Идемпотентность в LLM API: как не платить дважды
Идемпотентность в LLM API помогает пережить таймауты и повторы без двойных списаний, повторных писем, дублей в CRM и лишних действий.
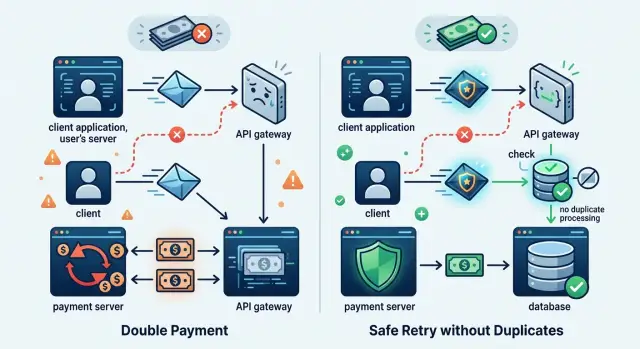
Почему один запрос срабатывает дважды
Один и тот же запрос часто дублируется не из-за "ошибки пользователя", а из-за обычного поведения сети, клиента и промежуточных слоев. Самый частый сценарий простой: клиент ждет ответ 30 секунд, не получает его и считает запрос неудачным. Но сервер за это время уже мог принять тело запроса, отправить его модели и начать считать токены.
Таймаут почти никогда не означает, что обработка остановилась. Он означает только одно: клиент перестал ждать. Если после этого приложение отправит тот же запрос еще раз, система может посчитать его новым вызовом. Тогда вы получите двойные расходы.
Часть повторов создает сама клиентская библиотека. Многие HTTP-клиенты, SDK и фоновые воркеры автоматически повторяют запрос после обрыва соединения, 502, 503 или краткого сетевого сбоя. Разработчик иногда даже не замечает этого, потому что retry уже включен по умолчанию.
Пользователи тоже создают дубли. Человек нажал кнопку, не увидел ответ сразу, обновил страницу или кликнул еще раз. Для чата это выглядит безобидно. Для генерации счета, записи в CRM или запуска фоновой задачи это уже повторное действие.
Есть и еще один источник риска - сеть между клиентом и моделью. Если запрос идет через API-шлюз, балансировщик и внешнего провайдера, повтор может появиться на любом участке. Один узел решил, что ответа не было, и отправил запрос снова, хотя предыдущая попытка уже дошла до модели.
Обычно дубли появляются по четырем причинам: клиент дождался таймаута, хотя сервер продолжал работу; SDK или HTTP-клиент сам сделал retry; пользователь повторно нажал кнопку; прокси, балансировщик или сеть повторили отправку после сбоя.
Идемпотентность нужна именно для таких случаев. Она не чинит сеть и не убирает таймауты. Она дает системе способ понять, что перед ней тот же запрос, который уже начали или уже завершили, и не брать деньги второй раз.
Как понять, что запрос тот же самый
Одинаковый промпт еще не значит, что запрос один и тот же. Для идемпотентности важен не текст, а намерение: пользователь хотел повторить уже начатую операцию или запустить новую.
Простой пример: менеджер нажал "отправить письмо клиенту", сеть зависла, и приложение послало запрос еще раз. Если цель та же, это повтор. Но если через минуту менеджер меняет получателя или тему письма и снова жмет кнопку, это уже новая операция, даже если половина промпта совпадает.
Смотреть стоит не только на prompt, model и temperature. Важна сама бизнес-операция. Если LLM участвует в создании счета, ответа клиенту, карточки инцидента или резюме звонка, "тем же самым" запросом считается попытка выполнить одно и то же действие над одним и тем же объектом.
Обычно у такой операции есть понятная опора: order_id для заказа, message_id для письма, ticket_id для заявки, task_id для задачи, document_id для документа. Именно эту опору и надо связывать с ключом идемпотентности. Не отдельно в логах и не только в заголовке запроса, а рядом с самой операцией в базе.
Тогда сервер видит: по заказу 58142 уже был запрос с таким ключом, значит нужно вернуть прошлый результат, а не выполнять действие снова.
