Почему JSON-ответы ломаются в продакшене и как чинить
Почему JSON-ответы ломаются в продакшене: разберём длинный контекст, tool calls, конфликт инструкций и проверки, которые ловят сбои до релиза.
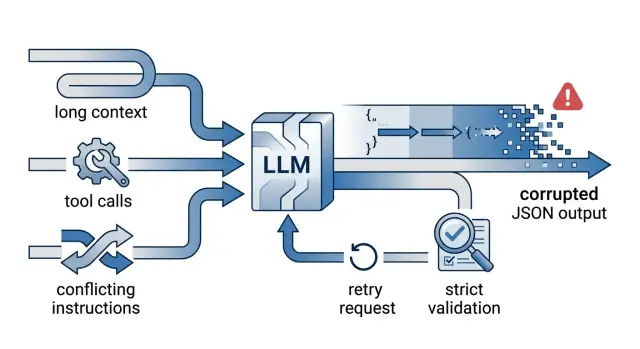
Что именно ломается
Команда почти никогда не сталкивается с одной и той же поломкой. Сегодня модель добавила фразу перед JSON, завтра забыла закрыть массив, послезавтра вернула поле не того типа. Снаружи это выглядит как случайность, но у таких сбоев обычно есть повторяющийся рисунок.
Вопрос "почему JSON-ответы ломаются в продакшене" обычно появляется не после первого сбоя, а после десятого. До этого баг кажется мелочью: один лишний символ, одна лишняя кавычка, один блок json. Но для цепочки сервисов этого достаточно. Парсер падает, валидатор молчит, роутинг не срабатывает, а следующий сервис получает пустой объект или старые данные.
Обычно поломки выглядят так:
- текст до или после JSON, например короткий комментарий модели
- незакрытые скобки, кавычки или массивы после длинного ответа
- формально верный JSON с неверной схемой:
idстрокой вместо числа,itemsобъектом вместо массива - пропущенные обязательные поля или
nullтам, где код ждет объект - смесь двух форматов, когда часть ответа уходит в tool call, а часть - в обычный текст
Один лишний символ роняет цепочку по простой причине: автоматический процесс не "понимает намерение". Он не догадывается, что модель почти попала в формат. Если сервис ждет чистый JSON, то даже безобидная строка вроде "Готово:" уже меняет тип ответа. Для человека это мелочь. Для машины - другой контракт.
Разовый сбой и системная причина в логах часто выглядят одинаково. Разовый сбой обычно не повторяется на том же входе и не группируется по сценарию. Системная причина проявляется при длинных диалогах, при вызове конкретного инструмента, на одной модели или на одном шаблоне промпта. Если команда видит одинаковый класс ошибок в похожих запросах, дело уже не в невезении.
Понять, что проблема не в парсере, можно быстро. Сохраните сырой ответ до любой обработки и проверьте его отдельно. Если в сыром теле уже есть лишний текст, обрыв JSON или дрейф схемы, парсер ни при чем. Еще один признак: один и тот же парсер стабильно читает тестовые ответы, но падает только на живых ответах модели. Значит, ломается не чтение JSON, а сам контракт между моделью и вашим кодом.
Как длинный контекст сбивает JSON
Чем длиннее вход, тем хуже модель держит жесткий формат. Она пытается учесть сразу все: историю чата, куски документации, примеры, системные правила, новые сообщения. В какой-то момент схема JSON перестает быть для нее главным ограничением и становится одной инструкцией среди многих.
Это хорошо видно в длинных цепочках, где команда сначала просила свободный текст, потом добавила JSON-схему, а потом вставила еще пару примеров с обычными ответами. Модель не всегда выбирает последнее правило. Часто она смешивает старые указания с новыми и выдает гибрид: немного текста, потом JSON, а после него еще одно пояснение.
Шум в истории чата делает проблему хуже. Логи, отладочные сообщения, длинные цитаты прошлых ответов, служебные заметки - все это отнимает место у короткой и строгой инструкции по формату. Если правило "отвечай только валидным JSON" стоит в начале, а после него идут сотни строк нерелевантного контента, модель чаще нарушает формат.
Есть и совсем приземленная причина: большой ответ чаще обрывается. Когда модель генерирует длинный JSON с массивами, вложенными объектами и длинными строками, она упирается в лимит токенов или таймаут. Итог обычно один и тот же: нет последней фигурной скобки, не закрыт массив, строка оборвана на середине.
