Кеширование промптов без самообмана: где счёт падает, а где нет
Кеширование промптов снижает расходы только там, где запросы реально повторяются. Разберём TTL, ключи кеша, прогрев и риски для персонализации.
Почему вокруг кеша столько самообмана
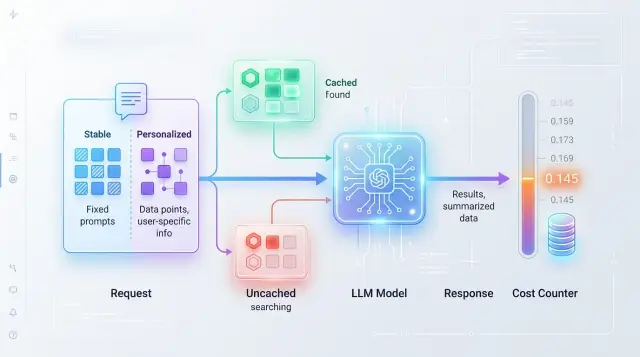
Кеш не снижает счет сам по себе. Он экономит деньги только там, где в модель снова и снова уходит один и тот же текст или очень близкий к нему префикс.
Именно здесь команды чаще всего ошибаются. На тестах все выглядит отлично: один шаблон, несколько одинаковых прогонов, высокий процент попаданий. В проде картина быстро меняется. Пользователь добавил имя, номер заказа, дату, язык ответа или новый кусок истории чата, и совпадение уже исчезло.
Самая частая путаница простая: повторяющимся считают не реальный запрос к модели, а его смысл. Для человека фразы могут быть почти одинаковыми. Для модели это разные входы, если в них отличаются детали. Когда в промпт попадают личные поля, число вариантов растет очень быстро, и кеширование промптов дает меньше пользы, чем ждали.
Особенно заметно это в задачах, где важна персонализация LLM. Общие инструкции, FAQ и повторяющиеся блоки правил обычно кешируются хорошо. А вот финальный промпт целиком - с именем клиента, тарифом, статусом заявки и свежей историей диалога - почти всегда слишком уникален.
Есть и другая ловушка. Команда видит, что средний счет снизился, и записывает это в победы кеша. Но расходы могли упасть по другой причине: сократили системный промпт, сменили модель, убрали длинный контекст или просто получили меньше сложных запросов в этом периоде. Без нормальных метрик легко принять совпадение за результат.
Минимальный набор метрик здесь очень приземленный:
- доля попаданий в кеш по каждому сценарию, а не в среднем по системе;
- число токенов, которые вы перестали отправлять в модель;
- количество новых ключей кеша в день;
- доля промахов из-за персональных полей и мелких отличий в формулировке.
Если повторов мало, кеш красиво смотрится на схеме, но почти не влияет на итоговый инвойс. Это и есть главный тест на трезвость.
Где кеш правда снижает счет
Кеш работает там, где в запросе много повторяющегося текста, а меняется только короткая часть с данными пользователя. Если модель каждый раз заново читает один и тот же длинный каркас, вы платите за одни и те же токены снова и снова.
Первый кандидат - системный промпт. Во многих продуктах он живет неделями: роль ассистента, правила тона, запреты, требования к формату ответа. Если этот блок занимает сотни или тысячи токенов, экономия появляется почти сразу.
То же касается длинных инструкций и справочных вставок. Например, бот поддержки может каждый раз получать политику возвратов, шаблон ответа и выдержки из внутренней базы знаний. Пользовательский вопрос короткий, общий префикс длинный. В такой схеме кеш обычно окупается быстро.
Хорошо работают и однотипные задачи: FAQ с повторяющейся структурой ответа, модерация по одному набору правил, классификация обращений по фиксированным категориям, пакетная обработка, где меняется только строка с входными данными.
У пакетных запросов эффект особенно заметен. Если вы прогоняете тысячу отзывов через один и тот же каркас инструкции, модель не тратит ресурсы на повторное чтение длинного префикса для каждого элемента.
А вот короткие и уникальные запросы редко оправдывают кеш. Если пользователь задает редкий, длинный и сильно персональный вопрос, повторяемой части мало. В таком месте вы добавляете сложность в систему, а выигрыш получается копеечным. Лучше сначала посчитать реальные токены и посмотреть на долю совпадающего префикса, чем включать кеш "на всякий случай".
