Маскирование персональных данных в LLM-запросах без сбоев
Маскирование персональных данных в LLM-запросах: какие поля скрывать, как не портить смысл промпта и как проверить качество ответа до запуска в прод.
Где обычно утекают персональные данные
Утечка начинается не в момент вызова модели, а раньше. Пользователь пишет одно предложение, а система добавляет историю диалога, заметки оператора, результаты поиска, OCR из вложений и служебные поля. В итоге в запрос попадает больше данных, чем команда вообще собиралась отправлять.
Частый источник риска - история переписки. В новом сообщении может не быть ничего чувствительного, но в предыдущих репликах уже есть телефон, email, адрес, номер договора или паспорта. Если приложение автоматически прикладывает последние 10-20 сообщений, модель получает весь этот хвост вместе с лишними деталями.
Инструменты добавляют еще больше сырого текста. OCR по фото паспорта, распознавание PDF, выгрузка из CRM, фрагмент тикета, расшифровка звонка - все это часто уходит в LLM без очистки. Достаточно одной строки вроде "перезвонить на +7..." или "почта клиента...", чтобы запрос стал чувствительным. Обычно команда смотрит на основной промпт, а утечка сидит в приложенном контексте.
Есть и менее заметный слой - инфраструктура. То, что увидела модель, часто видят и внутренние системы: access-логи API, трассировки, debug-дампы, очереди задач, кэши и бэкапы. Если запрос ушел без редактирования, те же поля оседают сразу в нескольких местах. Поэтому маскирование должно стоять до точки, где собирается полный запрос, и до любого логирования.
Для российских команд это особенно чувствительно из-за 152-ФЗ. Даже если вы используете шлюз с data residency и аудит-трейлами в РФ, например RU LLM, лишние данные лучше не отправлять вовсе. Хранить их внутри страны безопаснее, чем за ее пределами, но еще лучше не тащить их в LLM-цепочку без причины.
На практике утечка редко выглядит как громкий провал. Обычно это мелочь: старая реплика в истории, строка из OCR, поле email из CRM, которое никто не убрал. Но именно такие мелочи и уезжают в запрос первыми.
Какие поля скрывать в первую очередь
Начните с прямых идентификаторов. Модели почти никогда не нужен полный набор персональных данных, чтобы понять суть запроса, найти ошибку в тексте или подготовить черновик ответа. Если в промпте остаются ФИО, телефон, email, адрес и дата рождения, риск уже высокий, а пользы для качества обычно мало.
Простое правило работает лучше всего: все, что прямо указывает на человека, скрывайте по умолчанию. Оставляйте только признаки, без которых модель не сможет решить задачу. Вместо "Иван Петров, 12.03.1988, +7..." лучше передать "клиент_1, взрослый, телефон скрыт". Для классификации обращения, суммаризации диалога или черновика ответа этого почти всегда хватает.
Следующий слой - реквизиты из документов и учетных систем. Скрывайте паспортные данные, СНИЛС, ИНН, номер договора, номер счета, карты или заявки, а также внутренние ID, если по ним можно быстро найти клиента.
Проблема в том, что такие поля живут не только в отдельных колонках. Оператор пишет комментарий в CRM, вставляет кусок переписки, копирует результат поиска, и PII незаметно попадает в промпт. Поэтому проверять нужно не только структурированные поля, но и весь свободный текст. На практике именно заметки и комментарии чаще всего ломают политику безопасности.
Где PII прячется чаще всего
Отдельно смотрите на вложения. PDF, сканы, фотографии документов и экспорт из CRM опасны вдвойне: сначала команда забывает про файл, потом OCR вытаскивает из него паспорт, адрес и номер договора, а дальше этот текст уходит в модель. Если у вас есть этап распознавания, применяйте маску после OCR, а не только до него.
Тот же принцип работает для результатов поиска по CRM. Сотрудник может спросить модель: "Собери краткую историю клиента", а в контекст попадут старые заявки, адреса доставки, телефоны родственников и служебные пометки. Надежный порядок такой: сначала отфильтровать набор полей, потом собирать промпт.
