Извлечение данных из таблиц с LLM: где нужен парсер
Извлечение данных из таблиц с LLM не всегда дает чистый JSON. Разберем, когда хватает модели, а когда нужны парсер, правила и постпроверка.
Почему таблицы ломают простой промпт
LLM хорошо читает связный текст. Таблица в PDF почти никогда не попадает в модель как аккуратная сетка. Обычно это набор фрагментов: кусок шапки, числа из середины, подпись внизу страницы. Для человека это все еще таблица. Для модели это уже поток текста с нарушенным порядком.
Проблема начинается еще до ответа модели. PDF часто хранит не таблицу, а отдельные текстовые блоки с координатами на странице. Во время извлечения границы строк и колонок легко теряются. Цена из одной колонки "прилипает" к соседней, артикул уезжает вверх, а пустая ячейка исчезает совсем. Если структура распалась на входе, промпт "верни JSON по строкам" уже не спасает.
Объединенные ячейки добавляют еще больше шума. Если одна ячейка растянута на две строки, модель часто сдвигает значение вправо или вниз. Так появляются тихие ошибки: сумма НДС относится не к той позиции, скидка попадает в поле "цена", единица измерения пропадает. Хуже всего то, что такой JSON выглядит правдоподобно и долго не вызывает подозрений.
Двухуровневые шапки тоже мешают. Вверху может быть общий заголовок "Сумма", а ниже - "без НДС" и "с НДС". Человек мгновенно понимает структуру. Модель то понимает, то схлопывает все в одно поле, то придумывает свои имена. Если вы ждете строгую JSON schema для LLM, путаница быстро уходит дальше по пайплайну.
Есть и более приземленные сбои. Строки "Итого" и "Всего к оплате" модель иногда считает обычными позициями. Примечания под таблицей попадают в последний ряд. Пустые ячейки заполняются по догадке. Повтор шапки на второй странице выглядит как новая запись.
Поэтому таблицы ломают простой промпт не потому, что LLM "плохо думает". Документ сам путает порядок данных еще до того, как модель начинает что-либо разбирать.
Когда модели хватает без парсера
Отдельный парсер нужен не всегда. Если документ похож на аккуратный Excel, а не на сложный PDF со сносками и вложенными блоками, модель часто справляется сама.
Обычно это работает в простых случаях: в файле одна таблица, колонки стоят ровно, строки не расползаются из-за переносов, а заголовки почти не меняются от документа к документу. Тогда модель видит понятную структуру и не тратит попытки на угадывание границ ячеек.
Еще один хороший сценарий - когда вам нужны не все строки таблицы, а несколько полей верхнего уровня. Например, дата, номер документа, итоговая сумма и ИНН. Здесь модели не нужно идеально восстановить всю сетку. Ей нужно найти нужные значения и вернуть их в одном формате.
Такой подход особенно удобен там, где человек все равно смотрит результат перед загрузкой в систему. В этом режиме LLM снимает рутину, а оператор за 10-20 секунд замечает странные суммы, пустые поля или перепутанные даты. Если ручная проверка уже встроена в процесс, отдельный парсер часто дает мало выигрыша, но добавляет разработку и поддержку.
Есть и простой фильтр по цене ошибки. Если промах не ломает оплату, отчет, договор или учет, разумно начать с более легкой схемы. Например, команда собирает еженедельные таблицы от подрядчиков и все равно сверяет их перед импортом. В таком потоке лучше сначала посмотреть на качество модели на 100-200 реальных файлах, а потом решать, нужна ли более жесткая архитектура.
Без парсера обычно можно обойтись, если совпадают сразу несколько условий: документы похожи по верстке, таблица одна, сложных объединений почти нет, нужны только несколько полей, результат проверяет человек, а ошибка не создает юридический или финансовый риск. Если хотя бы большая часть этих условий выполняется, начните с модели и не усложняйте систему раньше времени.
Когда нужен отдельный парсер
Парсер нужен там, где таблица сначала теряет форму, а потом и смысл. LLM неплохо читает простую сетку из PDF или HTML, но как только документ начинает ломать структуру, одной модели уже мало.
