Канареечный релиз LLM: как включать трафик без сюрпризов
Канареечный релиз LLM снижает риск при смене модели: разберем этапы от 1% трафика до полного включения и понятные стоп-условия.
Почему сюрпризы у LLM видны после релиза
Канареечный релиз нужен потому, что LLM ведет себя не как обычная бизнес-логика с заранее известным результатом. Один и тот же запрос может дать немного разный ответ даже при одинаковом промпте и тех же настройках. Разница бывает маленькой, но в продакшене хватает и этого: меняется формулировка, пропадает важная деталь, ответ уходит в лишние рассуждения.
Проблема не только в фактах. Новая модель часто меняет тон, длину и формат ответа. Внутри команды это выглядит безобидно: тестовый вопрос решается, JSON вроде похож, смысл в целом сохранен. Но на живом трафике быстро всплывает то, что ручная проверка почти всегда пропускает. Модель начинает отвечать слишком многословно, ломает шаблон или добавляет текст вокруг поля, которое сервис ждет в строгом виде.
Ошибки особенно часто прячутся в длинном хвосте запросов. Пользователи пишут с опечатками, вставляют куски переписки, смешивают темы в одном сообщении, просят одно, а через фразу резко меняют контекст. На тестовом наборе таких случаев мало. В реальном потоке их много, и именно они показывают слабые места новой модели.
Если команда меняет модель через единый эндпоинт, совместимый с OpenAI, код может вообще не измениться. Это удобно, но создает ложное чувство безопасности. Снаружи релиз выглядит маленьким, а по факту меняется поведение всей цепочки: промпты, ретраи, парсеры и guardrails получают другой стиль ответа.
Сбой редко остается локальным. Если модель стала хуже извлекать сущности хотя бы в 3% диалогов, этого уже достаточно, чтобы операторы поддержки начали получать мусорные подсказки, а пользователи - странные ответы. Дальше обычно идет каскад: больше повторных запросов, выше задержка, больше ручных эскалаций и меньше доверия к релизу.
Поэтому сюрпризы у LLM почти всегда всплывают после выката, а не до него. Не потому, что команда плохо тестировала. Просто только живой трафик показывает реальное разнообразие входов и цену даже небольшого отклонения в ответе.
Что зафиксировать до первых 1%
До первых 1% трафика нужно заморозить правила игры. Иначе любая просадка потом превращается в спор: модель правда стала хуже или команда просто ожидала другого.
Сначала сформулируйте цель релиза в одном предложении. Именно в одном. Например: "Новая модель должна снизить стоимость ответа в чате поддержки на 20% без роста ошибочных эскалаций и без заметной потери качества". Такая формулировка сразу убирает лишние трактовки. Если цель звучит расплывчато, запускать канарейку рано.
Потом выберите сценарии, где новая модель обязана быть не хуже текущей. Лучше брать не "все запросы", а 3-5 понятных потоков с высоким весом: короткие FAQ-ответы, классификацию обращений, извлечение полей из текста, ответ в строгом JSON. Именно на них чаще всего ломается релиз, хотя на демо все выглядело нормально. Для каждого сценария нужен текущий ориентир: как работает старая модель, какие ответы считаются провалом и какой уровень ошибок допустим.
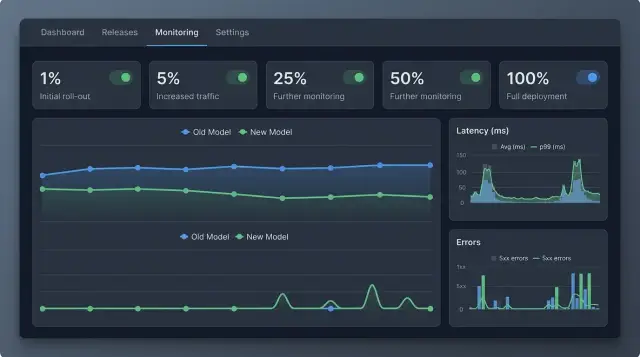
Дальше задайте пороги, после которых вы не обсуждаете ситуацию, а ставите раскатку на паузу. Обычно хватает трех групп сигналов: ошибки, задержка и стоимость. В ошибках смотрят рост 5xx, таймаутов, невалидного JSON и явно неверных ответов. В задержке важны p95 и p99, а не только среднее значение. В стоимости лучше считать цену за запрос или за 1000 успешных ответов, если ретраи случаются часто.
