужен полный контроль над узлом, а разные команды выпускают обновления в разное время.
Еще один плюс - разные окна перезапусков. Если команда обучения обновляет драйверы или библиотеку раз в неделю, это не должно цеплять прод-инференс. И наоборот: если прод-команда катает частые релизы, batch-пул может жить по своему графику без лишней суеты.
Аварии тоже проще локализовать. Сломался рантайм в пуле для fine-tune - прод не трогаете. Batch-задача забила очередь или съела память - чат-бот и поиск продолжают отвечать. Для эксплуатации это обычно важнее, чем лишние проценты утилизации на бумаге.
Пулы дают и больше свободы по железу. Под большую open-weight модель можно держать карты с большим объемом памяти, а под легкий инференс - другой тип GPU. Не нужно подгонять все задачи под один профиль нарезки.
Такой подход часто выбирают и в гибридной схеме: часть запросов команда ведет через RU LLM как единый API-шлюз, а свои тяжелые или чувствительные задачи держит на отдельных пулах в российских ЦОДах. Это удобно, когда прод-трафик, batch и внутреннее обучение нельзя смешивать ни по рискам, ни по режиму работы.
Как выбрать схему шаг за шагом
Если на одной группе GPU живут чат, ночные batch-задачи и обучение, конфликт почти неизбежен. Чат просит ровную задержку, batch терпит очередь, а обучение любит занять карту надолго. Поэтому сначала делите нагрузки не по командам, а по типу работы.
Например, у вас есть чат поддержки, пересчет эмбеддингов ночью и редкое дообучение модели. Для чата плох даже короткий всплеск задержки. Пересчет эмбеддингов может подождать. Дообучение проще вообще не ставить рядом с продом.
Схему удобно выбирать по пяти шагам.
- Для каждой задачи запишите два числа: сколько задержки она терпит и сколько простоя допустимо. Если ответ пользователю должен прийти меньше чем за секунду, а batch-джоба может ждать 15 минут, выбор уже сильно сужается. MIG чаще подходит там, где нужен жесткий раздел памяти и предсказуемое поведение. Отдельные GPU-пулы чаще берут там, где задача должна забирать карту целиком.
- Затем проверьте, во что вы упираетесь раньше. Если сервис ловит OOM, смотрите на память. Если GPU долго висит под 95-100% при свободной памяти, вас держит compute. Если карты не забиты, а запросы стоят в очереди, проблема, скорее всего, в батчинге, маршрутизации или лимитах на параллельность.
- Прогоните пилот в двух режимах: обычный трафик и пик. На спокойной нагрузке MIG и отдельные GPU-пулы часто выглядят одинаково. Разница видна, когда соседний сервис резко увеличивает длину контекста, переключается на более тяжелую модель или запускает batch рядом с онлайном.
- Сравнивайте не только среднее. Смотрите 95-й и 99-й перцентили по задержке, длину очереди, долю OOM, число отмененных запросов и время до первого токена. Среднее легко прячет проблему, которая бьет по каждому сотому запросу.
- После пилота зафиксируйте правило размещения. Онлайн-инференс с жестким SLA можно держать в MIG. Ночной batch часто проще вынести в отдельный пул. Обучение лучше не селить рядом с продом, если у вас нет большого запаса по картам.
Обычно спор решает не теория, а одна неделя замеров. Если MIG держит p99 без всплесков и не режет полезную загрузку, дробление GPU оправдано. Если хвосты растут, а соседние сервисы мешают друг другу даже при нормальном среднем, отдельные пулы дадут более спокойную эксплуатацию.
Простой пример для одной команды
Представим одну команду с тремя разными нагрузками на одном кластере. Днем у нее работает чат-сервис с короткими ответами. Пользователь задал вопрос, нажал Enter и ждет ответ почти сразу. Если задержка прыгает даже на пару секунд, сервис уже кажется "тормозным".
Ночью эта же команда запускает пакетную обработку документов. Там другая логика: никто не следит за каждой секундой, зато задания идут долго, размер текста гуляет, а потребление памяти скачет сильнее. Раз в неделю инженеры еще и запускают дообучение модели на новых данных.
Если все это посадить на общий набор GPU без жесткого разделения, конфликт почти гарантирован. Ночная пачка может не успеть закончиться к утру. Дообучение может занять память на несколько часов. В итоге чат живет рядом с тяжелыми задачами и получает хвосты по задержке, просадки по throughput и редкие, но очень неприятные OOM.