Частый случай - несколько таблиц на одной странице, между которыми стоят подписи, печати, сноски или вложенные блоки. Модель может уловить общий контекст, но ей трудно стабильно определять, где заканчивается одна таблица и начинается другая. Она склеивает соседние блоки, переносит ячейки не в тот столбец или теряет пустые строки, которые на самом деле важны.
Проблема быстро растет на многоуровневых шапках. Визуально человек видит, что один столбец делится на два подстолбца. Модель иногда угадывает правильно, но стабильности здесь мало. Парсер в таком случае сначала собирает геометрию таблицы: границы, объединенные ячейки, порядок строк и колонок. Только после этого есть смысл подключать LLM для разбора смысла полей.
Со сканами ситуация еще жестче. Если OCR путает "0" и "О", "1" и "I", "8" и "B", ошибка очень быстро доходит до бизнес-процесса. В счете это может сломать сумму, дату, ИНН или номер документа. Модель в таких случаях часто пытается додумать текст. Парсер и проверки работают строже и фантазируют меньше.
Отдельный разбор почти обязателен, когда вам нужно сохранить не только значения, но и саму структуру: номер строки из исходного документа, единицу измерения, валюту, пустые ячейки, связь строки с примечанием или итогом. Пока данные не ушли в ERP, это кажется мелочью. После интеграции цена ошибки резко меняется.
Правило простое: если ошибка в одном поле сразу бьет по деньгам, учету или комплаенсу, сначала ставьте парсер, потом LLM. Парсер отвечает за форму, модель - за смысл.
Что проверять после извлечения
После извлечения проблема редко сводится к одному неверному полю. Обычно ломается цепочка: модель не так поняла шапку, перепутала единицы, а затем аккуратный JSON спрятал ошибку. Поэтому проверять нужно не только ответ, но и источник каждого значения.
Парсеру лучше оставить ту часть работы, где важна геометрия документа. Он должен находить границы таблицы, выделять строки и ячейки, сохранять страницу и координаты. Тогда при ошибке команда не гадает, что именно пошло не так. Можно сразу открыть нужную страницу и посмотреть конкретную ячейку.
LLM лучше отдать нормализацию. Она хорошо приводит "Сумма, руб.", "Итого к оплате" и Total к одному полю, переводит даты в единый формат и сводит "шт.", pcs и "ед." к общему виду. Но рядом с нормализованным значением стоит хранить исходный текст. Иначе спорный случай потом не разобрать.
Проверки должны срабатывать сразу в том же пайплайне, а не через час в отчетах. Если в счете нет даты, валюты, итоговой суммы или названия поставщика, документ лучше отправить на повторную обработку или на ручной разбор.
Минимальный набор правил обычно такой:
- обязательные поля не пустые;
- дата распознана в нужном формате;
- единицы измерения приведены к одному виду;
- валюта и НДС не потерялись;
- у каждого значения есть ссылка на страницу, строку или ячейку.
После этого нужно сверить арифметику. Сумма по строкам должна совпадать с итогом документа, а скидки, доставка и НДС должны объяснять разницу. Допуск на округление лучше задать явно, например 1-2 копейки.
Признак нормального пайплайна - у каждого поля есть "след": страница, номер строки, координаты ячейки и исходный фрагмент текста. Для банков, телекома и других команд с аудитом это не опция, а рабочее требование. Если команда прогоняет документы через RU LLM, такой след удобно сопоставлять с audit trail запроса и быстрее разбирать спорные ответы.
Как собрать пайплайн по шагам
Рабочий пайплайн для таблиц лучше строить не от модели, а от ошибок, которые вы не готовы пропустить. Если сразу отдать PDF в LLM и ждать готовый JSON, демо часто выглядит убедительно. Настоящие проблемы приходят на кривых сканах, пустых ячейках, слиянии колонок и строках "Итого".
Начните с тестового набора. В нем нужны не только чистые документы, но и неприятные случаи: перекошенные сканы, многостраничные файлы, таблицы с примечаниями, разные форматы дат и чисел. Уже 30-50 документов дают честную картину.
Схему полей лучше зафиксировать до выбора модели. Если поле "сумма" в одном документе включает НДС, а в другом нет, проблема не в модели. Проблема в том, что схема не определена. Для каждого поля заранее задайте тип, допустимый формат и правило, что считать пустым значением.