На практике это выглядит довольно скучно. Модель добавляет вводную фразу перед JSON, одно поле внезапно превращает в абзац текста, подхватывает старый формат из предыдущего шага или теряет закрывающие скобки. Иногда структура вроде бы сохраняется, но парсер уже не может ее прочитать.
Типичный пример: команда просит модель разобрать длинную переписку клиента, правила продукта и внутренние комментарии менеджера, а на выходе ждет компактный JSON для CRM. Пока контекст короткий, все работает. Когда в запрос попадает 30-40 сообщений, ответ вдруг начинает "разговаривать", теряет обязательное поле или обрывается на последнем объекте.
Если коротко, длинный контекст ломает JSON не магией, а перегрузкой. Модель видит слишком много сигналов сразу и хуже держит одно простое требование: вернуть строго валидную структуру без лишнего текста.
Где tool calls ломают структуру
С tool calls JSON чаще ломается на стыке двух задач: модель должна ответить человеку и одновременно собрать аргументы для инструмента. Если промпт не разделяет эти роли жестко, модель начинает смешивать их в одном сообщении. В итоге часть данных попадает в arguments, а часть уходит в обычный текст.
Частый сбой выглядит так: модель вызывает инструмент, но рядом пишет "Я нашла заказ и сейчас передам данные". Для интерфейса это безобидная фраза. Для парсера это уже мусор вне схемы. Один лишний абзац после JSON, и следующий шаг цепочки падает.
Еще неприятнее случай, когда нужные поля есть, но лежат не там. Например, инструмент ждет order_id и email внутри arguments, а модель кладет order_id в аргументы, а email пишет в текст ответа. Человек этого даже не заметит. Система заметит сразу, потому что инструмент получит неполные данные.
Проблема усиливается, когда у вас несколько инструментов с разными требованиями. Один ждет дату строкой в формате YYYY-MM-DD, другой принимает Unix timestamp, третий хочет массив объектов вместо строки. Модель легко переносит формат из прошлого вызова в новый, особенно если в истории уже были похожие примеры.
В продакшене это часто всплывает после смены модели. Команда оставляет тот же OpenAI-совместимый клиент, тот же код и те же tool definitions, но новая модель иначе понимает границу между текстом и аргументами. Если трафик идет через единый шлюз к нескольким провайдерам, например через RU LLM, такие различия становятся особенно заметны: контракт у вас один, а привычки у моделей разные.
Обычно структура ломается в четырех точках:
- модель пишет человеческий ответ и JSON в одном сообщении
- часть полей переносит из
argumentsвcontent - после tool call добавляет пояснение, которого схема не ждет
- путает типы и формат полей между разными инструментами
Самая дорогая ошибка здесь - не "битый JSON", а тихая порча данных. Парсер может проглотить ответ, инструмент выполнится, но с пустым параметром, неверной датой или обрезанным списком. Снаружи все выглядит почти нормально. Через час команда уже ищет баг не в tool calls, а в бизнес-логике.
Почему инструкции спорят друг с другом
LLM редко ломает JSON "сама по себе". Намного чаще команда дает ей сразу несколько правил, которые тянут ответ в разные стороны. Одна часть стека требует строгий объект без лишнего текста, другая просит объяснить выбор, а третья добавляет "ответь понятно для человека". Модель пытается выполнить все сразу и смешивает форматы.
Обычно конфликт сидит в слоях промпта. System пишет: "верни только JSON". Developer добавляет: "коротко объясни решение". User просит: "если есть риск, напиши комментарий". После этого в ответе легко появляются абзац перед объектом, поле comment, Markdown-обертка или текст после закрывающей скобки.
Проблему усиливают старые шаблоны. Команда меняет схему, но забывает обновить примеры в подсказке. В схеме уже есть risk_level и нет confidence, а пример все еще показывает старые поля. Модель видит оба варианта и часто отдает смесь: правильную структуру с лишним полем, старое имя поля или даже два похожих поля сразу.
Такое часто всплывает после миграций. Команда переводит трафик на OpenAI-совместимый шлюз, сохраняет SDK и код без изменений, но тянет за собой старый набор промптов из разных сервисов. Формат запроса остается знакомым, а инструкции внутри уже давно противоречат друг другу. На тестах это может не проявиться, потому что короткие и простые запросы модель переживает легче.