Порог должен быть числом, а не фразой вроде "в целом нормально". Иначе на 1% каждый прочитает графики по-своему.
Наконец, назначьте одного человека, который может остановить раскатку без созвона и долгих согласований. Это может быть владелец сервиса, дежурный инженер или ML-лид, но имя должно быть известно заранее. Когда ответственность размазана по группе, стоп-сигнал почти всегда приходит слишком поздно.
Если трафик идет через шлюз вроде RU LLM, удобно держать цель релиза, пороги и маршрут рядом. Тогда проще понять, какая модель отвечала на конкретный запрос, и быстрее вернуть прежний маршрут, если что-то пошло не так.
Как выбрать трафик для канарейки
Первые 1% должны быть скучными. Для канарейки лучше брать запросы, где ответ можно быстро проверить и где поведение модели редко уходит в сторону. Если новый маршрут сломается, вы заметите это за часы, а не после жалоб от крупных клиентов.
Хороший старт - простые и повторяемые сценарии. Подойдут короткие FAQ, классификация обращений, перефразирование стандартного текста, извлечение пары полей из однотипных сообщений. Плохой старт - длинные диалоги, свободная генерация для клиентов, юридические ответы, финансовые расчеты и все, где цена ошибки высока.
Рабочее правило простое: берите запросы с понятным ожидаемым результатом, выбирайте сегмент с низкой ценой ошибки и оставляйте только те сценарии, где старую и новую модель можно честно сравнить. Если маскирование и аудит еще не проверены, чувствительные обращения с персональными данными лучше сразу исключить.
Контрольная группа нужна с первого дня. Часть такого же трафика оставьте на старой модели, иначе вы не поймете, новая версия правда хуже или просто день выдался тяжелым: пользователи пишут длиннее, темы стали сложнее, нагрузка выросла. Для сравнения лучше держать соседние сегменты с похожим профилем, а не канарейку на одном типе клиентов и контроль на другом.
Не включайте канарейку в пик нагрузки. На максимуме система и так близка к пределу: растет задержка, чаще срабатывают ретраи, качество сильнее плавает из-за таймаутов и очередей. Если начать вечером после рассылки или утром в понедельник, вы получите шум вместо сигнала. Спокойное окно дает более честную картину.
Из первых 1% стоит убрать рискованные сценарии: обращения с оплатой, жалобы, эскалации к оператору, обработку документов с персональными данными и запросы клиентов, у которых жесткие требования к формулировкам. В российском контексте сюда часто попадают банковские и гос-сценарии. Там даже редкая ошибка быстро превращается в инцидент.
Небольшой пример. Если вы обновляете модель в чате поддержки, не отправляйте на нее сразу все новые диалоги. Сначала возьмите только вопросы про статус заказа и условия доставки, а возвраты, претензии и все, что связано с персональными данными, оставьте на старой модели.
Хорошая канарейка похожа не на лотерею, а на аккуратный лабораторный тест. Чем проще первый сегмент, тем быстрее видно, готова ли модель к следующим процентам трафика.
План раскатки по шагам
Хорошая раскатка обычно выглядит скучно. Вы даете новой модели мало трафика, быстро проверяете факты и поднимаете долю только там, где уже нет неприятных сюрпризов.
-
Начните с 1% на коротком окне. Часто хватает 30-60 минут, если трафик живой и разнообразный. В этот момент мало смотреть только на цифры. Откройте реальные ответы руками: 20-50 диалогов часто показывают проблему раньше графика.
-
Поднимайтесь до 5% только если ошибки не выросли, задержка осталась в норме, а ручная проверка не нашла странных ответов. Если модель стала чуть дешевле, но чаще уходит в отказ или путает формат, это еще не проходной результат.
