Куда уходит мой запрос: путь данных, хранение и логи
Куда уходит мой запрос? Разберем, как честно описать путь данных, хранение, выбор провайдера и журналы без общих обещаний.
Почему люди спрашивают, куда уходит запрос
Когда человек спрашивает: "Куда уходит мой запрос?", он редко интересуется только сетью или схемой API. Обычно смысл вопроса проще: кто сможет прочитать текст после отправки.
Если в запросе есть договор, паспортные данные, переписка с клиентом или внутренние цифры, разговор сразу становится практическим. Людей волнует не абстрактная архитектура, а чужой доступ к конкретным данным.
Дальше появляется второй вопрос: как долго эти данные живут. Текст исчезает сразу после ответа или остается в логах на недели? Он хранится на серверах в России или уходит в другой контур? Для команд, которые работают под 152-ФЗ, это обычная проверка перед запуском, а не формальность.
Есть и третий слой тревоги. Многие думают, что общаются с одной системой, хотя на деле цепочка длиннее: приложение, сервер компании, LLM-шлюз, провайдер модели, журналирование, резервные копии. Если эту цепочку не назвать прямо, пользователь обычно додумывает худший вариант.
За коротким вопросом чаще всего скрываются четыре отдельных:
- кто получает текст на каждом этапе;
- где именно он хранится;
- как долго он лежит в системе;
- уходит ли он стороннему провайдеру и при каких условиях.
Раздражают не строгие правила, а туманные ответы. Фразы вроде "мы серьезно относимся к безопасности" ничего не объясняют. Пользователю нужен маршрут: куда пришел запрос, что с ним сделали, что записали в лог и когда это удалят.
В российском контексте это особенно заметно. В банке, телекоме, госсекторе или ритейле никто не хочет гадать, проходит ли текст через внешний API, остаются ли копии за пределами РФ и кто потом сможет поднять эти записи. Чем проще схема, тем меньше недоверия. Если схемы нет, люди быстро приходят к выводу, что от них что-то скрывают.
Что должно быть в честном ответе
Честный ответ начинается не со слов про бережное отношение к данным, а с понятной цепочки: где запрос появился, через какие узлы прошел, кто его обработал и что осталось после этого в системе.
Если человек спрашивает, куда уходит его запрос, ему нужен маршрут по шагам:
- Пользователь вводит текст в приложении.
- Приложение отправляет его на сервер компании.
- Сервер передает запрос в LLM-шлюз, если он есть.
- Шлюз направляет запрос к выбранной модели или провайдеру.
- Ответ возвращается назад по той же цепочке.
Уже этого достаточно, чтобы убрать туман. Если между сервером и моделью стоит отдельный шлюз, его надо назвать прямо. Если команда использует RU LLM, это отдельный узел маршрута, а не безликая "внутренняя инфраструктура".
Сразу после маршрута нужно разделить две вещи: обработку запроса и хранение. Обработка - это путь текста до модели и обратно. Логи - это отдельные записи: время вызова, идентификатор клиента, выбранная модель, длина промпта, код ответа, а иногда и сам текст запроса или ответа.
Если текст запроса не попадает в логи, это стоит сказать прямо. Если попадает частично, тоже. Если система маскирует персональные данные до записи, это нужно вынести в отдельную фразу, а не прятать в сноске.
Еще один обязательный пункт - кто выбирает модель и провайдера. Это может делать код приложения, правило в шлюзе или оператор для части трафика. Если запросы идут через RU LLM, их можно вести через единый OpenAI-совместимый эндпоинт, а выбор конкретной модели и провайдера остается на стороне маршрутизации. Пользователь должен понимать, маршрут фиксированный или он меняется по правилам.
Отдельно нужно описать хранение. Тут достаточно четырех простых ответов: где лежат логи, где лежат бэкапы, кто имеет к ним доступ и как работает удаление. Если логи и резервные копии хранятся в РФ, это лучше написать прямо. Если удаление из рабочих логов не означает мгновенное удаление из бэкапов, об этом тоже нужно сказать.