Где кеш портит ответ
Кеш полезен только там, где повторяется действительно одна и та же задача. Как только в промпт попадают личные детали, свежая история диалога или часто меняющиеся правила, экономия быстро превращается в плохие ответы.
Самая частая ошибка - кешировать промпт целиком, вместе с именем клиента, номером заказа и мелкими отличиями формулировки. "Анна, где мой заказ?" и "Иван, где мой заказ?" похожи для человека, но для кеша это уже два разных запроса. В лучшем случае вы почти не получите попаданий. В худшем - получите ответ с чужим тоном или лишними деталями, если ключ собран небрежно.
История диалога стареет еще быстрее. В поддержке клиент мог сначала спросить про доставку, потом прислать новый адрес, а через минуту перейти к возврату. Если система берет старый ответ из кеша по похожей реплике, она игнорирует новый контекст. Для чата даже 10-15 минут иногда слишком много.
Еще одна проблема - желание сделать один общий ответ для всех. Он дешевый, но часто бесполезный. То, что подходит новому клиенту, раздражает постоянного, которому нужен статус по конкретному договору или тарифу. Персонализация LLM исчезает первой, когда кеш строят по принципу "лишь бы чаще попадало".
Отдельно бьет по качеству слишком длинный срок жизни кеша. Сегодня действуют одни правила возврата, завтра другие. Если TTL живет дольше самих правил, модель начинает уверенно возвращать устаревшую инструкцию. Особенно больно это там, где часто меняются лимиты, SLA, скидки или тексты согласования.
Плохо работает и кеш по сырому запросу. Фраза "не проходит оплата" означает разное для интернет-магазина, банка и внутреннего сервиса. Если ключ не учитывает контекст, система смешивает разные сценарии и отдает уверенный, но чужой ответ.
Надежнее кешировать стабильные части: системные инструкции, шаблоны, справочные блоки. Все, что зависит от человека, текущего шага диалога и свежих правил, лучше держать вне кеша или давать этому очень короткий TTL.
Как внедрять кеш без лишнего риска
Запускать кеш лучше не на всей системе сразу, а на одном понятном сценарии. Подойдет поток, где запросы часто повторяются: FAQ в поддержке, типовые проверки документов, короткие классификации. Узкий пилот быстрее показывает, есть ли реальная экономия, или вы просто видите шум в метриках.
Начните с простого разбиения запроса на две части: стабильную и переменную. В стабильную обычно входят системный промпт, инструкции, шаблон ответа и справочный контекст. В переменную - имя клиента, история диалога, сумма заказа, город, текущий статус и все, что меняется от запроса к запросу. Кешировать имеет смысл только то, что действительно повторяется.
Потом соберите факты хотя бы за неделю. Не по ощущениям, а по логам. Посмотрите, сколько запросов совпадают полностью или почти полностью, как часто они приходят и какие из них дороги по токенам. Иногда кажется, что повторов много, а на деле одинаковых запросов всего 3-5 процентов. В этом случае кеш почти ничего не даст.
Дальше схема простая. Выберите один сценарий с заметной долей повторов, задайте короткий TTL на старте, соберите аккуратный ключ только из стабильных частей и включите метрики по цене, задержке, качеству и доле попаданий. После этого сравните результат с контрольной группой без кеша.
Короткий TTL на старте полезен по простой причине: он редко ломает персонализацию. Если ответы свежие и запросы правда повторяются, доля попаданий вырастет даже при небольшом сроке жизни. Если не вырастет, проблема обычно не в TTL, а в том, что вы пытаетесь кешировать слишком изменчивые данные.
Смотрите не только на счет. Проверяйте долю ручных исправлений, повторные обращения, среднюю длину диалога, ошибки в персональных данных. Если цена упала на 20 процентов, а поддержка стала чаще отвечать невпопад, такой кеш нужно переделывать, а не масштабировать.
Как выбрать TTL без гадания
TTL стоит привязывать не к надежде на экономию, а к тому, как быстро стареют данные внутри запроса. Если кусок промпта не меняется неделями, ему не нужен TTL на 10 минут. Если в ответе участвуют цены, остатки или статус заявки, часы здесь почти всегда опасны.
Правило простое: чем выше цена ошибки, тем короче срок жизни кеша. Ошибка в старой системной инструкции часто терпима. Ошибка в лимите по карте, доступности товара или статусе доставки быстро превращается в плохой ответ и лишний диалог с пользователем.