Даже если шлюз умеет маскировать PII и вести аудит-трейлы, команде все равно нужен свой список обязательных полей для скрытия. Иначе одна интеграция будет чистой, а другая тихо потащит лишние данные из комментариев, OCR или поиска.
Что скрывать выборочно
Сложнее всего работать не с теми полями, которые можно убрать целиком, а с теми, где персональные данные смешаны со смыслом. Если стереть их без разбора, ответ станет слишком общим или начнет ошибаться в деталях.
Здесь помогает простое деление: что идентифицирует человека и что помогает понять ситуацию. Убирать нужно первое. Второе лучше оставить, но в более безопасном виде.
Точная дата рождения редко нужна модели. В большинстве сценариев хватает возрастного диапазона: 18-24, 25-34, 35-44. Если логика зависит только от совершеннолетия или пенсионного возраста, оставьте именно этот признак, а не саму дату.
С номерами заказа, заявки или договора полезно сохранить форму, если по ней модель что-то понимает. Код может показывать тип продукта, год оформления или канал продаж. В таком случае не удаляйте номер целиком. Лучше скрыть середину или последние блоки: вместо DP-2024-483921-77 оставить DP-2024-XXXXXX-77. Модель увидит структуру и не потеряет опору для ответа.
Названия продуктов, тарифов и статусов обычно трогать не стоит. Они не всегда относятся к PII, зато сильно влияют на смысл. Разница между тарифами "Базовый", "Премиум" и "Корпоративный" меняет ответ. То же самое со статусами вроде "оспаривается", "заморожен" или "на ручной проверке".
На практике безопасная замена часто выглядит так: возрастной диапазон вместо даты рождения, город или регион вместо полного адреса, диапазон суммы вместо точного баланса, тип клиента вместо ФИО, структура идентификатора вместо полного номера.
Хороший ориентир простой: если поле нужно для логики ответа, не удаляйте его полностью. Сначала спросите, какая именно часть этого поля помогает модели рассуждать.
Вместо "Ирина Соколова, 14.03.1987, договор BK-2023-771245-12, тариф Зарплатный Плюс, статус просрочка 4 дня" лучше передать "клиент 35-44, договор BK-2023-XXXXXX-12, тариф Зарплатный Плюс, статус просрочка 4 дня". Имя и точная дата исчезли, но контекст остался. Для модели этого обычно достаточно.
Если сомневаетесь, уменьшайте точность, а не смысл. Это правило редко подводит.
Как выбрать формат маски
Хорошая маска скрывает человека, но не ломает смысл запроса. Если заменить все подряд на одно слово вроде [DATA], качество ответа быстро падает даже на коротких диалогах.
Обычно лучше работают простые и читаемые плейсхолдеры: [CLIENT_NAME], [PHONE], [EMAIL], [ACCOUNT_ID]. Модель понимает их без дополнительных пояснений. Такие метки полезнее случайных хэшей вроде X9F2A, потому что они сохраняют роль поля в тексте.
Одна сущность - одна маска
Если имя клиента встречается в запросе три раза, везде ставьте один и тот же плейсхолдер. Иначе модель решит, что это разные люди. Если в кейсе участвуют два клиента, дайте разные маски: [CLIENT_NAME_1] и [CLIENT_NAME_2]. То же правило работает для телефонов, договоров и адресов.
Это особенно заметно в переписке поддержки. Если в первом сообщении стоит [CLIENT_NAME_1], а в ответе оператора внезапно появляется [CLIENT_NAME_3], модель легко перепутает, кто жалуется, а кто отвечает.
Форму данных тоже стоит сохранять там, где она влияет на вывод. Дату полезно маскировать так, чтобы модель видела тип значения: [DATE_DD.MM.YYYY]. Сумму лучше оставлять как сумму: [AMOUNT_RUB]. Для номера телефона или счета иногда важно сохранить длину или формат, если на этом строится проверка.