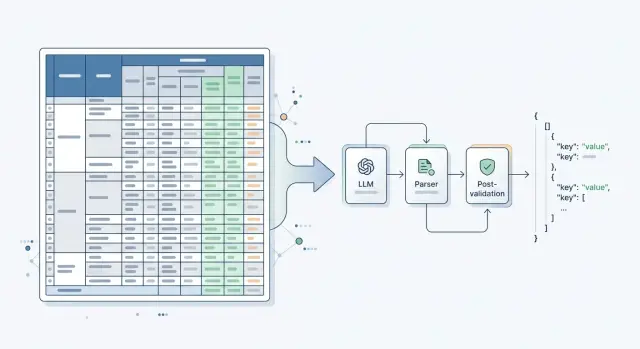
Дальше пайплайн удобно разделить на пять шагов:
- Найти таблицу или нужную область на странице.
- Превратить ее в промежуточную структуру: строки, колонки, ячейки.
- Передать эту структуру в LLM для разметки и нормализации.
- Прогнать результат через простые проверки.
- Сравнить ответ с эталоном по каждому полю.
Такое разделение экономит много времени. Если ошибка появилась на этапе поиска таблицы, не нужно менять промпт. Если модель перепутала валюту или формат даты, не нужно переписывать OCR.
Постпроверка должна быть скучной и строгой. Суммы должны сходиться с количеством и ценой, даты - попадать в допустимый формат, ИНН - проходить контрольную проверку, валюта - входить в короткий список разрешенных значений. Когда правило срабатывает, лучше не исправлять ответ молча, а помечать запись для повторной обработки.
Метрики тоже стоит считать по полям, а не только по целому JSON. Один неверный ИНН и лишняя запятая в комментарии стоят по-разному. Поэтому имеет смысл отдельно смотреть точность для сумм, дат, реквизитов и строк таблицы.
Если вы тестируете несколько моделей через единый OpenAI-совместимый шлюз, менять модель стоит только после того, как схема и проверки зафиксированы. Иначе вы сравниваете не модели, а хаос в постановке задачи.
Пример со счетами поставщиков
Хороший тест - входящие счета в PDF от десятков поставщиков. У каждого свой шаблон: где-то таблица аккуратная, где-то строки переносятся, а где-то документ похож на скан с печатью поверх цифр.
Бухгалтерии и закупкам обычно нужны одни и те же поля: поставщик, номер счета, дата, позиции, количество, цена, НДС, итог. Но даже в этом простом наборе нюансов хватает. В одном счете НДС идет отдельной строкой, в другом уже включен в сумму. Модель легко путает эти случаи.
С полями верхнего уровня LLM обычно справляется неплохо. Она видит подписи вроде "Поставщик", "Счет №", "Дата" и часто верно вытаскивает имя компании, номер счета и дату даже из неидеального PDF. Здесь контекст страницы помогает больше, чем точная геометрия.
С позициями счета все сложнее. Если в таблице 12 строк, названия товаров длинные, а количество и цена стоят в узких колонках, обычный ответ модели часто сдвигает значения. Две соседние строки сливаются в одну, цена уходит к другой позиции, единица измерения исчезает. Здесь парсинг таблиц обычно надежнее, потому что он держит структуру строк и колонок.
На практике рабочая схема выглядит так: модель достает поставщика, номер счета, дату и валюту; парсер собирает строки таблицы; отдельное правило определяет, вынесен ли НДС отдельно или уже включен; постпроверка сравнивает сумму строк с итогом документа.
Последний шаг спасает от дорогих ошибок. Представьте счет на 27 позиций: модель верно нашла поставщика и дату, но в одной строке прочитала 118 штук вместо 18. Визуально ответ выглядит правдоподобно. Ошибка всплывает только на сверке. Если постпроверка считает сумму по строкам и сравнивает ее с итогом, расхождение видно сразу.
Ошибки, которые дорого обходятся
Самая дорогая идея на старте - один промпт, который должен сразу прочитать PDF, вытащить поля из таблицы и сам же проверить результат. На демонстрации это иногда работает. В реальном потоке документов такой подход быстро ломается: модель путает строки, теряет объединенные ячейки и затем уверенно подтверждает собственную ошибку.