Иногда одинаковыми стоит считать даже запросы с разным текстом. Такое бывает, когда клиентский код добавил служебную фразу, поменял порядок полей в JSON или пересобрал промпт после ретрая. Если операция одна и тот же idempotency key сохранился, сервер не должен создавать второе письмо, второй счет или вторую запись.
Полезное правило простое: если бизнес скажет "это одна попытка сделать одно действие", система должна считать это одним запросом. Если пользователь осознанно начал новое действие, нужен новый ключ.
На практике это часто ломается на мелочах. Разработчик хранит ключ отдельно от заказа, а потом не может понять, какой ответ к чему относится. Намного надежнее записывать связку сразу: тип операции, идентификатор объекта, ключ, статус и итоговый ответ модели. Тогда повтор легко отличить от нового намерения пользователя.
Где появляются двойные расходы
Двойные расходы возникают не только при явном повторе одного и того же запроса. Чаще проблема прячется в цепочке вызовов: клиент не дождался ответа, сеть оборвалась, оркестратор сделал retry, а модель уже начала работу. Для биллинга это два отдельных запуска.
Самый простой случай - повторная генерация токенов. Если приложение отправило тот же prompt еще раз, провайдер обычно считает его новым запросом и списывает деньги заново за входные и выходные токены. Даже если пользователь видит "тот же вопрос", для системы это новая работа.
Иногда расходы растут сильнее, чем кажется. Один лишний retry повторно прогоняет генерацию и дает второе списание за токены. Если система отправляет запрос сразу в несколько моделей для сравнения или fallback, случайный повтор умножает расходы на все вызовы сразу. А если внутри ответа модель вызывает платный внешний API, вы платите еще и за него.
Особенно неприятен fan-out сценарий. Команда настраивает маршрутизацию: одна модель отвечает быстрее, другая лучше решает сложные задачи, третья идет как запасной вариант. Если клиент или шлюз без контроля повторов отправляет запрос снова, счет растет вдвое или втрое за секунды.
С инструментами риск еще выше. Модель может не только сгенерировать текст, но и вызвать внешний сервис с оплатой за каждый запрос: поиск, SMS, проверку документа, скоринг. Тогда вы платите дважды: сначала за токены модели, потом за повторный вызов стороннего API. Если инструмент запускает действие с деньгами, вроде проверки карты или отправки кода, потери уже вполне реальные.
Потоковый режим тоже часто сбивает с толку. Пользователь видит, что ответ "не дошел", и интерфейс жмет повтор. Но модель могла уже сгенерировать 90% текста, а провайдер успел учесть это в биллинге. Новый запуск создает еще одно списание, хотя человеку кажется, что ничего не произошло.
Именно поэтому идемпотентность влияет не только на корректность действий, но и на счет. Если запросы идут через единый шлюз и могут маршрутизироваться к разным моделям или провайдерам, цена случайного повтора становится заметной даже на обычном трафике.
Где появляются двойные действия
Самый опасный повтор - не тот, что снова генерирует текст, а тот, что меняет что-то вне чата. Текст можно отбросить. Письмо, платеж или новая запись в системе уже оставляют след.
Проблема начинается в тот момент, когда модель или агент вызывает инструмент с побочным эффектом. Если клиент не получил ответ вовремя и отправил тот же запрос еще раз, система может честно выполнить одно и то же действие дважды.
Типичные примеры знакомы почти всем командам: агент два раза отправляет письмо клиенту, бот создает две одинаковые заявки в CRM, инструмент повторно проводит платеж или бронирование, фоновый обработчик снова публикует уже отправленное событие.
Проблема не всегда в самой модели. Часто сбой возникает между шагами. Сервер уже принял запрос, инструмент уже сработал, но ответ потерялся на таймауте. Клиент видит ошибку и делает retry. Для сервера это новый вызов, если он не помнит прошлую попытку.