Есть несколько базовых правил. Имя маски должно быть понятным. Одна и та же сущность должна получать одну и ту же замену. Формат числа, даты или номера лучше сохранять, если он влияет на ответ. И не смешивайте реальные данные и маски в одном фрагменте.
Таблицу соответствий храните отдельно от запроса к модели. Обычно ее привязывают к request_id во внутреннем сервисе или в защищенном хранилище. Самой модели эта таблица не нужна. Она нужна вам, если потом придется восстановить ответ для оператора, аудита или CRM.
Самый плохой вариант - маска, которая скрывает все одинаково и без структуры. Самый практичный - понятные плейсхолдеры с едиными правилами именования.
Как встроить редактирование в поток запроса
Редактирование должно стоять перед любым местом, где текст сохраняется или уходит наружу. Если сырой запрос уже попал в лог, трассировку или ответ инструмента, поздняя маска ничего не исправит.
Сначала соберите весь контекст в один пакет. Туда входит не только сообщение пользователя, но и история чата, системный промпт, аргументы tools, ответы CRM и поиска, OCR из PDF, текст вложений и служебные поля вроде customer_id, email менеджера или номера обращения. PII часто прячется именно там, а не в основном вопросе.
Дальше порядок обработки обычно такой:
- Нормализуйте вход. Приведите телефоны, даты и номера документов к одному виду, уберите лишние пробелы и разный формат записи.
- Прогоните пакет через правила для очевидных случаев: телефон, email, ИНН, СНИЛС, номер карты, паспорт, адрес.
- После этого подключите NER для имен, фамилий, адресов и свободного текста, где шаблонов уже мало.
- Спорные места проверьте словарями и бизнес-контекстом. Слово "Мир" может быть платежной системой, а может быть обычным словом. "Иванов" может быть фамилией клиента или названием файла.
- Подменяйте найденные значения плейсхолдерами до логирования и до отправки в модель. В LLM и в журналы должен уйти уже очищенный текст.
После подмены сохраните защищенную таблицу соответствий: какой плейсхолдер чему соответствует, по какому правилу вы его нашли, какая версия политики сработала, кто отправил запрос и какой маршрут выбрали для модели. Это и есть аудит-запись, которая помогает разбирать спорные ответы и проверять соблюдение 152-ФЗ.
Возвращайте реальные данные только в самом конце, когда приложение вставляет ответ в готовый шаблон. Если модель пишет внутреннее резюме, классифицирует тикет или выбирает отдел, обратная подстановка обычно не нужна. Если банк готовит письмо клиенту, приложение может вставить имя и номер договора уже после ответа модели. Такой порядок заметно снижает риск и обычно не портит качество, если маски простые и одинаковые по всему диалогу.
Пример на обращении в банк
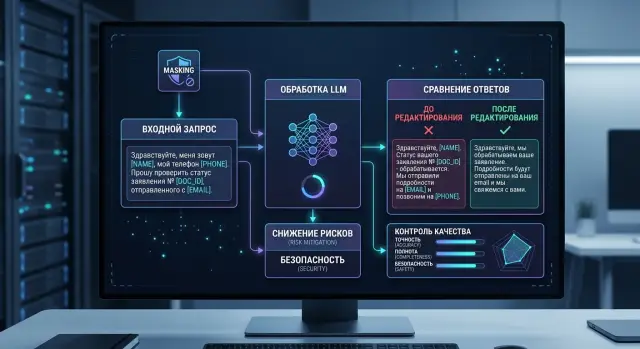
Клиент пишет в чат банка: "Не узнаю списание на 12 480 рублей 14 мая. Карта 2200 45XX XXXX 1234. Перезвоните мне на +7...". В истории диалога могут быть ФИО, номер телефона и данные документа. Если сделать маскирование аккуратно, модель все равно поймет суть: есть спорная операция, известны сумма, дата и тип обращения, нужен понятный порядок действий.