Статичные части запроса можно держать долго. Это системные инструкции, общие правила тона, редактируемые нечасто FAQ, справка по продукту. Для них TTL часто измеряется часами или днями. Иногда разумнее вообще не ждать истечения срока, а сбрасывать кеш только после явной правки шаблона.
С живыми данными лучше быть строже:
- цены и остатки - 1-5 минут;
- статусы заказов, тикетов и платежей - 30-120 секунд;
- профиль пользователя и персональные лимиты - по событию обновления или с очень коротким TTL;
- общие инструкции и шаблоны - часы или ручной сброс после изменений.
Один TTL на весь запрос обычно портит и экономию, и качество. Гораздо полезнее разбить запрос на части с разной скоростью изменений. В чате поддержки можно отдельно кешировать системный промпт, каталог типовых ответов и результат проверки статуса заказа. Тогда дорогая статичная часть живет долго, а чувствительные данные обновляются быстро.
После правок в политике, шаблоне ответа или бизнес-правиле кеш лучше сбрасывать сразу. Не стоит ждать, пока срок истечет сам. Иначе команда уже работает по новой версии, а модель еще отвечает по старой, и это легко принять за ошибку самой модели.
Как собрать ключ кеша
Почти вся польза от кеша упирается в одну вещь: одинаковые запросы должны давать один и тот же ключ, а разные по смыслу - разные. На практике команды часто ломают это правило сами. Они добавляют в ключ request_id, текущий timestamp или случайный UUID, и кеш перестает работать даже там, где ответ можно было переиспользовать десятки раз.
Включайте в ключ только то, что реально меняет ответ модели. Если вы меняете системный промпт, меняется и поведение модели. Значит, версия системного промпта должна входить в ключ всегда. Иначе вы получите старый ответ по новым правилам.
Обычно в ключ входят версия системного промпта, нормализованный текст пользовательского запроса, язык ответа, точная модель и режим ответа, если он влияет на форму вывода. Не смешивайте в одном ключе ответы разных моделей. Даже при одном и том же промпте они отвечают по-разному. То же относится к JSON-режиму, обычному тексту и вызовам tools.
Нормализация почти всегда нужна. Уберите лишние пробелы, приведите даты к одному формату, решите вопрос с регистром там, где он не несет смысла. Запросы "Статус заказа" и "статус заказа" не должны жить в двух разных записях кеша. Но артикулы, коды и имена полей трогайте осторожно: там регистр иногда важен.
С персональными полями лучше не экспериментировать. Задайте явные исключения: имя клиента, номер договора, баланс, адрес, внутренние идентификаторы. Частый вопрос вроде "как сменить PIN-код" можно кешировать, но персональный блок ответа лучше собирать отдельно или не кешировать совсем.
Есть простой тест. Уберите поле из ключа и спросите себя: изменится ли из-за этого ответ для пользователя? Если нет, поле мешает кешу. Если да, оставляйте.
Как прогреть кеш перед нагрузкой
Прогрев кеша полезен там, где всплеск трафика можно предсказать. Утренний пик в поддержке, рассылка, запуск акции, выход новой версии ассистента - в таких случаях часть запросов почти наверняка повторится. Если прогреть нужные шаблоны заранее, первые пользователи не будут оплачивать холодный старт.
Но брать шаблоны из головы - плохая идея. Нужны логи за последние 7-14 дней: какие промпты или части промптов повторяются чаще всего, какие ответы используют одни и те же инструкции, какие системные блоки долго не меняются. Если трафик идет через единый API-слой вроде RU LLM, такие повторяющиеся шаблоны удобно смотреть по логам и аудит-трейлам в одном месте.
Прогревать стоит не весь запрос, а только стабильные куски. Обычно это системный промпт, правила ответа, блок с политиками компании, частые FAQ и типовые извлечения из базы знаний. Персональные данные, история конкретного диалога, номер заказа, регион пользователя и редкие ветки лучше не греть. Они почти не дадут экономии и быстро забьют кеш мусором.
Нормальная схема выглядит так: выбрать самые частые и дорогие шаблоны, прогонять их перед ожидаемой нагрузкой, считать новую версию шаблона новой сущностью после релиза и отключать прогрев там, где он почти не попадает в реальный трафик.
Простой пример: у чата поддержки каждый понедельник утром растут вопросы про возврат, доставку и смену тарифа. Есть смысл прогреть эти общие шаблоны заранее. Нет смысла греть запросы вроде "где мой заказ 48152" или "пересчитай лимит по моему договору". Там персонализация важнее кеш-хита.