-
Дальше переходите к 10-25%, но не смешивайте все сегменты в одну кучу. Проверьте отдельно короткие запросы, длинные диалоги, сообщения с таблицами, русский и английский текст, клиентов из разных продуктов. Часто модель ведет себя нормально в среднем, но сыпется на одном типе задач.
-
До 50% доходите только после двух проверок: обычный рабочий день и пиковый час. Именно на пике всплывают лишние таймауты, рост стоимости на длинных ответах и неудачные fallback-переходы. Если днем все тихо, а в 11:00 очередь растет, раскатку продолжать рано.
-
На 100% переходите после финальной сверки. Сравните новую модель со старой по качеству ответов, latency, доле ошибок, стоимости на тысячу запросов и числу ручных эскалаций. Если хотя бы один показатель заметно хуже без понятной причины, оставьте частичное включение еще на день.
Один практичный принцип помогает почти всегда: повышайте долю трафика только после полного цикла проверки на текущем уровне. Спешка на канарейке обычно стоит дороже, чем лишние полдня ожидания.
Какие сигналы смотреть на каждом шаге
На 1% трафика почти любая модель выглядит прилично. Проблемы обычно видны не в среднем значении, а в хвосте: редких промптах, длинных диалогах и ответах со строгим форматом.
Сначала смотрите на грубые сбои. Если модель чаще уходит в таймаут, дает пустой ответ или срывается в отказ там, где старая версия отвечала нормально, не ждите следующего этапа. Даже лишние 1-2% таких случаев быстро превращаются в поток ручной работы.
Потом сравните сам ответ, а не только статус 200. У новой модели часто меняется длина: она пишет слишком кратко и теряет шаги или, наоборот, раздувает ответ вдвое и тратит лишние токены. Отдельно считайте соблюдение формата: JSON, поля, порядок блоков, язык ответа, наличие обязательных дисклеймеров или тегов.
Хороший рабочий сигнал - доля ручных исправлений. Если оператору приходится чаще переписывать ответ, дополнять пропущенные данные или переводить диалог на человека, модель уже проигрывает, даже если формально отвечает без ошибок. Для поддержки и продаж это один из самых честных индикаторов.
С деньгами полезно считать не цену за токен, а цену за успешный сценарий. Новая модель может быть дешевле на входе, но чаще просить повтор, давать более длинный ответ и увеличивать число эскалаций. В итоге закрытый кейс обходится дороже.
На каждом шаге держите простые стоп-пороги: рост таймаутов и пустых ответов выше допуска, падение соблюдения формата там, где формат обязателен, рост ручных исправлений и переводов на оператора, а также рост цены за успешно закрытый запрос.
Для российских команд есть еще один слой контроля: данные. Проверьте, что маскирование PII срабатывает до записи логов, а аудит сохраняет маршрут запроса, модель и версию промпта. Если у команды есть требования по 152-ФЗ, такие проверки лучше делать прямо на канарейке, а не после полного включения. В RU LLM это удобно смотреть на уровне самого шлюза: логирование, хранение данных в РФ и служебные метки вроде AI-Law идут вместе с маршрутом запроса.
Нормальная картина на 1%, 5% и 20% должна быть похожей. Если метрики держатся только на малом объеме, это не успех, а отложенная проблема.
Когда раскатку надо остановить сразу
Останавливать раскатку нужно не тогда, когда "стало немного хуже", а когда новая модель уже ломает рабочий сценарий. Даже на 1-5% трафика это видно быстро. Если модель путает обязательные поля, меняет формат ответа, теряет JSON или подставляет неверный статус, дату, сумму или идентификатор, дальше раскатывать нельзя. Один такой сбой редко выглядит страшно в отчете, но на практике ломает цепочку из API, очередей и ручных проверок.
То же правило действует для задержки. Если p95 или p99 вышли за лимит, при котором чат зависает, оператор ждет подсказку слишком долго, а внешний сервис начинает тайм-аутить, раскатку надо ставить на паузу сразу. Для LLM лишние 2-4 секунды часто значат уже сломанный продуктовый шаг.
