Распределение GPU между онлайном и экспериментами без срыва SLA
Распределение GPU между онлайном и экспериментами требует квот, очередей и правил эскалации, чтобы исследование не ломало SLA продакшена.
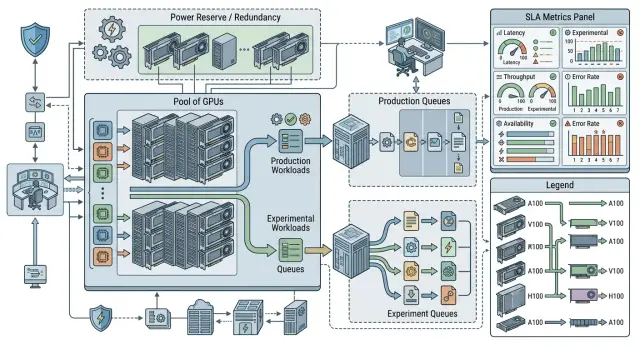
Где начинается конфликт за GPU
Конфликт начинается не в момент аварии. Он появляется раньше, когда онлайн и исследования сидят в одном пуле GPU и по средним метрикам выглядят совместимыми.
Днем клиентский трафик ждет быстрый и ровный ответ. В это же время исследователи запускают длинные прогоны, batch-оценку и fine-tuning. Им нужен тот же ресурс, но режим работы у этих задач совсем разный.
На графике картина часто обманчива. Средняя загрузка держится на уровне 55-65%, и кажется, что запас есть. Но SLA ломают не средние значения, а пики: час после рассылки, утренний вход пользователей, волна ретраев со стороны интегратора, рост длины промптов. Если в этот момент в общий пул заходит тяжелый эксперимент, очередь начинает расти за минуты.
Клиент видит не "проблемы кластера", а простые симптомы: ответ приходит на 3-5 секунд позже обычного, потоковая выдача стартует с паузой, часть запросов уходит в таймаут, а качество скачет, если система в спешке переводит трафик на более слабую модель.
Один тяжелый запуск ломает график потому, что GPU плохо делится на мелкие равные куски, когда задачи сильно различаются по длине и памяти. Короткие онлайн-запросы встают в очередь за одной большой задачей, хотя сами заняли бы совсем немного времени. Дальше проблема только нарастает: сдвигаются фоновые jobs, удлиняется хвост очереди, а алерты приходят уже после того, как просадку заметили пользователи.
Особенно жестко это видно там, где команда держит open-weight модели на своей инфраструктуре в РФ. Такой пул не всегда можно быстро расширить внешней мощностью, поэтому распределение GPU между онлайном и экспериментами нужно считать по пиковым окнам, а не по спокойному дню.
Типичный сценарий выглядит так: в 11:30 сервис загружен наполовину, и исследователь запускает оценку новой модели на большом датасете. В 11:45 приходит всплеск клиентских запросов. До запуска все выглядело безопасно. После запуска запас исчез, и SLA уже поехал вниз.
Какие нагрузки нельзя держать в одной очереди
Самая частая ошибка - складывать в одну очередь все, что просит GPU. Тогда короткий запрос пользователя ждет рядом с тяжелым batch-прогоном, и SLA падает даже при нормальной средней загрузке.
Синхронный inference для онлайн-сервиса нужно отделять сразу. У него есть жесткий срок ответа: обычно счет идет на секунды, иногда на сотни миллисекунд. Такие запросы нельзя смешивать с задачами, которые спокойно подождут 10 минут или ночного окна.
Отдельная очередь нужна для batch-работ. Сюда попадают массовая генерация, переиндексация, офлайн-обработка диалогов, пересчет эмбеддингов. Эти задачи нагружают GPU долго и ровно, поэтому быстро забивают общий пул так, что онлайн начинает дергаться волнами.
Fine-tuning и evaluation тоже не стоит прятать в общий поток. Fine-tuning держит память и может занимать карту часами. Evaluation часто выглядит безобидно, но на практике это сотни или тысячи прогонов подряд. Если пустить их в ту же очередь, где живет прод, один неудачный запуск быстро съест весь запас.