До и после маскирования
Перед отправкой в модель система скрывает поля, которые не влияют на ответ. "Иван Петров" превращается в [CLIENT_NAME], телефон в [PHONE], документ в [DOC_ID]. Номер карты тоже не стоит передавать целиком. Чаще всего хватает [CARD] или [CARD_LAST4=1234], если последние цифры нужны для сверки внутри процесса.
При этом смысловые данные лучше оставить. Для такого запроса модели обычно нужны тип операции, сумма, дата и время, а также канал операции, например интернет-магазин или банкомат. С этим набором она может дать нормальный ответ без лишней воды: предложить временно заблокировать карту, проверить другие списания, оформить заявление на спорную операцию и указать срок рассмотрения. Паспорт в тексте ответа клиенту для этого не нужен.
Как команда проверяет результат
После редактирования данных перед LLM стоит смотреть не на общее впечатление, а на конкретные детали. Команда берет набор реальных обращений, готовит эталонные ответы и запускает две версии каждого запроса: до маскирования и после него.
Дальше она проверяет несколько вещей: сохранилась ли сумма спорной операции, остался ли верный порядок шагов, не исчез ли срок подачи заявления, не стала ли модель заново просить скрытые данные и не превратился ли ответ в слишком общую отписку.
Если после маски модель по-прежнему различает спорную покупку, перевод и снятие наличных, схема работает. Если качество падает, причина часто банальна: система скрыла не только PII, но и поле, без которого уже нельзя понять саму проблему клиента.
Как проверить, что качество не просело
Проверять нужно на реальных запросах, а не на пяти удачных примерах из одного сценария. Возьмите кейсы из разных потоков: поддержка, продажи, внутренние заметки, обращения клиентов, извлечение данных из документов. Если у вас банк, включите и заявки, и переписку, и короткие вопросы вроде "почему списали комиссию".
Сравнение должно идти на одной и той же модели и с одними и теми же настройками. Меняйте только текст запроса: сначала исходный вариант, потом версию после редактирования. Если поменять модель, температуру или системный промпт, вы уже не поймете, что именно испортило ответ.
Смотрите не на одно общее впечатление, а на несколько простых метрик:
- полнота ответа: модель закрыла все части вопроса или потеряла кусок смысла;
- точность фактов: даты, суммы, номера договоров, статусы, сроки;
- доля отказов: не стала ли модель чаще писать, что ей не хватает данных;
- полезность ответа: может ли сотрудник или клиент сделать следующий шаг.
Отдельно соберите группу запросов, где смысл держится на связях между полями. Именно там чаще всего всплывают сбои. Если вы скрыли имя клиента, дату операции и сумму как три независимые маски, модель может перестать понимать, что все три поля относятся к одной и той же транзакции.
Хороший тестовый набор почти всегда включает сложные случаи: несколько дат в одном запросе, похожие суммы, два клиента в одном диалоге, длинную историю по счету. Именно они показывают, убирает ли маска лишние детали или ломает логику ответа.
Автоматической проверки мало. Оставьте 20-30 спорных запросов на ручную оценку предметным экспертам. Юрист заметит, что ответ стал опасно расплывчатым, а сотрудник поддержки увидит, что модель перестала различать клиента и его представителя. Лучше давать экспертам пары ответов вслепую, без пометки "до" и "после".
Если вы уже прогоняете запросы через шлюз вроде RU LLM, удобно сохранять версии промпта и аудит-трейлы для такого сравнения. Тогда команда быстрее находит, какое именно правило испортило качество, и правит его точечно, а не откатывает весь пайплайн.
Частые ошибки
Самая частая ошибка проста: команда начинает скрывать все цифры подряд. После этого промпт теряет смысл. Для модели номер договора, сумма, дата операции, последние 4 цифры карты и номер заявки часто нужны не как персональные данные, а как опорные признаки задачи. Если удалить весь числовой текст, модель начинает путать события, хуже сортирует обращения и дает расплывчатый ответ.
В банковском кейсе это видно сразу. Фраза "клиент оспаривает списание 12 450 рублей от 03.04 по карте *1234" после грубой чистки превращается почти в пустой шаблон. Модель уже не понимает, какое списание обсуждается и чем один эпизод отличается от другого.