Как показать путь запроса
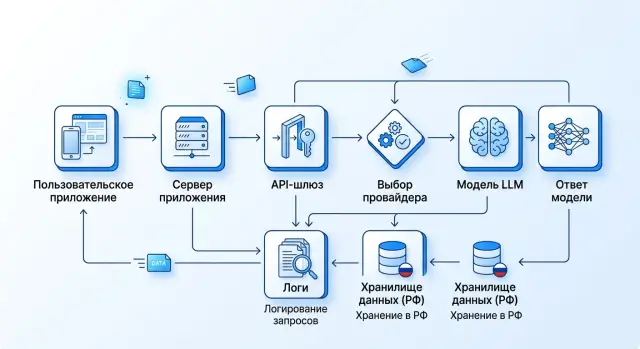
Когда клиент спрашивает, куда уходит его запрос, ему не нужна архитектурная схема на 20 блоков. Нужен один путь слева направо: куда текст пришел сначала, кто решил маршрут, что осталось в логах и когда это удалят.
Для большинства команд хватает пяти блоков.
Сначала покажите точку входа. Это может быть API-шлюз, чат-бэкенд или внешний эндпоинт, куда клиент отправляет текст. Если используется прокси-слой вроде RU LLM, первым узлом на схеме лучше показывать именно его, а не абстрактную "модель".
Сразу после точки входа отметьте проверку и маскирование персональных данных. Если система скрывает телефон, email, ФИО или номер договора до отправки дальше, это должно быть видно на схеме. Люди хотят видеть не обещание, а место в цепочке, где это происходит.
Затем покажите слой, который выбирает маршрут. Решение принимает не "система в целом", а конкретный узел: приложение, роутер или набор правил в шлюзе. Рядом полезно указать, по каким признакам он выбирает путь: доступная модель, требования к размещению данных, стоимость, задержка, резервный маршрут.
После этого идет узел исполнения. Это либо внешний провайдер модели, либо собственный inference-кластер. Если часть запросов уходит наружу, а часть обрабатывается внутри РФ, это нужно отметить прямо, без мелкого шрифта и оговорок.
Отдельным блоком вынесите журналирование. Укажите, что туда попадает: время запроса, ID клиента или проекта, выбранная модель, число токенов, статус ответа, request_id, ошибки. Если полный текст запроса не пишется в лог или сохраняется только в маскированном виде, это надо сказать прямо.
Под схемой обычно хватает двух коротких строк. Первая - где лежат логи и бэкапы. Вторая - сколько они живут. Без этого даже хорошая схема выглядит незаконченной.
Как писать про хранение данных
Когда речь заходит о хранении, пользователю нужен точный ответ: что именно вы сохраняете, в каком виде и на какой срок. Лучше сразу разделить данные на четыре части: текст запроса, текст ответа модели, технические метаданные и аудит.
Если назвать все это одним словом "логи", ответ будет мутным. Намного понятнее описывать хранение так:
- промпт: храните полный текст или версию с маской;
- ответ модели: храните полностью, частично или не храните совсем;
- метаданные: время, модель, провайдер, токены, статус, идентификатор запроса;
- аудит: отдельная запись о том, кто отправил запрос и что система с ним сделала.
Если вы храните полный текст, это надо написать без обходных формулировок. Если маскируете персональные данные, перечислите, что именно скрываете: ФИО, телефон, email, номер договора, адрес. Фраза "мы можем сохранять данные для качества сервиса" почти бесполезна. Гораздо лучше сказать: "Мы храним текст запроса 7 дней для разбора ошибок. Перед записью маскируем телефон и email".
Срок хранения тоже лучше указывать отдельно для каждого типа данных. Текст запроса и ответа обычно нужен недолго. Метаданные и аудит могут жить дольше, потому что по ним ищут сбои, считают расходы и разбирают спорные случаи. Один срок на все выглядит как отписка.
Отдельно стоит сказать, где лежат резервные копии. Если рабочая база находится в РФ, а бэкап уходит в другой контур или к другому подрядчику, это уже другая схема хранения. Для 152-ФЗ это не мелочь. Если команда работает через RU LLM, можно прямо указать, что логи и бэкапы хранятся на серверах в РФ, а PII маскируется до записи.