Рабочая схема обычно простая. Онлайну дают отдельный класс с жестким приоритетом, коротким таймаутом и резервом GPU. Batch-задачи получают низкий или средний приоритет и должны уметь ставиться на паузу. Evaluation живет в своей очереди с лимитом на параллелизм. Fine-tuning лучше относить в отдельный класс и запускать по расписанию или по согласованию.
Для каждого класса нужен свой критерий успеха. Онлайну важны p95 и p99 по задержке. Batch-задачам важен дедлайн, например завершение до 6 утра. Evaluation можно оценивать по правилу "закончить в течение дня". Fine-tuning обычно планируют по окнам, а не по очереди в реальном времени.
Еще одно полезное правило: у каждого типа нагрузки должен быть владелец. За online отвечает команда сервиса или платформы, за batch - команда данных или продукта, за fine-tuning и evaluation - ML-команда, которая запускает эксперимент. Когда владелец понятен, проще остановить задачу, перенести окно или урезать лимит.
Даже если снаружи у вас один OpenAI-совместимый endpoint, внутри не должна жить одна общая очередь. На уровне шлюза или оркестратора сначала определяют класс запроса, потом отправляют его в свой пул, со своим лимитом и своей политикой вытеснения. Это простое правило чаще всего и спасает SLA.
Как задать приоритеты без споров
Приоритеты считают не по тому, кто громче просит GPU, а по тому, какой сбой бизнес готов пережить. Если клиентский сервис обещает фиксированный SLA, этот трафик всегда получает ресурс первым, даже когда исследование кажется срочным.
Удобно заранее ввести четыре уровня. Тогда не придется обсуждать одно и то же каждый день.
- P0 - продовый онлайн с жестким SLA. Эти запросы нельзя вытеснять.
- P1 - резерв на отказ узла и всплеск трафика. Он может простаивать, но забирать его под эксперименты нельзя.
- P2 - фоновые задачи с дедлайном, например переиндексация или ночной batch.
- P3 - исследования, fine-tuning, офлайн-оценка, прогоны новых моделей. Их можно останавливать и переносить.
Ошибка здесь почти всегда одна и та же: команда считает резерв "лишними" GPU и отдает его экспериментам до первого инцидента. Резерв нужно считать под реальную аварию, а не под среднюю загрузку. Если один GPU-узел может выпасть целиком, запас должен пережить именно этот сценарий. Если вечером трафик стабильно растет на 25%, запас должен покрывать и этот пик.
Исследования стоит запускать только на свободной части пула. Не на всей доступной мощности и не по принципу "если что, потом остановим". Лучше заранее задать жесткое правило. Например, P3 получает ресурсы только если занято меньше 70% производственного пула и резерв свободен.
Низкий приоритет нужно вытеснять автоматически. Иначе дежурный инженер будет в чате решать, чей job важнее, а это уже потерянные минуты. Обычно хватает простых триггеров: рост p95, переполнение очереди, потеря узла, превышение порога загрузки в течение нескольких минут. Сработал триггер - P3 снимается без согласований.
Если часть моделей у вас работает на своих GPU, а часть можно быстро перевести через совместимый API-шлюз, локальный пул лучше защищать еще жестче. Тогда прод получает преимущество, а эксперименты первыми уходят на паузу или в более дешевую очередь.
Хорошее правило приоритета помещается на одну страницу и работает без ручных споров. Если для запуска исследования нужно писать в три чата и ждать одобрение, приоритеты еще не настроены.
Как делить пул GPU
Одинаковое число GPU не значит одинаковую мощность. Для онлайна важны не только карты, но и память под конкретную модель, размер batch, KV cache и запас под пики. Две задачи на 80 GB и 24 GB выглядят одинаково в отчете по числу GPU, но для планирования это совсем разные нагрузки.
Пул лучше делить не пополам, а по роли. Онлайну нужна закрепленная минимальная доля, которую нельзя забирать под эксперименты даже в спокойные часы. Иначе одна длинная прогонка быстро съест запас, а клиентский сервис упрется в рост задержки и ошибок.