Где риск выше всего
Самая частая зона риска - интеграции, где LLM не просто отвечает текстом, а управляет действием. Например, агент поддержки получил команду "отправь подтверждение" и вызвал email-инструмент. Через пару секунд сеть оборвалась. Оркестратор решил, что вызов не удался, и запустил тот же шаг заново. Клиент получает два письма и делает вполне очевидный вывод: процесс сломан.
Похожая история бывает с CRM. Бот собирает данные из диалога и создает заявку. Если запись прошла, а ответ API не дошел до вызывающей стороны, повтор запроса создает дубль. Менеджер потом видит две карточки с одним и тем же номером телефона.
С платежами и бронированиями цена ошибки еще выше. Повторный tool call может списать деньги второй раз или занять еще один слот. Даже если банк потом отклонит дубль, пользователю уже пришлось разбираться с проблемой.
Отдельный класс ошибок дает фоновая обработка событий. В очередях и брокерах часто действует модель at-least-once delivery. Это значит, что обработчик может получить одно событие больше одного раза. Если он после каждого получения публикует новое событие без проверки, дубль разойдется дальше по цепочке.
Если операция меняет состояние во внешней системе, считайте ее опасной по умолчанию. Для таких вызовов нужен один и тот же идентификатор операции на всех повторах. Иначе мелкий сетевой сбой быстро превращается в реальное двойное действие.
Как защититься на клиенте
На клиенте ошибка почти всегда одна и та же: приложение путает повтор доставки с новой командой. Из-за этого все ломается еще до сервера - в кнопке, мобильном экране или фоновой задаче.
Начните с простого правила: один замысел пользователя = один ключ идемпотентности. Если человек нажал "Сгенерировать ответ клиенту", клиент создает новый ключ и хранит его рядом с запросом. Пока вы не получили ясный итог, этот ключ менять нельзя.
Если сеть оборвалась, приложение словило таймаут или пользователь перезагрузил страницу, отправляйте повтор с тем же ключом. Новый ключ в этот момент превращает безопасный повтор в новую операцию. Именно так и появляются двойные списания и повторные действия.
У интерфейса тоже есть своя работа. После отправки лучше сразу блокировать повторный клик и показывать состояние ожидания: "запрос выполняется", "проверяем результат", "можно повторить". Это не просто вопрос удобства. Так вы не даете пользователю случайно создать второй запрос раньше, чем станет понятно, что случилось с первым.
Рабочий порядок обычно такой:
- Создайте ключ в момент явного действия пользователя.
- Сохраните его локально до отправки запроса.
- При таймауте или сетевой ошибке повторите запрос с тем же ключом.
- Не открывайте кнопку повторно, пока клиент не проверил статус первой попытки.
- Если пользователь изменил смысл команды, создайте новый ключ.
Важно отделять повтор от новой команды. Если пользователь отправил тот же промпт повторно только потому, что не увидел ответ, это один и тот же замысел. Если он поменял текст, модель, температуру, получателя письма или добавил новое действие вроде записи в CRM, это уже другая операция.
Еще один полезный шаг - писать в журнал клиента причину каждого повтора. Короткой записи достаточно: timeout, connection reset, tab reloaded, manual retry. Потом по этим меткам легко понять, где именно рождаются дубли и кто их запускает - код, сеть или сам пользователь.
Даже если вы работаете через совместимый шлюз, первое решение все равно принимает клиент. Именно он должен помнить, что пользователь хотел сделать один раз, а что попросил сделать заново.
Что должен помнить сервер
Серверу мало просто принять ключ идемпотентности. Он должен связать этот ключ с конкретным запросом и сохранить итог так, чтобы повтор не запускал новую работу. Иначе клиент видит таймаут, отправляет запрос еще раз, а сервер второй раз считает токены, вызывает инструменты или пишет данные во внешнюю систему.
Обычно ключ передают в заголовке вроде Idempotency-Key. Если у вас OpenAI-совместимый API-шлюз или свой внутренний прокси, можно принять его и в метаданных запроса. Но правило должно быть единым для всех маршрутов. Смешанный подход без явного приоритета быстро создает путаницу.