Полезно не смешивать рабочую базу и аудит. Рабочая база нужна сервису сейчас: принять запрос, вернуть ответ, показать историю. Аудит нужен позже: проверить маршрут запроса, доступы, маскирование и действия сотрудников. Когда эти контуры разведены и у каждого есть свой срок хранения, ответ звучит спокойно и честно.
Как объяснить маршрутизацию к модели
Если у вас есть шлюз, не стоит писать, что запрос просто "идет в ИИ". Это не ответ. Нормальная формулировка намного проще: запрос сначала приходит в шлюз, а уже потом уходит к выбранной модели напрямую или к внешнему провайдеру.
В описании маршрута стоит называть каждый шаг по имени. Приложение отправляет запрос в backend или сразу в LLM-шлюз. Шлюз проверяет правила маршрутизации, выбирает модель и только после этого передает данные дальше. Если используется RU LLM, внешний вызов идет в api.rullm.com, а выбор провайдера происходит внутри этого слоя.
Людям обычно нужен ответ не на тему "как устроена платформа", а на тему "кто решает, куда уйдет мой текст". Поэтому важно отдельно указать, кто принимает решение о маршруте. Обычно это набор правил, который задала команда: допустимые модели, страна размещения, требования по персональным данным, лимит цены, резервный вариант на случай недоступности.
Маршрут может меняться, и это тоже надо писать прямо. Например, основной запрос идет к одной модели, а если она недоступна или не подходит под правило локализации, шлюз переключает трафик на другую. Если часть сценариев должна оставаться в РФ, это лучше сформулировать без тумана: "Для этих запросов шлюз выбирает только модели, размещенные в России".
Важно отдельно описать, что именно видит внешний провайдер. Не стоит писать: "Провайдер ничего не видит", если наружу все-таки уходят текст запроса, системный промпт или вложения. Если шлюз маскирует PII до отправки, это тоже нужно сказать прямо. У RU LLM есть и собственные open-weight модели на инфраструктуре в российских ЦОДах, поэтому локальный маршрут и внешний маршрут можно развести в описании без догадок.
Хорошее объяснение обычно умещается в несколько строк: запрос приходит в шлюз, шлюз выбирает модель по правилам, при необходимости переключает маршрут на резервный, внешний провайдер получает только разрешенные данные, а для локальных сценариев обработка идет в России.
Что писать про логи и аудит
Журналы нужны не для красивой формулировки в политике, а для ответа на простой вопрос: кто отправил запрос, куда он пошел, что вернулось и кто потом это смотрел. Если вы пишете про аудит, называйте поля прямо.
Минимальный набор обычно такой:
- request_id или другой уникальный идентификатор;
- время приема и время ответа;
- имя модели или провайдера, куда ушел вызов;
- статус запроса: успех, ошибка, тайм-аут, отмена;
- технические поля для разбора инцидентов, например размер ответа или код ошибки.
Отдельно стоит указать, сохраняете ли вы тело запроса и ответа. Если делаете это не всегда, так и напишите: по умолчанию система хранит только метаданные, а полный текст включается на короткий срок для отладки или по заявке клиента. Это понятный и нормальный ответ. Намного хуже звучит фраза "мы можем собирать данные для улучшения сервиса".
С персональными данными нужна конкретика. Лучше сразу указать, какие поля маскируются до записи: ФИО, телефон, email, номер договора, паспортные данные, свободный текст с PII. Если маскирование автоматическое, можно написать, что система заменяет такие фрагменты маркерами до сохранения. Если часть данных все же может остаться в логах, честнее назвать этот риск и условия, при которых это бывает.
Полезно прямо написать, кто читает журналы. Обычно это дежурные инженеры, команда безопасности, администраторы платформы и ограниченный круг сотрудников поддержки по заявке клиента. Для каждой роли лучше указать цель: разбор ошибок, поиск злоупотреблений, аудит доступа, финансовая сверка.
Срок хранения лучше писать цифрами. Например: технические метаданные хранятся 30 или 90 дней, отладочные логи с телом запроса - 7 дней, выгрузки для клиента - по заявке и в согласованном формате, после чего удаляются по регламенту. Если команда использует RU LLM, можно добавить фактическую часть схемы: журналы и резервные копии хранятся на серверах в РФ, а audit trail встроен в обработку каждого запроса.