На практике полезно держать четыре части пула: фиксированный резерв под онлайн, отдельный лимит для экспериментов, буфер под загрузку моделей и перезапуски, а также небольшой общий запас на короткие всплески. Этого уже достаточно, чтобы кластер вел себя предсказуемо.
Буфер часто недооценивают. Если модель весит десятки гигабайт, проблема начинается не в момент inference, а раньше, когда сервису нужно поднять новый инстанс или переложить трафик после сбоя. Без свободной памяти карта вроде бы есть, но запустить на ней ничего нельзя.
Емкость лучше считать по профилям нагрузки. Интерактивный inference с жестким SLA, пакетные jobs, fine-tuning и оценочные прогоны нужно считать отдельно. У них разный расход памяти, разная длина задачи и разная цена остановки.
Если профили сильно отличаются, разведите их по разным узлам. Онлайн с низкой задержкой не стоит держать рядом с длинными экспериментами, которые занимают память на часы. Это особенно заметно, когда часть моделей команда хостит сама, а часть ведет через единый API-шлюз: снаружи поток запросов один, а требования к железу внутри разные.
Полезное правило звучит так: онлайн получает гарантированный минимум, эксперименты живут в жестком потолке, а свободный остаток отдают только тем задачам, которые можно быстро снять без заметных потерь.
Что делать при перегрузе
Перегруз нужно ловить раньше, чем клиенты увидят ошибку. Для этого команде хватает трех порогов: p95 по задержке, длины очереди на inference и занятости памяти GPU. Если p95 несколько минут держится выше целевого SLA, очередь растет, а память подходит к пределу, система должна перейти в режим защиты.
Первое правило жесткое: online-трафик всегда важнее исследований. Эксперименты можно перенести. Пользовательский запрос, который уже пришел в сервис, перенести нельзя.
Дальше порядок действий лучше не усложнять.
- Сразу остановите batch-задачи, evaluation и все фоновые прогоны, которые не влияют на ответы клиентам прямо сейчас.
- Проверьте, что у online-сервисов есть свой гарантированный пул GPU. Если такого резерва нет, перегруз повторится.
- Переведите часть трафика на более легкую модель. Не весь поток, а только тот сегмент, где падение качества терпимо: черновики, классификация, короткие ответы, внутренние помощники.
- Урежьте то, без чего сервис проживет ближайший час: слишком длинные ответы, завышенный max tokens, повторные прогоны, необязательный rerank или second-pass обработку.
- Если метрики не вернулись в норму за заданное время, дежурный включает следующий уровень ограничений по заранее утвержденному сценарию.
Полезно зафиксировать и числа. Например, при памяти GPU выше 90% и очереди больше N запросов batch ставят на паузу. При p95 выше SLA на 30-40% часть трафика переводят на более легкую модель. Если и этого мало, снижают длину ответа, пока сервис не вернется в рабочий коридор.
Без назначенного ответственного схема не работает. Команда должна заранее решить, кто принимает такие меры и за сколько минут. Обычно это дежурный по платформе или ML-infra, а окно на решение составляет 5-10 минут с момента срабатывания порога.
На практике этого достаточно. При обычном перегрузе сначала убирают фон, потом разгружают модель, и только потом режут функциональность. Такой порядок бьет по исследованию меньше, чем по SLA.
Пример из обычной недели
В понедельник утром продуктовая команда выкатывает новую функцию с LLM, и трафик быстро растет. Еще в 9:30 кластер живет спокойно, а к 11:00 p95 уже ползет вверх. Аварии пока нет, но запас по задержке тает.
В этот же день исследователи запускают серию eval на том же пуле GPU. По отдельности такие прогоны безобидны. Проблема начинается, когда eval ест те же карты, что и онлайн-инференс, а планировщик смотрит только на факт свободной памяти, а не на SLA сервиса.
Если приоритеты настроены нормально, система реагирует до инцидента. Как только p95 выходит за внутренний порог, например за 80% от SLA, новые eval-задачи перестают стартовать и уходят в очередь. Те, что уже работают, не получают дополнительные GPU. Онлайн возвращает себе нужную емкость.