Нечеткие формулировки тоже ломают структуру. Фразы вроде "верни JSON в удобном виде", "при необходимости добавь пояснение" или "можешь включить дополнительные поля" звучат безобидно, но для модели это прямое разрешение выйти за схему. Потом парсер падает не на сложной логике, а на банальном "note": "...".
Как убрать конфликт
Сначала сведите правила в одно место и выберите один источник правды для схемы. Если формат важнее тона ответа, это правило должно стоять выше остальных и без двусмысленности. Дальше все довольно прямолинейно: оставьте одно жесткое требование "верни только JSON по схеме", уберите просьбы "объясни", если объяснение не входит в схему, и генерируйте примеры из текущей версии схемы, а не из старого документа. Отдельно запретите лишние поля, комментарии и Markdown. И обязательно тестируйте весь стек целиком - system, developer и user, а не каждый слой по отдельности.
Хороший промпт не пытается быть одновременно вежливым, полезным для человека и строго машинным. Если нужен и JSON, и человеческое объяснение, разделите это на два шага. Иначе модель почти всегда попробует склеить их в один ответ, а продакшен потом разберется с последствиями.
Как слабая валидация пропускает сбои
JSON может успешно распарситься и все равно сломать бизнес-логику. Если вы разбираете, почему JSON-ответы ломаются в продакшене, проблема часто не в модели, а в том, что система проверяет ответ слишком поверхностно.
Самая частая ошибка проста: команда делает только parse check. Если строка превратилась в объект, ответ считают годным. Но {"status":"ok","email":"","items":[]} формально валиден и при этом бесполезен. Пустые строки, null вместо текста, пустой массив там, где нужен хотя бы один элемент, парсинг не ловит.
Схема тоже часто существует только для вида. Поля описаны, но типы не зажаты, обязательные значения не отмечены, допустимые enum не заданы. В итоге модель один раз вернет число, второй раз строку, третий раз вложенный объект вместо плоского поля. Все это пройдет дальше по цепочке и всплывет уже в CRM, биллинге или отчете для клиента.
Хуже всего, когда команда не разделяет retry и hard fail. Если JSON сломан синтаксически, можно попросить модель пересобрать ответ или запустить второй проход. Если JSON синтаксически нормальный, но в нем нет обязательного поля customer_id, повтор не всегда поможет. Здесь системе нужен hard fail с понятной причиной, а не три бесполезных ретрая, которые тратят токены и время.
Нормальная валидация проверяет несколько вещей подряд:
- синтаксис JSON
- схему: типы, обязательные поля, enum, длину массивов
- бизнес-правила: пусто ли поле, есть ли минимальный набор данных
- маршрут ошибки: retry, repair или hard fail
Еще одна частая дыра в продакшене - отсутствие сырого ответа в логах. Команда сохраняет только ошибку парсера или уже очищенный объект. Потом инцидент нельзя разобрать: вы не видите, добавила ли модель лишний текст, обрезался ли ответ по длине, вмешался ли tool call. Сырые ответы, trace id и причина отказа заметно экономят время.
На практике это выглядит так: сервис получает JSON для создания заявки, парсинг проходит, схема молчит, а поле phone приходит пустым. Заявка уходит дальше, оператор не может связаться с клиентом, и ошибка всплывает через день. Если бы проверка считала пустой phone невалидным и сразу останавливала поток, сбой нашли бы за минуту.
В системах вроде RU LLM такой разбор проще, когда у каждого запроса есть аудит-трейл и понятные логи. Но даже с хорошим шлюзом правило остается тем же: проверяйте не только форму JSON, а смысл каждого поля.
Простой сценарий из продакшена
Представьте обычный поток: сервис читает письмо клиента и вытаскивает из него дату, номер заказа, сумму и короткий комментарий для CRM. Модель отвечает почти правильно. На вид это JSON, и в логах все спокойно.
Проблема прячется в одной строке. Например, поле date приходит как "2025-04-18 9:7" вместо ожидаемого формата "2025-04-18T09:07:00", или модель забывает закрывающую кавычку. Человек такой ответ еще поймет. Следующий парсер - уже нет.
Дальше сбой обычно идет по скучному сценарию. Оркестратор получает ответ и видит, что текст "почти похож" на JSON. Вместо жесткой ошибки он пытается распарсить объект частично или подставляет null в сломанное поле. Следующий сервис считает, что структура валидна, и отправляет данные в CRM. А CRM падает не сразу, а на своей проверке даты, создании сделки или записи в историю клиента.