Серверу полезно хранить не только сам ключ, но и отпечаток запроса. Это короткое представление тела, по которому можно понять: повторили тот же запрос или под тем же ключом прислали уже другой. В отпечаток обычно входят модель, сообщения, параметры генерации, tool calls, user_id или tenant_id, если они влияют на результат.
Минимальный набор данных такой:
- ключ идемпотентности;
- отпечаток запроса;
- статус операции;
- готовый ответ или ссылка на него;
- код ошибки, если обработка завершилась неуспешно.
Если сервер уже завершил обработку, на повтор он должен вернуть тот же результат. Не "похожий", не заново пересчитанный, а тот же HTTP-статус, тот же body и те же поля, которые клиент получил бы при первом ответе. Это важно и для биллинга, и для аудита.
Если ключ тот же, а тело другое, серверу лучше сразу вернуть конфликт. Подход с молчаливой перезаписью опасен: клиент думает, что защищен от дублей, а по факту под одним ключом проходят разные операции. Обычно здесь достаточно ответа уровня 409 Conflict с понятным текстом ошибки.
Отдельный статус нужен для незавершенной операции. Пока запрос еще выполняется, сервер может хранить состояние in_progress и время жизни записи. Тогда повторный запрос не стартует вторую обработку. Сервер либо возвращает текущий статус, либо просит клиент повторить попытку позже. Для длинных LLM-вызовов это обычная ситуация.
Если запрос может уйти к разным провайдерам через один эндпоинт, этот слой особенно важен. Без привязки результата к ключу и отпечатку повтор после сетевого сбоя легко превращается в двойной расход и лишние записи в журналах.
Таймаут после готового ответа
Представьте простой сценарий из банка. Приложение оператора просит модель подготовить ответ клиенту: почему платеж не прошел и что делать дальше. Запрос уходит в LLM API с одним телом и с ключом идемпотентности.
Дальше происходит неприятная, но обычная вещь. Модель уже сгенерировала ответ, сервер уже получил его от провайдера и даже посчитал стоимость, но сеть рвется за долю секунды до того, как клиент получает HTTP-ответ. Для клиента это выглядит как таймаут. Он не знает, успел сервер завершить запрос или нет.
Если клиент в такой ситуации отправит повтор без того же ключа, система легко создаст двойные списания. Сервер воспримет это как новый вызов модели, снова отправит запрос провайдеру и еще раз начислит usage. Если в цепочке был инструмент, риск выше: можно не только заплатить дважды, но и дважды выполнить действие.
Рабочий сценарий выглядит так:
- Клиент отправляет запрос с ключом
abc-123. - Сервер получает ответ модели, сохраняет сам ответ, usage, статус и факт выполненных tool call.
- Сеть рвется, и клиент не видит результата.
- Клиент повторяет тот же запрос с тем же ключом
abc-123. - Сервер находит запись и возвращает уже сохраненный ответ без нового вызова модели и без нового списания.
Это особенно важно, если модель успела вызвать инструмент. Допустим, агент не только написал текст для клиента банка, но и вызвал функцию отправки письма с подтверждением. Если сервер не связал результат инструмента с тем же ключом, повтор запроса может отправить письмо еще раз. Пользователь получит два одинаковых письма, а команда потом будет разбирать жалобу и логи.
Поэтому сервер должен помнить не только финальный текст модели. Ему нужны как минимум три вещи: отпечаток запроса, итоговый ответ и журнал побочных действий. Если письмо уже ушло, при повторе сервер не запускает инструмент снова. Он возвращает тот же ответ и тот же результат вызова инструмента.
Частые ошибки в реализации
Чаще всего идемпотентность ломают не на уровне сети, а в логике продукта. Код отправляет один и тот же запрос повторно, а система не может понять: это новая операция или дубль старой. Итог предсказуемый - лишние токены, двойные списания и повторные действия в бизнес-процессе.
Самая частая ошибка - строить ключ идемпотентности из текста промпта. Это плохая опора. Один и тот же текст может относиться к разным действиям пользователя, а небольшая правка в пробеле, системном сообщении или температуре уже даст другой отпечаток, хотя бизнес-смысл не изменился. Ключ лучше привязывать к операции: например, к конкретной попытке создать саммари по звонку, а не к самому тексту диалога.