Обычный день при такой схеме выглядит просто. Утром онлайн ловит всплеск после релиза. Днем команда исследований ставит batch-eval на десятки прогонов. Мониторинг видит рост p95 и включает защиту SLA. Eval ждет своей очереди, а онлайн получает приоритет по GPU. Вечером трафик падает, и эксперименты снова запускаются.
Хорошая политика не пытается угадать все сценарии заранее. Она держится на нескольких сигналах: p95, длине очереди, занятости GPU и минимальном резерве под онлайн. Если два сигнала выходят за порог, исследовательская нагрузка автоматически замедляется. Ручные решения в такие моменты обычно опаздывают.
После перегруза стоит разбирать цифры, а не просто "возвращать эксперименты". Сколько минут eval простоял в очереди, сколько GPU онлайн забрал назад, как быстро p95 вернулся в норму. По этим данным видно, хватает ли текущего резерва или его нужно поднять, например с 20 до 30% в дни релизов.
Такой режим не очень удобен для исследования. Зато поведение кластера становится предсказуемым. Для клиентского сервиса это почти всегда правильный обмен.
Ошибки, из-за которых чаще всего срывается SLA
SLA срывается не только из-за нехватки GPU. Чаще причина проще: команда плохо разделила типы нагрузки. Когда все задачи считают равными, онлайн почти всегда проигрывает.
Первая ошибка - одна общая очередь для всего. В такой схеме запрос клиента, который должен отработать за секунды, встает рядом с fine-tuning, batch evaluation или прогоном на несколько часов. Формально очередь честная. По факту она наказывает прод.
Вторая ошибка - планирование по средней загрузке. На графике можно увидеть спокойные 55-60% и решить, что запас есть. Но SLA умирает не на среднем значении, а в пике: утром в будни, после релиза, во время рассылки, в конце отчетного периода. Если команда считает мощность по среднему числу, а не по пиковым окнам, она почти гарантированно покупает себе инцидент.
Третья ошибка - у продакшена нет права на вытеснение. Эксперимент уже занял карты, scheduler считает это нормой, а онлайн ждет освобождения. В этот момент исследование получает больший приоритет, чем платящий пользователь. Прод должен забирать ресурс первым, даже если исследовательский запуск придется прервать.
Четвертая ошибка - общий резерв для обучения и inference. На бумаге это выглядит экономно: весь пул общий, значит простоя меньше. На практике обучение съедает память и держит GPU долго, а inference страдает от любой вспышки трафика. Для онлайна нужен свой минимальный резерв, который нельзя отдавать под эксперименты.
Пятая ошибка - игнорирование времени на загрузку весов. В расчет берут только токены в секунду и пропускную способность, но не учитывают cold start. Если модель весит десятки гигабайт, загрузка в память GPU может занять минуты. Для клиента это не техническая мелочь, а лишняя задержка и прямой удар по SLA.
Типичный сбой выглядит так: утром команда запускает обучение на свободных восьми GPU, днем приходит пик онлайна, сервис пытается поднять еще один инстанс модели, а веса грузятся слишком долго. Карты заняты, вытеснения нет, очередь растет. Через десять минут все уже обсуждают деградацию сервиса, хотя проблема началась с плохих правил.
Ежедневный утренний чек
Каждое утро дежурный по платформе или владелец сервиса должен тратить 10 минут на один и тот же просмотр. Смотрите не на среднюю загрузку GPU, а на запас прочности. Если онлайн не переживает потерю одной карты или целого узла, эксперименты в этот день уже слишком агрессивны.
Проверка короткая:
- выдержит ли онлайн потерю одного GPU или одного узла без выхода за лимит по задержке;
- сколько карт сейчас заняты задачами без жесткого срока: оценкой, пакетной обработкой, дообучением, прогоном новых промптов;
- кто сегодня имеет право поднять приоритет вручную;
- какие jobs ждут в очереди дольше согласованного окна;
- вышли ли p95 и p99 за лимит по ответу или по времени генерации.