Простой тест тут один. Если после чтения раздела человек все еще не понимает, сохраняете ли вы полный промпт и кто может его открыть, раздел про аудит нужно переписать.
Пример для чат-бота поддержки
Возьмем обычный сценарий: человек пишет в чат на сайте "Где мой заказ 53142 и почему он не едет?" На такой вопрос лучше отвечать не общими словами, а по реальному пути данных.
Схема обычно выглядит так. Сообщение приходит с сайта на сервер приложения. Сервер добавляет служебный контекст, например номер обращения или статус заказа, и отправляет текст в LLM-шлюз. Шлюз направляет запрос в выбранную модель, а ответ возвращается обратно тем же путем: модель, шлюз, сервер, чат на сайте.
Если команда использует RU LLM, сервер приложения может отправлять запрос в единый OpenAI-совместимый эндпоинт, а сам шлюз уже решает, к какой модели его направить. Пользователю, впрочем, важнее не это, а то, что его сообщение проходит по понятной цепочке систем, а не "гуляет по интернету" без контроля.
Отдельно нужно описать журнал. Для поддержки часто достаточно ID запроса, времени, технического статуса и маскированных полей. Например, вместо полного телефона журнал хранит "+7 9XX XXX-12-34", а вместо полного текста заказа - маску или короткий фрагмент без персональных данных. Не стоит обещать постоянное хранение полного текста, если на деле он нужен только на короткое время для разбора ошибок.
Пользователю можно ответить так:
- "Ваш вопрос сначала приходит на наш сервер поддержки".
- "Потом сервер отправляет в LLM-шлюз только данные, которые нужны для ответа".
- "Шлюз передает запрос в модель и возвращает результат обратно в чат".
- "В журнале мы храним ID запроса, время и маскированные данные, а не полный набор личной информации".
- "Текст обращения мы удаляем по внутреннему сроку хранения или раньше, если этого требует регламент".
Такой ответ звучит спокойно, потому что в нем есть маршрут, состав лога и понятное правило удаления.
Где ответ обычно ломается
Ответ начинает разваливаться там, где команда пытается успокоить пользователя вместо того, чтобы описать путь данных. Когда человек спрашивает, куда уходит его запрос, ему не нужен общий текст про безопасность. Ему нужна простая схема: кто принимает запрос, кто его видит, что сохраняется, где это лежит и когда это удаляют.
Самая частая ошибка - фраза "мы ничего не храним", хотя у системы есть логи. Даже если продукт не кладет текст запроса в основную базу, сервис почти всегда пишет метаданные, ошибки, технические события или журналы доступа. Если это есть, так и нужно сказать.
Вторая ошибка - смешивать разные слои хранения. База продукта, журналы безопасности, трассировка запросов и резервные копии живут по разным правилам. Если свести все к одной фразе вроде "данные хранятся ограниченное время", пользователь так и не поймет, храните ли вы сам текст, только метаданные или и то и другое.
Третий слабый пункт - внешний провайдер. Если запрос уходит не только в вашу систему, это нельзя скрывать за формулировкой "обрабатывается моделью". Нужно прямо написать, видит ли текст внешний провайдер, проходит ли он через шлюз, остается ли обработка внутри РФ или маршрут зависит от выбранной модели. Для RU LLM это особенно заметно: у клиента может быть маршрут через внешнего провайдера или через модель, размещенную на собственной инфраструктуре в российских ЦОДах, и это два разных сценария.
Часто ломается и блок про удаление. Команды пишут "данные удаляются по политике хранения", но не говорят, что происходит с бэкапами и сколько они живут. Если резервные копии существуют, пользователь должен это видеть.
Плохие формулировки обычно выглядят так:
- "Мы ничего не храним", хотя остаются журналы безопасности и метаданные.
- "Запрос обрабатывается у партнера", без указания, кто именно видит текст.
- "Данные удаляются", без срока для основной системы и бэкапов.
- "Все хранится безопасно", без разделения на запросы, ответы, логи и аудит.
- "Используем обезличивание", без пояснения, что маскируется и на каком этапе.