В таком примере MIG обычно хорошо решает именно дневную онлайн-нагрузку. Команда может выделить под чат отдельный MIG-инстанс с фиксированным объемом памяти и понятным лимитом по вычислениям. Это не делает сервис быстрее само по себе, но делает его ровнее. Соседняя задача уже не съест всю память и не вытеснит чат в самый неудобный момент.
Тяжелые задачи лучше вынести в отдельный пул из целых GPU. Причина простая: пакетная обработка документов и дообучение плохо любят тесные ограничения. Им нужен запас по памяти, свобода для батчинга и возможность занять карту целиком на несколько часов.
Для такой команды расписание часто выглядит так:
- днем MIG держит чат-сервис со стабильной задержкой
- ночью отдельный пул обрабатывает документы большими пачками
- раз в неделю инженеры занимают тот же отдельный пул под дообучение
Именно здесь спор "MIG или отдельные GPU-пулы" обычно решается не в пользу одного варианта, а в пользу сочетания двух. MIG защищает онлайн-сервис. Отдельный пул забирает все, что шумит, растет по памяти и мешает соседям. Для одной команды это часто самый спокойный вариант: чат не страдает, а тяжелые задачи не упираются в слишком узкие рамки.
Где команды чаще ошибаются
Чаще всего команды смотрят на среднюю загрузку GPU и делают слишком спокойный вывод. Если карта занята на 55%, кажется, что запас есть. На практике задержка растет не из-за средней цифры, а из-за коротких пиков, когда несколько тяжелых запросов приходят сразу. В этот момент один сервис забирает память, второй ждет, а третий получает скачок latency и таймауты.
Из-за этого спор "MIG или отдельные GPU-пулы" часто решают по красивому дашборду, а не по реальной форме нагрузки. Средняя загрузка почти ничего не говорит, если у вас есть длинные контексты, неровный трафик и разные SLO у сервисов.
Вторая частая ошибка - слишком мелкая нарезка MIG. На бумаге это выглядит аккуратно: больше изоляции, меньше соседских конфликтов. Но маленькие инстансы быстро упираются в память, хуже переживают всплески и заставляют команду чаще перекладывать задачи вручную. В итоге изоляция есть, а гибкости уже нет.
Проблемы редко видны по одной метрике. Смотрите хотя бы на p95 и p99 latency по каждому сервису, длину очереди перед GPU, занятость CPU на токенизацию и препроцессинг, а также сетевые и дисковые задержки при загрузке моделей и данных.
Еще одна ошибка - смешивать на одной карте сервисы с разным размером контекста. Короткий чат на 2-4 тысячи токенов и анализ длинного документа на 64-128 тысяч токенов ведут себя по-разному. Даже если оба сервиса редко грузят GPU до потолка, длинный контекст может занять память и замедлить соседа. Команда видит "непонятную" деградацию и начинает винить планировщик, хотя причина в плохом соседстве.
Это хорошо видно в простой ситуации: support-бот отвечает клиентам почти мгновенно, а рядом крутится пакетная обработка длинных обращений. Пока поток маленький, все работает. Как только пакетные задачи приходят плотнее, чат-сервис теряет стабильность, хотя средняя загрузка карты все еще выглядит нормальной.
Последняя типичная ошибка - ручные переносы задач без правил. Один инженер переносит тяжелый сервис на свободную карту, другой через день возвращает его обратно, потому что "так было быстрее". Через неделю никто уже не помнит, почему схема стала именно такой.
Если команда не зафиксировала, какие нагрузки можно смешивать, какой размер MIG допустим и кто получает приоритет при перегрузе, конфликты соседних сервисов будут возвращаться снова.
Что проверить перед запуском
Ошибки в схеме MIG или отдельных GPU-пулов чаще всего видны не в спокойный час, а в пике. Пока нагрузка ровная, почти любая конфигурация выглядит нормально. Проблемы начинаются, когда один сервис внезапно раздувает batch, растет длина контекста или рядом запускают тяжелую задачу оценки.
Перед запуском полезно проверить несколько вещей. Замерьте, сколько VRAM съедает самый тяжелый запрос, а не только типичный. Проверьте пиковый сценарий: длинный контекст, высокий max_tokens, параллельные запросы и прогретый кэш. Если модель помещается в MIG-срез только в спокойном режиме, этого мало.