Обратная проблема тоже встречается часто: один и тот же ключ используют для разных действий. Пользователь нажал "сгенерировать", потом "перегенерировать", потом отправил отредактированный вариант, а клиент все еще шлет старый идентификатор. Сервер честно возвращает прежний ответ, и команда долго ищет "странный кэш", хотя ошибка намного проще: разные операции склеили в одну.
Отдельно ломаются потоковые ответы и вызовы инструментов. Если стрим оборвался после 80% текста, клиент нередко считает запрос неуспешным и отправляет его заново. Для обычной генерации это уже может дать двойной расход. Если модель успела вызвать инструмент, второй запрос может повторно создать заявку, комментарий или запись в CRM.
Еще одна тихая ошибка - хранить только готовый ответ, но не хранить статус выполнения. Тогда система не различает состояния "запрос еще идет", "провайдер уже принял его", "инструмент уже сработал" и "можно безопасно повторить". В окне между отправкой к провайдеру и записью результата контроль легко теряется.
Плохие правила ретраев только усугубляют ситуацию. Нельзя повторять запрос после любой ошибки подряд. Если сервер вернул 400 из-за неверного формата, повтор не поможет. Если был таймаут или обрыв соединения, исход операции может быть неизвестен, и повторять надо с тем же idempotency key, а не с новым.
Надежная схема обычно выглядит так:
- один ключ на одну бизнес-операцию;
- отдельные статусы выполнения, а не только финальный ответ;
- явные правила ретраев для таймаутов, 5xx и сетевых сбоев;
- отдельный контроль для tool calls и других действий с побочным эффектом.
Если этого нет, система почти всегда работает "нормально" до первого сбоя. Потом один таймаут превращается в две генерации, две записи и лишний счет от провайдера.
Проверка перед релизом
Перед запуском полезно пройти короткий тест на живых сценариях, а не только по коду. Такие ошибки всплывают не в диаграммах, а в мелочах: таймаут у клиента, повтор после 429, двойной клик в интерфейсе, retry в очереди.
Если после такого повтора у вас появляются два списания, две записи в базе или два вызова внешнего сервиса, защита не закрыта. Исправлять это после релиза обычно намного больнее, чем потратить час на проверку заранее.
Проверьте хотя бы несколько вещей.
- У каждого запроса, который тратит деньги, пишет данные или запускает действие, есть свой ключ идемпотентности. Он приходит с клиента, не генерируется заново при каждом ретрае и живет достаточно долго, чтобы пережить сетевой сбой.
- Сервер при повторе отдает тот же результат или хотя бы тот же идентификатор результата. Если первая попытка уже создала completion, задачу или запись, вторая не должна создавать новую сущность.
- В журналах видно, кто отправил повтор, когда это случилось и по какой причине. Полезно различать ручной повтор, автоматический retry SDK, повтор после 429 и повтор после обрыва соединения.
- Команда проверила хотя бы четыре плохих сценария: обрыв сети после отправки запроса, таймаут после готового ответа, код 429 с автоматическим retry и двойной клик пользователя по одной кнопке.
- У команды есть простое правило, когда делать новый запрос, а когда повторять старый. Если меняется смысл операции, нужен новый ключ. Если меняется только попытка доставки того же действия, ключ должен остаться прежним.
Один практичный тест часто быстро вскрывает проблему. Отправьте запрос на генерацию, дождитесь момента, когда сервер почти наверняка успел обработать его, и оборвите соединение на клиенте. Потом повторите тот же запрос с тем же ключом. Хороший результат выглядит скучно: сервер не считает токены второй раз, не создает новый объект и возвращает уже известный ответ или его идентификатор.
Что сделать дальше
Начните не с общей схемы, а со списка операций, где дубль бьет по деньгам или по данным. Обычно это вызовы модели с тарификацией по токенам, запуск tool calls, отправка писем и SMS, создание задач, заказов и записей в CRM. Если один и тот же retry в этих местах дает двойные списания или повторные действия, правила идемпотентности пора фиксировать в коде, тестах и логах, а не держать в голове.