С качеством ответов лучше смотреть не на среднюю оценку, а на поведение пользователей. Если растут повторные обращения по той же теме, эскалации на человека или ручные правки операторов, модель делает хуже, даже если часть ответов выглядит аккуратно. В поддержке это обычно видно раньше, чем в формальной метрике качества.
Есть несколько признаков, при которых спорить не о чем:
- ответ раскрыл лишние персональные или служебные данные;
- модель начала смешивать данные разных клиентов или диалогов;
- формат ответа перестал проходить валидацию и ломает интеграцию;
- команда не может откатить маршрут на прошлую модель за несколько минут.
Последний пункт многие недооценивают. Если откат занимает полчаса, у вас нет нормальной канарейки. У вас рискованный релиз. В схеме с маршрутизацией через единый LLM-шлюз откат должен сводиться к быстрому возврату прежней модели или версии без переписывания кода. Если такого пути нет, не поднимайте долю трафика выше минимума.
Простой пример: новая модель в чате поддержки отвечает чуть точнее, но иногда пропускает обязательное поле "номер заказа" и раз в несколько сотен запросов выводит фрагмент внутреннего комментария. На графике это может выглядеть как мелочь. Для раскатки это стоп-сигнал. Сначала откат, потом разбор логов, проверка маскирования данных и повторный запуск на малой доле трафика.
Пример: новая модель в чате поддержки
Интернет-магазин меняет модель в чате поддержки не на всем потоке, а на одном простом сценарии: запросы о статусе заказа. У таких диалогов понятная цель, короткий путь до ответа и мало спорных трактовок. Это хороший полигон для канарейки.
Возвраты, споры по списанию, жалобы на курьера и другие нестандартные случаи команда сразу оставляет на старой модели. Там цена ошибки выше: один неточный ответ быстро превращается в повторный контакт, негатив и ручной разбор. Канарейка должна проверять новую модель там, где риск ниже, а сигнал чище.
Допустим, компания начинает с 1% запросов о статусе заказа. Новая модель отвечает только в этом сегменте, а команда каждый день сравнивает ее со старой по двум вещам: насколько точно она отвечает и сколько времени уходит до решения вопроса. Если клиент получил номер заказа, дату доставки и не вернулся в чат через пять минут с тем же вопросом, это хороший знак.
Через несколько дней картина обычно становится понятнее. Команда смотрит не только на средние значения, но и на хвосты: где модель ошибается, путает отмененный заказ с отгруженным или отвечает слишком общо вместо конкретного статуса.
Как выглядит такая раскатка
- 1% трафика: только запросы о статусе заказа и только в дневные смены;
- 5%: тот же тип запросов, но уже на всем рабочем дне;
- 15%: добавляются смежные вопросы, например сроки доставки;
- 30% и выше: только если метрики не хуже базовой модели.
Пауза нужна сразу, если растет доля переводов на оператора. Это удобный ранний сигнал: клиент еще не успел оставить жалобу, но уже видно, что модель не закрывает задачу сама. Например, раньше оператор подключался в 11% таких диалогов, а после включения новой модели доля выросла до 15%. При таком сдвиге раскатку лучше заморозить, разобрать логи и понять, где модель теряет контекст.
Если команда управляет маршрутизацией через единый LLM-шлюз, такой сценарий проще держать под контролем: можно направить в канарейку только один интент, быстро откатить его назад и не трогать остальной трафик. Для поддержки это часто спокойнее, чем большой релиз одним днем.
Ошибки, которые ломают канарейку
Чаще всего канарейка разваливается не из-за самой модели. Команда ломает эксперимент своими руками. Самая частая ошибка - в один день менять модель, системный промпт и парсер ответа. После этого никто уже не понимает, что дало сбой: генерация, формат JSON или новая инструкция.
Поэтому правило простое: один этап - одно изменение. Медленнее, зато потом не нужно гадать по логам.