Хороший ответ звучит суше, но вызывает больше доверия. Он называет вещи своими именами: текст запроса, ответ модели, метаданные, логи, аудит-трейлы, бэкапы, срок удаления и место хранения.
Проверка перед публикацией
Перед публикацией полезно убрать все общие слова и проверить, можно ли понять путь запроса за минуту. Если схема не помещается на один экран, читатель, скорее всего, потеряется. Обычно это значит, что в одну картинку смешали сеть, хранение, выбор модели и аудит.
Хорошая схема отвечает на три вопроса: через какие узлы проходит запрос, кто отвечает за каждый узел и что именно там происходит. У "приложения", "API-шлюза" или "внешнего провайдера" должен быть не только ярлык, но и владелец: команда платформы, ИБ, подрядчик или конкретный провайдер модели.
Перед выпуском текста стоит проверить хотя бы пять вещей:
- Путь данных показан целиком: вход, обработка, выбор модели, ответ, хранение, удаление.
- У каждого узла и хранилища указан владелец.
- Сроки хранения для промптов, ответов, логов, бэкапов и аудита не смешаны в одну строку.
- Внешний маршрут описан прямо: уходит ли запрос внешнему провайдеру, остается ли в РФ, проходит ли через прокси.
- Логи, бэкапы и аудит описаны отдельно, потому что это разные сущности с разным доступом и разными сроками.
Особенно внимательно стоит проверить внешний маршрут. Фраза вроде "запрос может обрабатываться партнерской инфраструктурой" ничего не объясняет. Намного честнее написать: "Запрос идет в наш API-шлюз, затем либо остается на наших серверах в РФ, либо отправляется выбранному провайдеру модели". Если маршрут зависит от тарифа, региона или типа модели, это тоже нужно назвать.
Еще один частый сбой - единый срок хранения для всего. На практике текст запроса, технические логи, резервные копии и аудит живут по разным правилам. Для читателя это важная разница, особенно в контексте 152-ФЗ.
Проверять текст лучше не в одиночку. Дайте его поддержке и ИБ. Поддержка быстро увидит, где клиент задаст второй вопрос. ИБ заметит, где формулировка шире, чем реальный процесс. Если обе команды читают текст одинаково, материал готов.
Что делать команде дальше
Когда команда отвечает на вопрос "куда уходит мой запрос", ей нужен не набор устных объяснений, а один рабочий документ. Проще всего собрать таблицу с четырьмя полями: через какой узел проходит запрос, какие данные там видны, сколько они хранятся и кто получает доступ.
Эту таблицу стоит собрать по всей цепочке, а не только по модели. Обычно в нее входят интерфейс, API-шлюз, слой маскирования персональных данных, маршрутизатор, провайдер модели, хранилище логов, бэкапы и аудит. Если на каком-то шаге команда пишет "технические данные" или "служебная информация", это слабое место. Лучше использовать точные формулировки: текст запроса, метаданные, user_id, IP, маскированные поля, идентификатор сессии.
После этого полезно сверить описание с тремя людьми: ИБ, юристом и владельцем продукта. ИБ проверит, не обещает ли текст лишнего. Юрист уберет расплывчатые слова и сверит формулировки с требованиями 152-ФЗ и внутренними правилами. Владелец продукта посмотрит, понятен ли ответ обычному пользователю.
Дальше лучше подготовить две версии. Первая - короткая, для интерфейса или FAQ, в двух-трех предложениях. Вторая - полная, для справки или анкеты безопасности, со схемой маршрутизации, сроками хранения, ролями доступа и описанием журналирования. Люди редко читают длинный текст сразу, но хотят знать, что он у вас есть.
Если LLM-поток идет через RU LLM, часть схемы можно описать без догадок: используется единый OpenAI-совместимый эндпоинт, логи и бэкапы хранятся в РФ, маскирование PII и audit trail встроены в обработку запросов. Но даже в этом случае остается ваша часть схемы: что вы логируете до шлюза, какие поля передаете и кто внутри компании видит эти данные.
Последняя проверка очень простая. Дайте черновик человеку из поддержки. Если он может пересказать путь запроса без слов "примерно" и "где-то у провайдера", текст уже работает.