Еще одна типичная проблема - не зафиксировать схему заранее. Сегодня поле называется vat_rate, завтра nds, послезавтра туда кладут строку "без НДС". Один сервис ждет число, другой получает текст, третий тихо записывает null. Так ломается не только обработка, но и отчеты, сверка и поиск причин.
То же относится к типам данных. Если поле amount иногда хранит 12500.50, а иногда 12 500,50 руб., вы просто переносите хаос дальше по цепочке. Для денег, дат, процентов и количества формат лучше закрепить сразу.
Часто недооценивают и отсутствие следа к источнику. Если вы не храните исходный фрагмент таблицы, координаты ячейки или хотя бы текст строки, ручная проверка превращается в долгий поиск. В командах с аудитом это особенно больно: нельзя быстро показать, откуда взялось конкретное значение.
И еще одна ловушка: считать успехом любой JSON, который выглядит аккуратно. Красивый ответ не равен верному ответу. Сверяйте суммы по строкам с итогом, проверяйте валюту, единицы измерения, формат дат и обязательные поля. Если документ не проходит эти проверки, его нужно отправлять в отдельную очередь, а не дальше по пайплайну.
Проверка перед запуском
Перед запуском нужен короткий стресс-тест на реальных файлах. Если проверить только аккуратные PDF, качество покажется выше, чем есть на самом деле. В рабочем потоке почти всегда смешиваются чистые файлы, сканы и документы со сложной шапкой.
Тестовый набор не обязан быть большим, но он должен быть злым. Добавьте счета с кривым OCR, таблицы с объединенными ячейками, переносами строк внутри суммы и разными форматами дат. Если система проходит только ровные документы, это слабый сигнал.
Для каждого поля задайте простое правило еще до старта. Иначе команда спорит о качестве на уровне ощущений. С правилами разговор быстро становится предметным. Например:
- дата не может быть из будущего;
- ИНН должен иметь 10 или 12 цифр;
- сумма по строкам должна сходиться с итогом;
- валюта должна входить в допустимый список;
- номер счета не должен быть пустым, если есть сумма к оплате.
Отдельно посмотрите, где ошибки повторяются. Обычно набор проблем быстро становится понятным: путаются заголовки колонок, итог попадает в одну из строк, НДС читается как часть суммы, исчезают единицы измерения, на сканах ломаются десятичные разделители.
Первую партию документов лучше просмотреть руками. Не тысячи файлов, а хотя бы 50-100 на каждый важный тип таблиц. Такой просмотр быстро показывает, где нужен парсер, где хватает постпроверки, а где стоит поменять саму схему JSON.
Нормальный запуск начинается не со средней точности, а с карты риска. Тогда сразу понятно, какие документы можно пускать автоматически, а какие пока держать на ручной проверке.
Что делать дальше
Не ищите один универсальный способ. В таблицах почти всегда лучше сначала разложить документы по уровню сложности, а уже потом выбирать архитектуру.
Простые документы с одной таблицей и ровной версткой часто можно отдавать сразу модели с жесткой схемой ответа и короткой постпроверкой. Средние документы обычно лучше идут через связку: сначала парсинг таблицы, потом LLM для нормализации и заполнения спорных полей. Сложные документы со сканами, плохим OCR и нестабильными шаблонами почти всегда требуют отдельного парсера, OCR и строгой валидации.
Начинать лучше не с синтетических примеров, а с 50-100 реальных таблиц, которые уже ломали процесс. Этого хватает, чтобы увидеть, где модель путает строки, теряет единицы измерения или склеивает соседние ячейки.
В пилоте полезно смотреть не только на общую точность, но и на три практические метрики: долю документов без ручной правки, число критичных ошибок на 100 файлов и среднее время обработки одного документа.
Если вы сравниваете несколько моделей, не меняйте все сразу. Оставьте один и тот же OCR, один и тот же парсер, одну схему JSON, одни и те же проверки и один набор документов. Только так сравнение будет честным.