Вторая ошибка - смотреть только на средние цифры. Средняя задержка может выглядеть нормально, а в хвосте p95 и p99 уже ползут вверх. То же самое с качеством: средний score не падает, но у сложных запросов растет число отказов, пустых ответов или странных рассуждений. Пользователи чувствуют именно эти плохие хвосты, а не красивую среднюю строку в дашборде.
Третья ловушка - сравнивать модели на разном трафике. Если старая модель отвечает на простые запросы утром, а новая получает спорные кейсы вечером, выводы будут мусорными. Дайте обеим моделям один и тот же тип запросов. Лучше всего работает стабильное разбиение по пользователю, диалогу или хешу запроса.
Еще одна ошибка - экономить на логах. Для разбора мало знать, что ошибка выросла с 1,2% до 2,1%. Нужны сами запросы, версия промпта, версия парсера, длина контекста, число ретраев и причина сбоя. Если логов мало, команда спорит на уровне ощущений. Если логов достаточно, она находит конкретные плохие кейсы за полчаса.
Отдельно канарейку ломают длинные диалоги и вечерний пик. На коротких тестах новая модель может выглядеть лучше, а на 12-м сообщении вдруг терять контекст, повторяться или уходить в отказ. Вечером добавляется еще и нагрузка: растет задержка, чаще срабатывают таймауты, парсер получает обрезанные ответы.
Перед следующим процентом трафика убедитесь в пяти вещах: менялась только одна часть цепочки, обе модели видят одинаковый поток, метрики есть не только в среднем, но и в p95 и p99, логов хватает для ручного разбора, а в выборке есть длинные диалоги и часы пика.
Канареечный релиз редко ломает одна большая проблема. Обычно это набор мелких допущений, которые сложились в плохое решение.
Быстрый чек-лист перед полным включением
Полное включение чаще ломают не крупные ошибки, а мелкие допущения: кто-то не уточнил порог отката, кто-то посмотрел только на среднее время ответа, а ручную проверку диалогов отложили "на потом". За час до 100% трафика такие вещи уже должны быть закрыты.
Если канарейка дошла до финального шага, это еще не значит, что модель готова для всех. Последняя проверка нужна не для галочки. Она нужна, чтобы не чинить прод после первого всплеска нагрузки.
Сначала проверьте стоп-условия. Нужны конкретные числа: рост ошибок, просадка по качеству, увеличение задержки, скачок эскалаций на оператора. И нужен один ответственный, который говорит "стоп" без долгих согласований.
Потом посмотрите на срезы, а не только на общую картину. Разберите данные по часам, каналам и сегментам: веб, мобильный канал, поддержка, продажи, новые и старые пользователи. Средняя цифра часто прячет провал в одном сегменте.
Обязательно прочитайте реальные диалоги руками. Хотя бы несколько десятков из разных сценариев. Дашборд покажет latency и error rate, но не поймает странный тон, лишние отказы, потерю контекста или поломку вызова инструментов.
После этого проверьте всю цепочку под нагрузкой: парсеры, ретраи, лимиты, таймауты и правила маршрутизации. Часто новая модель отвечает чуть длиннее или медленнее, и ломается не она сама, а соседний сервис.
И последнее: откат должен быть проверен на практике. Он должен занимать минуты. Если для возврата нужно менять клиентский код или собирать новый релиз, это плохой план.
Что делать после полного включения
Полное включение не значит, что старую модель можно убирать в тот же день. Оставьте ее как запасной маршрут хотя бы на несколько дней. Если вскроется редкий сбой, вы сможете быстро вернуть часть трафика назад, а не откатывать все сразу.
Часто проблемы приходят не в первый час, а позже. Днем трафик один, ночью другой. В будни больше рабочих запросов, в выходные - больше длинных и нестандартных диалогов. Поэтому еще 1-2 недели смотрите на те же сигналы, что и во время канарейки: долю ошибок, задержку, цену полезного ответа, число эскалаций на человека и жалобы по конкретным сценариям.