Другая ошибка ломает диалог тише, но не меньше: один и тот же человек получает разные маски в соседних сообщениях. В первом запросе Иван Петров стал [CLIENT_1], во втором - [PERSON_A], в ответе CRM - [USER_77]. Для человека это еще читаемо, а для модели это уже три разные сущности.
Поэтому лучше держать одну стабильную маску в рамках сессии. Если клиент уже стал [CLIENT_1], это имя должно жить во всех репликах, tool outputs и служебных сообщениях, пока диалог не закончился.
Часто забывают и про второй источник утечек: не сам ввод пользователя, а данные из инструментов. Поиск по CRM, OCR вложений, ASR звонка, ответ антифрода, кусок SQL-выгрузки - все это тоже уходит в промпт. Если вы маскируете только текст из чата, а затем добавляете сырой tool output, защита почти не работает.
Еще одна неприятная ошибка - сначала писать сырой текст в логи, а редактирование делать позже. В такой схеме персональные данные уже попали в access logs, трассировку, отладочные дампы и резервные копии. Позднее маскирование этого не исправит. Если вы используете шлюз или прокси вроде RU LLM, проверьте, где именно срабатывает маска: до логов, до кэша и до отправки запроса дальше.
Наконец, многие смотрят только на сам факт редактирования и забывают про качество ответа. Обычно просадка заметна не в явных ошибках, а в тоне модели. Она начинает чаще отвечать общими фразами, просит уточнить то, что раньше понимала сама, или становится слишком осторожной там, где раньше уверенно решала задачу.
Это нужно измерять на тестовом наборе. Сравните ответы до и после маскирования на 30-50 реальных запросах. Если модель стала чаще терять детали, значит вы скрываете лишнее или делаете маски слишком шумными.
Короткий чек перед запуском
Перед релизом смотрите не только на сам промпт. Чаще всего данные утекают через соседние части запроса: историю диалога, поля из CRM, заметки оператора, tool inputs, отладочные логи и ретраи. Если хотя бы один из этих каналов обходит редактирование, схема уже дырявая.
Перед запуском новой цепочки или новой модели обычно достаточно пройти короткий список:
- все источники контекста проходят редактирование до отправки в модель и до записи в логи;
- один и тот же тип данных получает одну и ту же маску во всех сервисах;
- у вас есть тестовый набор с реальными сценариями и понятными критериями качества;
- команда заранее договорилась, кто смотрит аудит-записи, кто разбирает спорные случаи и кто принимает решение по инциденту;
- требования 152-ФЗ живут в самом пайплайне: есть правила хранения, маскирования, доступа к логам и удаления данных.
Отдельно проверьте консистентность на простом примере. Если клиент Иван Петров встречается в истории пять раз, система не должна превращать его то в [PERSON_1], то в [CLIENT], то в пустое место. Модель хуже держит контекст, когда одна сущность меняет имя по ходу запроса.
Признак готовности простой: вы можете взять любой запрос, показать путь данных от входа до лога и точно объяснить, где сработало маскирование, кто видит аудит-запись и почему ответ не потерял смысл. Для продакшена такой прозрачности обычно достаточно.
Что делать дальше
Не пытайтесь закрыть все сценарии сразу. Лучше начать с одного потока, где риск высокий, а эффект виден быстро. Обычно это обращения в поддержку, банковские заявки, переписка колл-центра или внутренний помощник, который читает заметки из CRM.
Первый шаг лучше делать на потоке с понятными полями: ФИО, телефон, номер договора, адрес, паспортные данные. Для пилота этого достаточно. Если после маскирования оператор или бот решает задачу так же часто, а чувствительные данные перестают уходить в модель, значит база собрана правильно.
Дальше нужен регрессионный набор. Соберите 50-100 реальных запросов без лишнего шума и сохраните ожидаемый результат: класс ответа, извлеченные поля, итоговую подсказку оператору или оценку качества человеком. После каждого изменения правил прогоняйте этот набор заново. Иначе одно новое правило легко сломает соседний сценарий, а заметите вы это уже в проде.