Из-за этого команда ищет баг не там. Кажется, что CRM иногда ломается случайно, хотя причина появилась на первом шаге. Этот пример хорошо показывает, почему JSON-ответы ломаются в продакшене: ошибка возникает рано, а замечают ее слишком поздно.
Хуже всего то, что такие сбои трудно ловить глазами. В тестах письмо могло быть коротким и простым. В бою приходит длинная переписка с подписью, пересланными фрагментами и двумя датами в одном абзаце. Модель выбирает не ту дату, слегка портит формат, а остальная цепочка молча пропускает ответ дальше.
Если вы работаете через единый LLM-шлюз, проблема не исчезает сама собой. Меняется маршрут до модели, но дисциплина в цепочке все равно нужна: строгая схема, явная проверка даты, отказ при невалидном ответе и понятный лог на месте сбоя. Иначе одна битая строка превращается в "случайную" ошибку уже в бизнес-системе.
Как собрать устойчивый пайплайн по шагам
Если разбирать, почему JSON-ответы ломаются в продакшене, почти всегда проблема не в одной модели, а в цепочке вокруг нее. Хороший результат дает не "умный промпт", а простой процесс, где каждый шаг проверяет предыдущий.
Начните со схемы. Она должна быть короткой и однозначной. Если поле может быть только числом, так и пишите. Если поле обязательно, не прячьте это в длинной инструкции рядом с десятком исключений. Чем больше правил вы смешиваете в одном сообщении, тем чаще модель начинает спорить сама с собой.
Потом разделите режимы работы. Когда вам нужен обычный текст, не требуйте JSON "на всякий случай". Когда нужен JSON, уберите лишние объяснения и просите только структуру. Эта граница сильно снижает шум, особенно если в запросе уже есть длинный контекст, история диалога и служебные подсказки.
Рабочая схема обычно выглядит так:
- Отдельный запрос для структурированного ответа с одной схемой.
- Отдельный запрос для текста, если пользователю нужен комментарий или пояснение.
- Проверка типов, обязательных полей и допустимых значений сразу после ответа.
- Короткий retry, если проверка нашла сбой.
- Сохранение сырого ответа и результата проверки в логах.
На этапе проверки не ограничивайтесь парсингом. Модель может вернуть формально корректный JSON, но положить строку туда, где вы ждете массив, или пустой объект вместо нужных полей. Поэтому валидация JSON для LLM должна ловить и синтаксис, и смысл структуры.
Retry тоже нужен простой. Не отправляйте весь исходный контекст заново. Лучше вернуть модели короткую причину: "поле status отсутствует" или "price должен быть числом". Такой повторный запрос чаще чинит ответ, чем длинное нравоучение на 20 строк.
Последний слой многие пропускают, и зря. Сохраняйте сырой ответ модели, итог разбора и текст ошибки валидатора. Без этого команда видит только факт сбоя, но не понимает, где именно развалилась цепочка: в промпте, в tool calls, в роутинге или в коде парсера.
Если вы отправляете запросы через единый OpenAI-совместимый endpoint, например через RU LLM, этот подход не ломает текущий стек. Можно оставить SDK и код, а устойчивость добавить вокруг вызова модели: схема, валидатор, короткий retry, логи. Обычно этого хватает, чтобы случайные поломки превратились в редкие и понятные ошибки.
Ошибки, которые команды повторяют
Если команда не видит, почему JSON-ответы ломаются в продакшене, причина часто довольно скучная: контракт существует только в голове у разработчика, а не в системе. Модель получает слишком много задач сразу, примеры устаревают, а проверка ловит только явный мусор.
Самая частая ошибка - запихнуть в один промпт все сразу: формат ответа, тон текста, правила бизнеса и исключения. В такой смеси инструкции начинают спорить. Модель то пишет обычный текст, то честно пытается вернуть JSON, то вставляет пояснение между полями. Особенно часто это случается в поддержке и бэк-офисе, где один и тот же вызов должен и классифицировать запрос, и подготовить ответ клиенту.
Не лучше и другая привычка: команда меняет схему, но забывает обновить примеры. В коде поле уже называется customer_id, а few-shot все еще показывает clientId. Модель цепляется за пример, потому что он конкретнее абстрактного описания. Потом разработчики долго ищут баг в парсере, хотя проблема в старом образце прямо в промпте.