Полезно завести отдельный список запросов, где новая модель все еще проигрывает прошлой. Не общий вывод вроде "хуже пишет", а короткие группы: возвраты, спорные платежи, длинные цепочки уточнений, ответы с цитированием правил. Такой список потом экономит много времени. Вместо споров в чате команда получает набор реальных примеров для следующего теста.
Если вы меняете провайдеров через единый эндпоинт, совместимый с OpenAI, переводить доли трафика заметно проще. Для команд, которые работают через RU LLM, это обычно значит, что можно менять маршрут на api.rullm.com без правок в SDK, коде и промптах. После полного включения это особенно удобно: можно быстро вернуть 10-20% старой модели для проверки гипотезы или сравнить двух провайдеров на одном потоке.
После раскатки полезно сделать четыре вещи: держать прошлую модель готовой к возврату части трафика, еще 7-14 дней смотреть на метрики без послаблений, собирать реальные проигрышные кейсы новой модели и записать, что сработало в схеме включения, а что мешало.
Последний пункт часто пропускают, и зря. Если во время канарейки вы поняли, что 5% трафика уже дают достаточно сигнала, не возвращайтесь в следующий раз к долгому этапу на 1%. Если стало ясно, что средняя задержка вас обманывает, добавьте перцентили и разбор по типам запросов. Хорошая канарейка - это не только безопасный релиз сегодня, но и более спокойный релиз через месяц.
Часто задаваемые вопросы
Что такое канареечный релиз LLM простыми словами?
Это запуск новой модели на маленькой доле живого трафика, а не сразу на всех пользователях. Смысл простой: сначала проверить ответы, задержку, формат и цену на реальных запросах, а потом уже поднимать долю.
Почему нельзя просто заменить модель, если эндпоинт остался тем же?
Потому что меняется не только модель, но и ее поведение. Даже при том же base_url она может писать длиннее, ломать JSON, чаще уходить в отказ или тянуть больше токенов.
С какого объема трафика лучше начинать?
Обычно начинают с 1% в спокойное окно, когда команда может быстро смотреть логи и живые диалоги. Этого хватает, чтобы поймать грубые сбои до того, как они затронут весь сервис.
Какой трафик подходит для первых 1%?
Берите короткие и повторяемые сценарии с низкой ценой ошибки. Для старта подходят FAQ, простая классификация и извлечение пары полей; возвраты, жалобы, финансовые расчеты и чувствительные данные лучше оставить на старом маршруте.
Какие сигналы важнее всего на канарейке?
Смотрите на таймауты, пустые ответы, невалидный JSON, p95 и p99 задержки, цену успешного сценария и долю ручных правок. Отдельно проверяйте длину ответа, обязательные поля и соблюдение нужного формата.
Когда rollout надо остановить без обсуждений?
Ставьте раскатку на паузу сразу, если модель ломает обязательный формат, путает статусы, даты, суммы или идентификаторы, раскрывает лишние данные или заметно увеличивает задержку. Если клиентский путь уже ломается, ждать новых графиков не нужно.
Зачем нужна контрольная группа, если метрики и так есть?
Да, без нее вы не поймете, проблема в новой модели или в самом дне: нагрузка выросла, запросы стали длиннее, темы усложнились. Держите рядом похожий сегмент на старой модели и сравнивайте одинаковые сценарии.
Как организовать быстрый откат?
Откат должен занимать минуты, а не полчаса. Лучше заранее держать прошлый маршрут готовым и переключать модель на уровне шлюза или маршрутизации, без правок в клиентском коде и нового релиза.
Что делать после полного включения новой модели?
Не убирайте старую модель сразу. Еще несколько дней держите ее как запасной маршрут, следите за теми же метриками и собирайте реальные провальные кейсы, чтобы понять, где новая версия все еще проигрывает.
Как учесть персональные данные и 152-ФЗ при канареечном релизе?
Проверьте, что маскирование PII срабатывает до записи логов, а аудит сохраняет маршрут, модель и версию промпта. Если у вас есть требования по 152-ФЗ, не откладывайте эти проверки до полного включения: их нужно пройти уже на канарейке.