После каждого изменения шаблонов проверяйте версии. Даже небольшая правка в системной инструкции часто меняет результат, и старый прогрев становится бесполезным.
Сценарий: чат поддержки с частыми вопросами
У чата поддержки почти всегда есть длинная общая часть запроса: системная инструкция, тон ответа, запреты, порядок эскалации и база правил. Она не меняется от клиента к клиенту. Меняются тема обращения и несколько полей, например тариф, канал связи или язык ответа.
На практике такой запрос удобно делить на три слоя. Первый слой - общий префикс: роль ассистента, политика ответов, правила возврата, лимиты, шаблоны действий. Второй - короткая переменная часть: тема обращения, продукт, регион, один-два признака клиента. Третий слой - история диалога и личные данные, которые лучше держать отдельно.
Такое разделение дает экономию там, где она действительно заметна. Если общий префикс занимает 1500-2000 токенов, а переменная часть всего 100-200, кеш ловит самый дорогой кусок. При потоке похожих вопросов про доставку, возврат или смену пароля счет падает быстро, потому что модель не читает одни и те же правила на каждом ходе заново.
Историю клиента в кешируемую часть лучше не включать. Иначе ответы начинают подтягивать старый или чужой контекст. Для персонализации обычно хватает пары полей в рабочем запросе: что случилось сейчас и что система должна учесть именно для этого человека.
Есть и еще одна деталь, которую часто упускают. Если команда обновила правила, старый префикс нужно сбросить сразу. Проще всего версионировать общий префикс и включать эту версию в ключ. Тогда после правки политики возврата или текста дисклеймера чат сразу начнет работать по новым правилам.
Ошибки, которые съедают экономию
Самая дорогая ошибка в кешировании промптов - складывать в кеш весь запрос целиком, вместе с именем клиента, email, номером договора или деталями заказа. Такой кеш почти не переиспользуется, потому что каждая мелочь делает запрос новым. Заодно вы тянете личные данные туда, где они не нужны. Для команд с требованиями 152-ФЗ это уже не только слабая экономия, но и лишний риск.
Вторая частая проблема - один TTL для всего. Это удобно только на бумаге. FAQ, справка по тарифам и шаблонные инструкции могут жить часами. Статус доставки, баланс, лимиты и цены меняются быстро. Один срок жизни здесь либо держит устаревшие ответы, либо слишком рано выбрасывает полезный кеш.
Многие смотрят только на долю попаданий и радуются цифре. Но высокий показатель сам по себе ничего не доказывает. Если после кеша ответы стали более общими, модель хуже учитывает контекст, а персонализация просела, экономия мнимая.
Есть и более тихая ошибка: команда меняет системный промпт, правила маршрутизации или формат ответа, но не обновляет версию в ключе. В итоге новый код читает старые ответы. На графике все выглядит нормально, а в продукте начинается путаница.
Обычно хватает четырех правил. Отделяйте общую часть промпта от личных и быстро меняющихся полей. Задавайте разный TTL для справки, каталога, статусов и персональных сценариев. После правки промпта или схемы ответа меняйте версию ключа. И прогревайте кеш только частыми запросами из реального трафика.
Быстрая проверка перед запуском
Перед запуском смотрите не на общий процент попаданий, а на результаты по каждому сценарию. Один и тот же кеш может хорошо работать для FAQ, но почти ничего не давать в чате с длинной историей. Если смешать эти случаи в одном графике, цифра будет красивой, а пользы не видно.
Отдельно разметьте, какие части промпта вообще участвуют в попаданиях. Часто кеш ломает одна мелочь: timestamp, имя менеджера, id сессии, trace id или короткая персональная вставка. Полезно видеть это по слоям: системный промпт, шаблон задачи, контекст из базы, история чата, данные пользователя.
До релиза стоит проверить всего четыре вещи:
- метрики показывают долю попаданий отдельно для FAQ, поиска, саппорта и внутренних ассистентов;
- в логах видно, какой фрагмент промпта дал попадание или промах;
- при промахе система спокойно идет в модель и отвечает без лишней задержки;
- у команды есть понятное правило, кто и когда вручную сбрасывает кеш.
Ручной сброс кажется редкой операцией, но в проде он нужен постоянно. Обновили политику возврата, поменяли юридический текст, пересобрали retrieval, исправили системный промпт - старые записи нужно убрать сразу. Лучше заранее завести короткий runbook: где лежит команда, кто имеет доступ и какие сценарии нужно чистить полностью.