Полезно держать простые пороги. Если после отказа одного узла у вас остается меньше 15-20% запаса по онлайновой нагрузке, новые эксперименты в этот день лучше не запускать. Если p99 ползет вверх два интервала подряд, несрочные задачи стоит ставить на паузу автоматически.
Отдельно смотрите на очередь задач без срока. Она любит расти тихо. В понедельник там три jobs, в среду уже двенадцать, а в четверг одна из них случайно получает высокий приоритет и забирает карты, которые были нужны клиентскому трафику.
Если вы работаете через единый слой маршрутизации запросов, этот чек проще собрать в одной панели. Например, в RU LLM удобно видеть рядом задержки, логи запросов и следы по приоритетам. Для команд, которым нужен единый OpenAI-совместимый шлюз в российском контуре, такой слой упрощает контроль за лимитами и маршрутизацией без переделки клиентского кода.
Что записать в правила команды
Правила нужны, чтобы спор о ресурсах не решали в чате под нагрузкой. Когда распределение GPU между онлайном и экспериментами описано заранее, команда не тратит полдня на согласования и не срывает SLA из-за чужого прогона.
Первое правило простое: резерв онлайна нельзя трогать по желанию. Его может забрать только дежурный инженер или владелец прод-сервиса, если есть явный риск по SLA. Лучше сразу зафиксировать порог: рост очереди выше лимита на 10 минут, скачок p95 latency или отказ части GPU-узлов. Тогда решение выглядит как действие по регламенту, а не как личная просьба.
Тяжелые прогоны тоже лучше привязать ко времени. Днем, когда идут клиентские запросы, разумно разрешать только короткие тесты и отладку на малом лимите. Долгие eval, fine-tuning и массовые batch-задачи лучше запускать ночью, рано утром или в отдельные окна по календарю. Если команде нужно исключение, она заранее бронирует слот и показывает, сколько GPU и на сколько часов ей понадобится.
Отдельно стоит прописать, когда команда может снижать качество ответа ради SLA. Мера неприятная, но она лучше полного отказа сервиса. Обычно сначала уменьшают max tokens, отключают самые тяжелые цепочки, переводят часть трафика на более быструю или дешевую модель и режут параллелизм для фоновых задач. Эти шаги нужно утвердить заранее.
В рабочем документе обычно хватает пяти пунктов:
- кто может забирать резерв онлайна и по каким метрикам;
- в какие часы разрешены долгие прогоны и кто утверждает исключения;
- какие меры деградации включают при угрозе SLA и в каком порядке;
- что команда пишет в журнал вытеснений и инцидентов;
- как новая команда получает стартовую квоту и когда ее пересматривают.
Журнал вытеснений лучше вести коротко, но строго. Записывайте время, сервис, задачу, которую остановили, инициатора, причину, длительность влияния и итог. Через месяц такой журнал хорошо показывает повторяющиеся проблемы: у кого постоянно нет своей квоты, какие эксперименты заходят в прайм-тайм, где прогноз мощности расходится с реальностью.
Новым командам не стоит давать постоянный лимит с первого дня. Лучше выдать небольшую квоту на испытательный период, например на две недели, с понятным потолком по GPU-часам и обязательным владельцем со стороны платформенной команды. Если нагрузка предсказуема и команда не ломает общие правила, квоту можно увеличить. Если нет, она остается в песочнице и не давит прод.
С чего начать в ближайшие две недели
На практике распределение GPU между онлайном и экспериментами ломается не из-за нехватки железа, а из-за отсутствия простых правил. Поэтому не стройте сложную схему с десятком классов. Для начала хватит двух: онлайн-нагрузка и эксперименты. Сразу оставьте резерв, который никто не занимает по умолчанию.
Даже небольшой запас меняет поведение системы. Когда растет входной трафик, онлайн получает место без ручного вмешательства. Когда исследователи запускают длинный прогон, они сразу видят границу и не съедают весь пул незаметно.
Минимальный план такой:
- закрепить минимальную долю GPU за онлайном;
- выделить резерв под всплески, деградацию модели и аварийные переключения;
- раз в неделю устраивать контролируемый перегруз и смотреть, где очередь ломается первой;
- держать метрики, лимиты и журнал ручных решений в одном месте.