Для команд, которым нужен контур внутри РФ, такой пилот удобно прогонять через RU LLM. Можно заменить base_url на api.rullm.com, сохранить текущий SDK, код и промпты, а модели сравнивать через один OpenAI-совместимый эндпоинт. Это упрощает тесты, когда логи и обработку нужно держать внутри РФ.
Если нужен практичный старт, начните с одной формы документа, одной схемы ответа и одного списка проверок. Неделя такого пилота обычно дает больше, чем месяц споров о том, какой подход лучше "в целом".
Часто задаваемые вопросы
Почему простой промпт часто не справляется с таблицами в PDF?
Потому что PDF часто хранит не таблицу, а набор текстовых блоков с координатами. На этапе извлечения порядок легко ломается: числа прилипают к соседним колонкам, пустые ячейки пропадают, а строка Итого выглядит как обычная позиция.
Если структура распалась до ответа модели, даже хороший промпт вернет правдоподобный, но неверный JSON.
Когда можно обойтись одной моделью без отдельного парсера?
Да, если документы очень похожи друг на друга. Обычно это одна аккуратная таблица без сложных объединений, а вам нужны только верхние поля вроде даты, номера, ИНН и итоговой суммы.
Такой вариант особенно удобен, когда человек все равно быстро проверяет результат перед загрузкой.
В каких случаях без парсера лучше не идти в прод?
Парсер нужен, когда таблица теряет форму: на странице несколько блоков, есть многоуровневая шапка, объединенные ячейки, сноски или важны пустые значения. В таких случаях модель начинает сдвигать поля и смешивать соседние строки.
Если ошибка в одном поле бьет по оплате, учету или комплаенсу, сначала восстановите структуру парсером, а уже потом подключайте LLM.
Что делать со сканами и плохим OCR?
Осторожно. На сканах OCR часто путает символы, а модель пытается додумать пропуски. Из-за этого ломаются суммы, даты, ИНН и номера документов.
Если у вас сканы с печатями, перекосом или плохим качеством, ставьте OCR, парсер и строгие проверки. Одна LLM здесь дает слишком много тихих ошибок.
Что проверять после извлечения таблицы?
Сразу смотрите на обязательные поля, формат даты, валюту, НДС и арифметику. Сумма по строкам должна сходиться с итогом документа с заранее заданным допуском на округление.
Еще проверьте, что у каждого значения есть источник: страница, строка или ячейка. Тогда спорные случаи можно быстро разобрать руками.
Зачем хранить координаты ячеек и исходный текст?
Потому что без исходного фрагмента вы не поймете, откуда взялось спорное значение. Когда сумма не сходится или дата выглядит странно, команде нужно открыть конкретную страницу и увидеть ту самую ячейку.
Такой след сильно экономит время на разборе ошибок и нужен там, где есть аудит.
Сколько документов нужно для первого пилота?
Возьмите 30–50 реальных документов на один тип таблиц, а не только красивые примеры. Добавьте кривые сканы, переносы строк, объединенные ячейки и повтор шапки на второй странице.
Этого уже хватает, чтобы увидеть, где модель путает строки, а где схема и проверки работают нормально.
Как честно сравнить несколько моделей на таблицах?
Не меняйте все сразу. Оставьте один OCR, один парсер, одну схему JSON, один набор проверок и один тестовый набор документов.
Тогда разница в результате покажет качество модели, а не шум в пайплайне. Если гоняете тест через RU LLM, удобно держать один и тот же код и просто переключать модель через единый эндпоинт.
Какие ошибки в таблицах самые опасные?
Часто дорого обходятся тихие ошибки, которые выглядят аккуратно. Например, Итого попадает в строки таблицы, НДС читается как часть суммы, а количество 118 появляется вместо 18.
Именно поэтому красивый JSON нельзя считать признаком качества. Сверка сумм и строгие правила ловят такие сбои лучше любого визуального осмотра ответа.
Как собрать минимальный рабочий пайплайн без лишней сложности?
На старте берите одну форму документа, одну схему ответа и короткий набор правил. Сначала найдите таблицу, потом соберите строки и ячейки, затем дайте LLM нормализовать поля и в конце прогоните проверки.
Не пытайтесь сразу построить универсальный конвейер для всех документов. Узкий пилот за неделю обычно дает больше пользы, чем долгий спор о лучшей архитектуре.