Что делать дальше в проде
Не раскатывайте кеширование промптов сразу на весь трафик. Возьмите один сценарий, где запросы действительно повторяются: частые вопросы в поддержке, типовые ответы менеджеру, короткие сводки по шаблону. На таком пилоте быстро видно, есть ли экономия, или кеш только добавляет скрытые ошибки.
Сначала снимите базовую линию без кеша, иначе потом не с чем будет сравнивать результат. Для пилота обычно хватает четырех метрик: цена на 1000 запросов или на один диалог, средняя задержка и p95, доля попаданий в кеш и доля ответов, которые пришлось перегенерировать.
Смотрите на эти цифры вместе. Высокая доля попаданий сама по себе ничего не значит. Если кеш попадает часто, но пользователи чаще жмут "попробовать снова", счет может не упасть, а задержка вырасти.
Дальше нужна дисциплина изменений. В проде кеш обычно ломается не из-за самой идеи, а из-за мелких правок, которые никто не отметил: обновили шаблон, поменяли TTL, добавили новый параметр в системный промпт. Через неделю команда уже не понимает, почему результаты стали хуже. Поэтому журналируйте каждое изменение шаблонов, сроков жизни, правил инвалидции и условий прогрева.
Если команде важны OpenAI-совместимый API-слой, хранение данных и биллинг внутри РФ, такой пилот удобно проверять через RU LLM. Это позволяет гонять один и тот же сценарий через разные модели и видеть логи, стоимость и эффект от кеша в одном контуре без переписывания SDK и промптов.
И последнее. Не расширяйте пилот, пока он не проживет хотя бы пару недель без сюрпризов. Если цена, задержка и качество держатся стабильно, тогда есть смысл переносить подход на соседние сценарии. Не на весь продукт сразу.
Часто задаваемые вопросы
Что лучше всего класть в кеш у LLM?
Храните в кеше только стабильные части запроса: системный промпт, длинные инструкции, шаблоны ответа и общие справочные блоки. Если этот кусок большой и вы отправляете его много раз, экономия появляется быстро.
Когда кеш почти не снижает счёт?
Обычно так бывает с короткими и редкими запросами, где почти весь текст меняется от пользователя к пользователю. Если в промпте много имен, номеров, дат и свежей истории чата, кеш почти не переиспользует записи.
Можно ли кешировать весь промпт целиком?
Нет, это плохая идея для большинства продовых сценариев. Разделите запрос на общий каркас и переменные данные, иначе вы потеряете попадания и рискуете получить чужой или устаревший ответ.
Как понять, что экономию дал именно кеш, а не что-то ещё?
Сравните пилот с контрольной группой без кеша и смотрите не только на общий счёт. Проверьте долю попаданий по каждому сценарию, число сэкономленных токенов и то, как часто пользователи просят ответить заново.
Какой TTL ставить на старте?
Начните с короткого срока жизни и дайте данным самим показать картину. Для статичных инструкций подойдут часы или дни, а для статусов, цен и остатков берите минуты или даже секунды.
Что должно входить в ключ кеша?
Берите только то, что реально меняет ответ: версию системного промпта, нормализованный текст запроса, язык, модель и режим вывода. Не добавляйте request_id, timestamp и случайные идентификаторы, иначе кеш развалится на мелкие записи.
Нужно ли включать в ключ модель и версию системного промпта?
Да, обязательно. Другая модель или новая версия системного промпта часто меняют ответ даже при том же тексте запроса, поэтому без этих полей кеш начнёт отдавать старые данные по новым правилам.
Как не сломать персонализацию в чате поддержки?
Не тяните личные поля и историю диалога в общий кешируемый слой. Держите в кеше только общие правила и шаблоны, а имя клиента, статус заказа и свежий контекст добавляйте в рабочий запрос отдельно.
Есть ли смысл прогревать кеш перед нагрузкой?
Да, если вы заранее знаете всплеск похожих запросов. Прогревайте только частые и дорогие шаблоны из реальных логов, а не персональные сценарии, иначе вы просто забьёте кеш мусором.
С чего начать пилот с кешированием в проде?
Возьмите один понятный поток, например FAQ или короткую классификацию, и неделю соберите метрики. Если счёт падает, задержка не растёт, а качество держится ровно, тогда переносите подход на соседние сценарии.