Искусственный перегруз лучше делать по расписанию, а не ждать живой аварии. Достаточно на 20-30 минут поднять тестовую нагрузку выше обычного пика, добавить пару тяжелых экспериментальных задач и проверить три вещи: растет ли p95, кто получает preemption и сколько времени команда тратит на ручные правки.
Если лимиты живут отдельно от метрик, а причины исключений остаются в чатах, команда спорит вместо того, чтобы чинить ситуацию. Когда очередь, утилизация GPU, задержка по онлайну, число вытеснений и история ручных override собраны в одной панели, видно не только сам перегруз, но и его причину.
Для команд в РФ удобно, когда внешние и локальные модели проходят через один набор правил. В RU LLM можно держать единый OpenAI-совместимый endpoint и для внешних провайдеров, и для open-weight моделей, размещенных в российских ЦОДах. Это упрощает лимиты, аудит и переключение маршрутов, если часть нагрузки нужно быстро увести на локальный пул или, наоборот, вынести наружу.
Если через две недели у вас есть два класса нагрузки, резерв, еженедельный стресс-тест и единый журнал решений, риск сорвать SLA уже заметно ниже. Этого достаточно, чтобы перестать тушить пожары и начать нормально планировать мощность.
Часто задаваемые вопросы
Почему средняя загрузка GPU 60% не значит, что со SLA все в порядке?
Нет. SLA ломают пики, а не среднее за день. Если в общий пул в этот момент попадает длинный eval или fine-tuning, короткие запросы клиентов ждут в очереди и задержка быстро растет.
Какие задачи нельзя держать в одной очереди с продовым inference?
Не смешивайте синхронный online inference с batch-задачами, evaluation и fine-tuning. У онлайна счет идет на секунды, а длинные jobs могут держать карту часами и забивать очередь даже при нормальной средней загрузке.
Сколько очередей нужно на старте?
Для старта хватит двух классов: онлайн и эксперименты. Если нагрузка уже заметная, быстро добавьте отдельную очередь для batch и отдельный лимит для evaluation, чтобы один массовый прогон не давил прод.
Как задать приоритеты без ежедневных споров?
Заранее закрепите простой порядок: P0 для продового онлайна, P1 для резерва, P2 для фоновых задач с дедлайном, P3 для исследований. Тогда дежурный не спорит в чате, а действует по правилу и сразу снимает низкий приоритет при росте задержки.
Сколько GPU стоит оставлять в резерве?
Держите резерв под отказ узла и под обычный пик трафика, а не под спокойный день. На практике смотрят, переживет ли онлайн потерю одной карты или узла и останется ли после этого запас хотя бы около 15–20%.
Когда нужно автоматически тормозить эксперименты?
Останавливайте их по сигналам, а не по ощущениям. Если p95 несколько минут выше внутреннего порога, очередь растет, а память GPU подходит к пределу, новые эксперименты не стартуют, а текущие P3-задачи уходят на паузу.
Что делать первым при перегрузе кластера?
Сначала снимите batch, evaluation и прочий фон. Если этого мало, переведите часть трафика на более легкую модель и урежьте длинные ответы или лишние проходы, чтобы сервис вернулся в нормальный коридор без полного отказа.
Можно ли запускать fine-tuning днем на том же пуле GPU?
Обычно нет, если днем у вас живой клиентский трафик и жесткий SLA. Такие прогоны лучше ставить в ночные окна, раннее утро или в отдельный пул, потому что они долго держат память и мешают быстро поднять online-инстанс.
Как понять, что пул GPU поделен плохо?
Смотрите на три вещи: p95 ползет вверх, очередь по inference растет, а свободная память на GPU исчезает даже без аварии. Еще один явный признак — сервис долго поднимает новый инстанс модели, потому что карты заняты чужими jobs.
С чего начать, если правил пока нет?
Начните с простого: отделите онлайн от экспериментов, закрепите минимум GPU за продом, введите резерв и настройте автоостановку P3 по p95 и длине очереди. За эти две недели еще полезно провести один контролируемый перегруз и проверить, как быстро система освобождает ресурс под онлайн.