Потом посмотрите, что происходит при конфликте. Запустите рядом batch, увеличьте длину контекста или временно переведите соседний сервис на более тяжелую модель. Важно увидеть не просто факт деградации, а момент, в который она начинается. Именно на этом пороге и решается, годится ли вам MIG или нужен отдельный пул.
Наконец, заранее проверьте правила эскалации. Кто получает приоритет при перегрузе? Что останавливаете первым? Когда batch уступает ресурс онлайн-сервису? Если ответы на эти вопросы появляются уже во время инцидента, схема еще не готова к запуску.
Как ловить конфликты соседей после запуска
Средние цифры почти всегда скрывают проблему. Если смотреть только на общую загрузку GPU, можно пропустить момент, когда один сервис держит память почти под потолок, а другой в это же время ловит рост очереди и скачки p99.
Разделите наблюдение на четыре метрики и держите их рядом: util, memory, queue time и tail latency. Первая показывает, кто занял вычисления, вторая - кто уперся в память, третья - кто начал ждать, четвертая - кто уже отдает медленные ответы пользователям.
Что смотреть каждый день
Собирайте эти метрики не по кластеру целиком, а по конкретному инстансу MIG или по отдельному GPU-пулу. Именно там видно конфликт соседей: один инстанс спокоен, а соседний в те же минуты уходит в длинную очередь и начинает сыпать timeout.
Полезно держать на одном графике еще три события: релизы сервиса, смену модели или ее версии и запуск новых batch-окон. Без таких отметок команда часто спорит о причинах наугад. На практике резкий рост tail latency нередко совпадает не с общим пиком трафика, а с тем, что соседний сервис перевели на более тяжелую модель или дали ему ночной batch в тот же пул.
Отдельно сверяйте всплески ошибок с инстансом или пулом. Если 5xx, timeout или OOM растут только в одном MIG-срезе, проблема обычно локальная. Если ошибки идут по всему пулу сразу, ищите общий источник: новый scheduler policy, неверный batch size, смену квот или общий перегрев по памяти.
Простой пример: команда держит online-инференс и ночную пакетную обработку на соседних GPU. Днем все ровно. После вечернего релиза batch-задача начинает забирать больше memory, queue time у online-сервиса растет с 40 до 300 мс, а p99 ответа прыгает почти вдвое. По средней загрузке кластера это почти не видно, но по одному пулу конфликт виден сразу.
Что пересматривать регулярно
Раз в месяц полезно пересматривать разметку задач по пулам. Нагрузки меняются быстро: модель толстеет, контекст растет, batch-окно сдвигают, а старая схема остается. То, что месяц назад работало нормально, сегодня уже создает соседям лишний шум.
Если у вас единый шлюз вроде RU LLM, добавьте к запросам метки сервиса, модели и пула. Тогда спор о причинах заканчивается быстрее: видно не то, что "кластеру стало хуже", а какой именно сосед создал очередь и где его лучше изолировать.
Что делать дальше
После споров про MIG и отдельные GPU-пулы полезно перейти от мнений к правилам. Самая частая ошибка проста: команда сначала делит карты, а потом пытается понять, почему онлайн-сервис тормозит во время batch-окон. Лучше начать с границы между типами нагрузки.
Онлайн-инференс и batch-задачи не должны жить по одним правилам. Для онлайна задайте жесткий приоритет, потолок по задержке и минимальный гарантированный объем GPU. Для batch сразу решите, когда его можно останавливать, сколько памяти он может занимать и кто отвечает за перенос задач при пиках.
Это удобно зафиксировать в коротком регламенте: какие сервисы нельзя вытеснять ни при каких условиях, какие задачи можно ставить в очередь до ночи, какой запас памяти вы держите под всплески трафика и при каком росте p95 batch автоматически уступает ресурс.
Потом нужен пилот, но не на синтетике. Возьмите две-три типовые модели с разным профилем: например, одну для чата, одну для RAG и одну тяжелую batch-модель. Прогоните их на реальном трафике хотя бы несколько дней. Смотрите не только на среднюю загрузку GPU. Обычно проблему выдают хвост задержки, скачки по памяти и число перезапусков после OOM.
Если часть запросов идет через RU LLM, не спешите расширять свой парк GPU. Сначала сравните три вещи: где должны храниться логи и бэкапы, какая задержка допустима для вашего сценария и сколько стоит запрос в каждом контуре. Для части команд ответ оказывается простым: часть нагрузки удобнее оставить на OpenAI-совместимом шлюзе с инфраструктурой внутри РФ, а свое железо докупать только под самые чувствительные сервисы.