Дальше команде нужен единый договор: как выглядит ключ идемпотентности и сколько он живет. Формат должен быть простым, чтобы его не путали в разных сервисах. Часто хватает сочетания идентификатора операции, клиента и версии запроса. TTL выбирайте по реальному окну повторов. Для коротких вызовов это могут быть минуты, для платежей, биллинга или долгих фоновых задач срок обычно дольше.
После этого пройдитесь по трем слоям. Клиент должен уметь безопасно повторять запрос после таймаута. Шлюз не должен создавать второй проход, если получил тот же ключ. Обработчик не должен второй раз писать в базу или дергать внешний сервис, если первый вызов уже успел пройти.
Спорные случаи лучше разбирать не по ощущениям, а по журналам. Сохраняйте request id, ключ идемпотентности, время, статус ответа, провайдера и факт списания. Тогда видно, был ли это один запрос с потерянным ответом или два разных запроса.
Если команда работает через RU LLM, полезно проверить повторы на всем пути запроса, а не только в своем приложении. У сервиса один OpenAI-совместимый эндпоинт, а audit trail привязывается к каждому запросу, поэтому такие инциденты проще разбирать по всей цепочке. Подробности о самом шлюзе и его модели работы можно посмотреть на rullm.com.
Хороший следующий шаг на этой неделе простой: выберите один платный метод и один метод, который меняет данные, и доведите защиту от дублей до тестов и логов.
Часто задаваемые вопросы
Что такое идемпотентность в LLM API простыми словами?
Это способ не выполнить одну и ту же операцию дважды, если сеть, SDK или пользователь повторили запрос. Сервер узнает повтор по Idempotency-Key и возвращает прежний итог вместо нового запуска модели или инструмента.
Когда один запрос превращается в двойные расходы?
Чаще всего это случается после таймаута или обрыва соединения. Клиент перестает ждать, шлет тот же запрос еще раз, а первый вызов уже ушел в модель и начал тратить токены.
Таймаут значит, что запрос точно не выполнился?
Нет. Таймаут говорит только о том, что клиент не дождался ответа. Сервер в этот момент мог уже получить запрос, отправить его провайдеру и даже сохранить готовый результат.
Одинаковый промпт — это всегда тот же запрос?
Не всегда. Если человек осознанно запускает новое действие, нужен новый запрос, даже когда текст почти тот же. Смотрите не только на prompt, а на саму операцию: письмо, счет, заявку, саммари по звонку.
Как клиенту правильно работать с повтором?
Создавайте один Idempotency-Key в момент действия пользователя и храните его, пока не получите ясный итог. Если сеть упала или страница перезагрузилась, повторяйте запрос с тем же ключом, а не с новым.
Что сервер должен запоминать для защиты от дублей?
Серверу мало принять заголовок. Он должен сохранить сам ключ, отпечаток запроса, статус вроде in_progress или done, итоговый ответ и факт побочных действий, если они были.
Что делать, если пришел тот же ключ, но другое тело запроса?
Лучше сразу вернуть конфликт, например 409 Conflict. Если под одним ключом приходят разные тела, защита ломается: клиент думает, что повторяет старую попытку, а сервер уже видит новую операцию.
Стриминг и tool calls правда повышают риск дублей?
Да, и это самый неприятный случай. Стрим может оборваться после большей части ответа, а tool call мог уже отправить письмо, создать заявку или дернуть платный API, поэтому повтор без той же связки легко дает и второй расход, и второе действие.
Какие ошибки можно ретраить, а какие нет?
Повторяйте после таймаута, обрыва соединения и части 5xx, если используете тот же Idempotency-Key. Не повторяйте слепо после 400 и других ошибок формата: там вы просто снова отправите неверный запрос.
Как быстро проверить защиту от дублей перед релизом?
Проверьте плохие сценарии руками: таймаут после готового ответа, двойной клик, обрыв сети после отправки и автоматический retry в SDK. Хороший результат скучный: сервер не считает токены второй раз, не создает новый объект и отдает тот же итог.