Дальше остается решить три вопроса: где именно маскировать данные, какие поля скрывать всегда, а какие только в части сценариев, и как вы проверяете, что маска не ломает смысл запроса.
Если логика простая и у вас один сервис, маскирование в приложении часто быстрее всего. Если сервисов много, удобнее вынести правила в шлюз или в отдельный слой, чтобы не дублировать код. Для российских команд здесь часто важен и регуляторный контекст. Если нужен единый OpenAI-совместимый шлюз в РФ с data residency, логами и бэкапами на серверах в России, аудит-трейлами и встроенным маскированием PII, имеет смысл сравнить текущую схему с RU LLM. Но базовое правило не меняется: сначала убрать лишние данные, потом отправлять запрос в модель.
Нормальный финал пилота выглядит просто: один поток закрыт, метрики до и после собраны, регрессия запускается автоматически, место маскирования выбрано осознанно. После этого уже можно расширять правила на соседние сценарии, а не чинить хаос по мере жалоб.
Часто задаваемые вопросы
С чего обычно начинается утечка персональных данных в LLM?
Чаще всего проблема не в одном сообщении пользователя, а в полном пакете контекста. История чата, OCR из вложений, заметки оператора, ответы CRM и служебные поля легко добавляют телефон, email, адрес или номер документа туда, где команда этого не ждала.
Какие поля стоит скрывать в первую очередь?
По умолчанию скрывайте все прямые идентификаторы: ФИО, телефон, email, полный адрес, дату рождения, паспортные данные, СНИЛС, ИНН и номера, по которым можно быстро найти клиента. Для модели чаще хватает замены вроде клиент_1, [PHONE] или [DOC_ID].
Нужно ли убирать из запроса все цифры?
Нет, это часто портит смысл. Сумма, дата операции, последние 4 цифры карты или структура номера договора помогают модели понять ситуацию, поэтому лучше уменьшать точность, а не стирать все подряд.
Что можно оставить, чтобы ответ не стал слишком общим?
Оставляйте то, что влияет на решение задачи, но в более безопасном виде. Обычно хватает возрастного диапазона вместо даты рождения, города вместо полного адреса, диапазона суммы вместо точного баланса и маскированного номера вроде BK-2023-XXXXXX-12.
Какой формат масок лучше использовать?
Лучше всего работают понятные плейсхолдеры вроде [CLIENT_NAME], [PHONE] и [EMAIL]. Если одна и та же сущность встречается несколько раз, давайте ей одну и ту же маску, иначе модель решит, что это разные люди.
На каком этапе лучше маскировать данные?
Ставьте редактирование до логов, кэша, трассировок и отправки в модель. Сначала соберите весь контекст, потом нормализуйте текст, найдите чувствительные поля и только после этого отправляйте очищенную версию дальше.
Зачем отдельно проверять OCR, CRM и tool outputs?
Потому что утечка часто живет именно там, а не в чате. Один фрагмент из OCR или старый комментарий из CRM может добавить в промпт паспорт, адрес или телефон, даже если само сообщение пользователя чистое.
Как понять, что маскирование не ломает качество ответа?
Возьмите реальные запросы и прогоните их на одной модели с одними и теми же настройками: сначала без маски, потом с маской. Смотрите, сохранились ли факты, не стало ли больше общих ответов и может ли человек сделать следующий шаг без лишних уточнений.
Какие ошибки встречаются чаще всего?
Чаще всего вредят три вещи: команда скрывает все числа, меняет маски одной сущности по ходу диалога и пишет сырой текст в логи до очистки. После этого модель путает события, а чувствительные данные уже остаются в инфраструктуре.
Когда лучше вынести маскирование в шлюз?
Если у вас один сервис и простой поток, маски в приложении часто хватает. Когда интеграций много, шлюз упрощает общие правила, аудит и хранение данных в РФ, но список полей для обязательного скрытия команде все равно нужно задать самой.