Отдельная ловушка - терпимость к null там, где поле обязано быть строкой. На тестах это кажется безобидным. В продакшене такой ответ проходит один сервис, ломает второй и тихо портит аналитику в третьем. Если поле должно быть строкой, пусть модель вернет пустую строку, код ошибки или явный статус отсутствия данных. Смешивать эти варианты не стоит.
Retry тоже часто понимают слишком широко. Если причина в конфликте инструкций или в старой схеме, повторный запрос не лечит ошибку. Он только тратит бюджет и повышает нагрузку. В мультипровайдерной схеме это особенно заметно: разные модели повторят один и тот же дефект по-разному, и отладка станет только мутнее.
Еще одна типичная ошибка - тестировать только счастливый сценарий на коротких запросах. Настоящие сбои приходят позже: длинная переписка, вставленный лог, ответ инструмента с кавычками внутри, обрезанный контекст.
Обычно хватает пяти дисциплин:
- разделять формат, стиль и бизнес-логику по разным шагам
- версионировать схему и примеры вместе
- не принимать
nullбез явного смысла - делать retry только для временных сбоев
- гонять тесты на длинных, шумных и неудобных входах
Команды редко падают из-за одной большой ошибки. Обычно их добивает набор мелких допущений, которые по отдельности кажутся разумными.
Быстрая проверка перед релизом
Перед релизом нужен не большой тест-план, а короткий прогон по реальным отказам. Если JSON ломается в бою, проблема обычно не в одном лишнем символе, а в цепочке: модель ответила неровно, код это проглотил, retry спрятал сбой, а логов не хватило, чтобы быстро понять причину.
Здесь лучше работает жесткая проверка на нескольких живых примерах, а не подход "визуально вроде нормально". JSON должен парситься сразу, обычным парсером, без ручной чистки, без обрезки префиксов и без эвристик вроде "если модель дописала пояснение, отбросим первую строку". Если без таких костылей не выходит, релиз рано выкатывать.
Перед выпуском проверьте пять вещей:
- Прогоните набор входов, где модель часто ошибается: длинный контекст, пустые поля, tool calls, конфликтующие инструкции. Смотрите только на результат парсера. Любой ответ, который требует ручной постобработки, считайте дефектом.
- Проверьте схему целиком. Недостаточно того, что JSON формально валиден. Все обязательные поля должны приходить всегда, и каждый тип должен совпадать: число остается числом, массив не превращается в строку,
nullприходит только там, где вы это разрешили. - Отловите текст вне JSON. Модель любит добавить объяснение до объекта или после него. Такой ответ часто проходит в демо и ломает интеграцию в продакшене. Тест должен падать сразу, если есть хоть один лишний символ.
- Отключите retry и посмотрите на первую ошибку. Повторный запрос иногда делает вид, что все хорошо, но на деле он маскирует системную поломку в промпте, схеме или маршруте модели.
- Проверьте логи. За минуту вы должны поднять raw-ответ, request id, версию промпта, версию схемы и модель, которая вернула сбой. Если этого нет, разбор инцидента затянется на часы.
Отдельно полезно сделать один тест с боевым маршрутом, а не только с локальной заглушкой. Валидация JSON для LLM часто кажется надежной до тех пор, пока реальный провайдер не вернет обрезанный ответ или не смешает tool calls и текст.
Если трафик идет через RU LLM, не теряйте аудит-трейл на тестовом контуре. По нему проще понять, какой запрос ушел, что вернулось назад и где именно структура съехала. Это скучная часть релиза, но именно она потом экономит ночные созвоны.
Что сделать дальше
Если вы уже поняли, почему JSON-ответы ломаются в продакшене, не пытайтесь чинить все сразу. Лучше сузить задачу: возьмите один JSON-контракт и один короткий набор проверок, который команда сможет гонять каждый день.
Начните с простой схемы. Не с самой полной, а с той, без которой ответ уже нельзя принять: обязательные поля, типы, допустимые enum, поведение на null и пустых строках. Это быстро покажет, где у вас ошибка модели, а где ошибка вашей цепочки.