Еще один полезный шаг - заранее записать момент, когда дробить существующие карты уже бессмысленно. Такой порог обычно виден по двум признакам. Первый: онлайн-сервисы регулярно ловят просадку во время соседних batch-задач, хотя вы уже ужали лимиты. Второй: команда тратит слишком много времени на ручное разведение моделей по картам и постоянные исключения в планировщике.
Если это повторяется каждую неделю, спор обычно закрыт. Проще выделить отдельный пул под конфликтную нагрузку, чем дальше выжимать из MIG аккуратную схему, которая ломается при каждом новом сервисе.
Часто задаваемые вопросы
Что выбрать, если на одной GPU живут чат и batch-задачи?
Если чат и batch живут на одной карте, начните с разделения. Для чата обычно лучше дать MIG, а batch вынести в отдельный пул, если он регулярно дает хвосты по задержке.
Если batch редкий и короткий, можно сначала проверить MIG на пилоте. Но как только p95 и p99 у чата растут в часы пакетных прогонов, общий контур лучше разнести.
Когда MIG действительно дает пользу?
MIG помогает там, где нескольким сервисам нужны жесткие границы по памяти и более ровное поведение. Он хорошо сдерживает соседа, который внезапно поднял batch size, прогрел новую модель или получил всплеск запросов.
Больше всего пользы он дает на стабильных маршрутах, где профиль нагрузки понятен заранее. Если сервису нужен целый GPU на несколько часов, MIG уже мешает.
В каких случаях отдельные GPU-пулы удобнее MIG?
Отдельные пулы берите, когда задачи живут в разном ритме и мешают друг другу по целям. Онлайн-сервису нужна низкая задержка, batch хочет занять карту надолго, а обучение часто просит весь узел.
Такой вариант еще удобен, когда команды выпускают обновления в разное время. Тогда сбой или перезапуск в одном пуле не цепляет прод рядом.
Почему средняя загрузка GPU часто вводит в заблуждение?
Потому что среднее скрывает пики и очереди. Карта может выглядеть занятой только на 55%, а каждый сотый запрос уже ждет в разы дольше из-за тяжелого соседа.
Смотрите не только на util. Если p95, p99 и queue time растут в определенные часы, запас на графике ничего не значит.
Как понять, что сервис упирается в память, а не в вычисления?
Сначала посмотрите на симптомы. OOM и резкие скачки VRAM обычно говорят про память, а долгие периоды под 95–100% util при свободной памяти чаще указывают на compute.
Если ни память, ни util не забиты, а запросы копятся, ищите проблему в очередях, батчинге или лимитах параллельности. Там часто и сидит причина.
Можно ли держать обучение рядом с прод-инференсом?
Обычно не стоит. Обучение и fine-tune долго держат карту, любят весь узел и плохо уживаются с продом, где ждут ровный отклик.
Если карт мало, хотя бы не сажайте обучение рядом с сервисом с жестким SLA. Даже редкий прогон может испортить задержку и добавить OOM.
Стоит ли делать много маленьких MIG-инстансов?
Не режьте карту слишком мелко без причины. Маленькие инстансы быстро упираются в память, хуже переживают всплески и заставляют команду чаще двигать задачи вручную.
Лучше взять размер с запасом под тяжелый запрос, а не под средний. Если сервис помещается только в спокойный час, профиль уже тесный.
Какие метрики смотреть, чтобы честно сравнить MIG и пулы?
На пилоте смотрите p95 и p99 latency, queue time, долю OOM, число отмененных запросов и время до первого токена. Эти метрики быстрее показывают конфликт, чем средняя загрузка.
Проверяйте их в обычный час и в пик. Разница между схемами часто видна только тогда, когда сосед резко увеличивает контекст или запускает batch.
Что проверить перед запуском новой схемы?
Прогоните самый тяжелый сценарий, а не только типичный. Проверьте длинный контекст, высокий max_tokens, параллельные запросы и конфликт с соседней задачей.
Еще заранее решите, кто уступает ресурс при перегрузе. Если команда придумывает это уже во время инцидента, схема сырая.
Как ловить конфликты соседних сервисов после запуска?
Держите рядом четыре вещи: util, memory, queue time и tail latency. Снимайте их не по кластеру целиком, а по конкретному MIG-инстансу или пулу.
Добавьте на графики релизы, смену модели и старт batch-окон. Тогда вы быстро увидите, какой сосед создал очередь и кого пора изолировать.