Дальше соберите маленький набор входов. Ему не нужна огромная выборка. Хватит 15-20 примеров, если они бьют по разным слабым местам:
- длинный запрос с лишним контекстом
- ответ после tool call
- пустые или необязательные поля
- конфликтующие инструкции в system и user
- редкий, но реальный случай из логов
Проверяйте эти сценарии отдельно, а не одной общей пачкой. Иначе вы увидите только факт сбоя, но не поймете причину. На практике длинный контекст, tool calls и пустые поля ломают структуру по-разному, и чинятся они тоже по-разному.
Параллельно настройте метрики. Минимальный набор такой: доля невалидных ответов, доля retry, среднее число retry до успеха и доля случаев, где после retry JSON все равно не проходит схему. Если число невалидных ответов растет даже на 1-2%, это уже повод смотреть логи и конкретные промпты, а не ждать жалоб от пользователей.
Если у вас есть требования к логам в РФ, аудиту запросов и единой точке подключения к моделям, это удобно вынести в отдельный слой. В RU LLM команды могут оставить свои SDK, код и промпты, а маршрутизацию, аудит-трейлы и хранение логов в РФ держать централизованно через один OpenAI-совместимый шлюз. Само по себе это не исправит плохую схему, но заметно упростит контроль, отладку и повторяемость.
Хороший следующий шаг очень приземленный: выбрать один боевой endpoint, добавить строгую схему, 20 тестовых входов и метрики на неделю. Через несколько дней станет ясно, где у вас ломается JSON на самом деле.
Часто задаваемые вопросы
Почему JSON ломается, хотя в тестах все работало?
Чаще всего тесты гоняют короткие и чистые входы, а в бою прилетают длинные переписки, шум из истории и спорящие инструкции. Модель отвечает почти правильно, но добавляет фразу перед объектом, теряет скобку или меняет тип поля, и цепочка падает уже дальше по ходу.
Как быстро понять, что виноват не парсер?
Сохраните сырой ответ модели до любой очистки и разберите его отдельно. Если в нем уже есть лишний текст, обрыв строки или поле не того типа, парсер тут ни при чем — ломается сам контракт между моделью и кодом.
Почему длинный контекст так часто портит JSON?
Длинный контекст перегружает модель. Она пытается держать в голове историю чата, правила, примеры и новый запрос сразу, поэтому строгий формат перестает быть для нее главным ограничением. Отсюда берутся вводные фразы, гибрид текста и JSON и обрывы на конце ответа.
Где чаще всего ломаются tool calls?
Проблема обычно появляется на стыке текста и аргументов инструмента. Модель кладет часть полей в arguments, а часть пишет в content, или добавляет человеческое пояснение рядом с вызовом. Для интерфейса это терпимо, для автоматики — уже сбой.
Что делать, если инструкции спорят друг с другом?
Сведите правила к одному простому требованию и уберите все, что тянет ответ в сторону обычного текста. Если нужен только JSON, не просите объяснение, комментарий и вежливый ответ в том же сообщении. Если нужен и JSON, и текст, разделите это на два запроса.
Почему формально валидный JSON все равно ломает бизнес-логику?
Потому что синтаксис — это только первая проверка. JSON может успешно распарситься и при этом принести пустой phone, строку вместо массива или дату в неожиданном формате. Система должна проверять не только форму, но и смысл полей.
Когда retry полезен, а когда он только тратит токены?
Повтор помогает, когда ответ сломан случайно: не закрылся массив, пропало поле или модель сорвалась в текст. Если причина в старой схеме, плохом примере или конфликте инструкций, retry почти ничего не чинит и только тратит токены. В таком случае лучше сразу остановить поток и вернуть понятную ошибку.
Какие логи нужны, чтобы быстро разобрать сбой?
Держите у каждого запроса сырой ответ, request_id, версию промпта, версию схемы, имя модели и причину отказа валидатора. Тогда команда видит, где именно все сломалось: в ответе модели, в tool call или уже после разбора.
Как быстро проверить JSON-пайплайн перед релизом?
Прогоните несколько живых сценариев без ручной чистки ответа. JSON должен парситься обычным парсером, без обрезки префиксов и без эвристик. Потом проверьте схему целиком, отключите retry и посмотрите на первую ошибку — она чаще всего и показывает настоящую причину.
Поможет ли смена модели или шлюза сама по себе?
Не само по себе. Новая модель может иначе держать границу между текстом и структурой, а шлюз меняет маршрут, но не чинит слабую схему и плохую валидацию. Рабочий путь проще: оставить текущий стек и добавить вокруг вызова строгую схему, короткий retry, проверку полей и нормальные логи.