Галлюцинации RAG: почему поиск не спасает от выдумок
Галлюцинации RAG возникают даже после хорошего поиска: разберём, где ломается цепочка поиск -> контекст -> ответ и как урезать ошибки на практике.
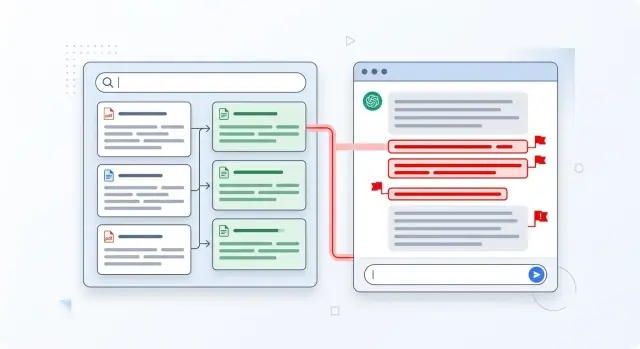
Где RAG начинает придумывать
RAG не "знает" ответ сам по себе. Поиск приносит фрагменты текста, а итоговую формулировку все равно пишет модель. В этот момент и появляется ошибка: модель не копирует найденное как архивариус, а собирает связный ответ своими словами.
Связный ответ и точный ответ - не одно и то же. Если поиск нашел три полезных фрагмента, модель пытается склеить их в одну историю. Там, где между ними есть пробелы, она часто вставляет догадку. Для читателя это выглядит уверенно и гладко, хотя в исходных документах такой связки могло не быть.
Обычно сбой начинается в одном из четырех мест:
- модель смешивает куски из разных документов, как будто они относятся к одному случаю
- переносит ограничение из одного текста на другой
- достраивает недостающий факт по шаблону, а не по источнику
- выбирает самый правдоподобный вариант, если контекст спорный или неполный
Представим внутреннюю базу знаний. В одном документе сказано, что возврат возможен в течение 14 дней. В другом описан отдельный случай для подписки на 30 дней. Поиск честно нашел оба фрагмента. Но если вопрос задан широко, модель может ответить: "Срок возврата составляет 30 дней". Она не выдумала факт целиком. Она взяла реальную цифру, но приклеила ее не туда.
Из-за этого один верный абзац внутри контекста не делает весь ответ верным. Модель может точно процитировать правило, а следующей строкой добавить условие, которого нигде нет. Люди часто видят знакомую цитату и автоматически доверяют всему ответу целиком. В этом и ловушка.
Галлюцинация в RAG начинается не только тогда, когда поиск промахнулся. Часто она появляется позже, когда модель пытается сделать ответ цельным, коротким и удобным. Если в найденных текстах нет прямого ответа, модель редко останавливается сама. Обычно она заполняет пустоты.
Поэтому RAG ломается не на слове retrieval, а в переходе от найденного текста к финальной формулировке. Чем больше свободы у модели на этом шаге, тем выше шанс получить красивую выдумку вместо аккуратного ответа.
Почему хороший поиск даёт плохой контекст
Хороший поиск не гарантирует хороший ответ. Ретривер обычно ищет текст, похожий по словам или смыслу. Но модели нужен не просто похожий фрагмент, а полный и непротиворечивый контекст. В этом разрыве и начинаются многие галлюцинации.
Самая частая проблема - чанк отрезает то, что меняет смысл. В одном куске остается правило, а дата действия, исключение или фраза "только для старого тарифа" уезжает в соседний фрагмент. Модель видит уверенное утверждение без оговорки и отвечает так, будто правило действует всегда.
Не лучше ситуация, когда в базе лежат две версии одного документа. Поиск честно приносит обе, потому что обе подходят к запросу. Но для модели это не "старая и новая редакция", а два авторитетных текста, которые спорят друг с другом.
Бывает и хуже: в выдачу попадает похожий, но чужой документ. Пользователь спрашивает про внутренний регламент одной команды, а поиск подтягивает документ другого продукта с теми же терминами. Для человека разница заметна по названию отдела или системе. Модель легко склеивает такие куски в один ответ.
Проблему усиливают слабые метаданные. Если у фрагмента нет явной версии, даты действия, владельца документа и типа источника, ранжирование почти слепое. Даже поле updated_at не всегда помогает: файл могли перезалить вчера, хотя сам текст устарел полгода назад.
На практике это выглядит довольно прозаично. Верхние результаты формально релевантны, но относятся к разным версиям правила. Один фрагмент содержит норму, другой - исключение без связи между ними. Среди первых документов может оказаться похожий шаблон из соседней области. Модель получает все сразу и выбирает то, что звучит цельно.
Поэтому полезно оценивать не только retrieval recall, но и качество собранного пакета контекста. Если в него попали спорящие фрагменты без пометки приоритета, ответ уже сломан еще до генерации.
Рабочее правило простое: каждый кусок контекста должен отвечать на три вопроса - что это за документ, для кого он действует и с какого момента. Если система не может это показать, поиск может выглядеть точным по метрикам и все равно давать ошибки после поиска.
Что ломает ответ внутри длинного окна
Даже после удачного поиска модель может выбрать не тот кусок текста и уверенно ответить мимо вопроса. Галлюцинации часто появляются не из-за отсутствия данных, а из-за того, как модель читает длинный контекст.
Первая проблема проста: модель цепляется за яркую фразу. Числа, редкие термины, громкие формулировки и короткие правила притягивают внимание сильнее, чем тихое, но нужное пояснение рядом. Если в одном окне лежат заметка про 152-ФЗ и отдельный фрагмент про B2B-инвойсинг в рублях, ответ на вопрос о хранении логов может внезапно уйти в тему биллинга просто потому, что этот кусок звучит отчетливее.
Есть и перекос по позиции. Начало контекста и его конец модель обычно использует лучше, чем середину. Поэтому важный абзац в центре длинной подборки часто выпадает из ответа, даже если именно он снимает двусмысленность. На практике это выглядит так: вверху лежит общее описание API, внизу короткое ограничение, а посередине спрятано условие, без которого ответ неверен. Модель берет верх и низ, а середину пропускает.
Дубли тоже вредят. Когда один и тот же факт встречается в пяти похожих чанках, модель не становится точнее. Она просто звучит увереннее. Разница опасная: повтор без новых деталей создает ложное ощущение подтверждения, и ответ получается твердым по тону, но пустым по сути.
Отдельная боль - таблицы и списки после нарезки. Если строка таблицы оторвалась от заголовка столбца, смысл легко ломается. Если список условий разделили на два чанка, модель может взять пункт без исключения или без примечания. После этого она склеивает ответ сама, а склейка часто оказывается выдуманной.
Длинное окно не значит, что модель одинаково хорошо понимает все внутри него. Обычно полезнее не расширять контекст до предела, а чистить его перед подачей: убирать повторы, поднимать в начало фрагменты с условиями и не разрывать таблицы там, где теряются связи между колонками и строками. Это дает больше пользы, чем еще десять лишних чанков.
Как собрать контекст перед ответом
Галлюцинации часто начинаются не в модели, а в наборе кусков текста, который вы ей отдали. Если в контексте лежат старая версия инструкции, дубликаты и обрезанный абзац без оговорок, модель уверенно склеит это в красивый, но ложный ответ.
Сначала отфильтруйте документы по метаданным. Дата, версия и тип документа обычно дают больше пользы, чем еще один раунд семантического поиска. Политика 2022 года и политика 2024 года могут быть почти одинаковыми по смыслу, но для ответа разница критична. То же самое с черновиком и утвержденным регламентом.
Почти одинаковые чанки тоже вредят. Когда модель видит три фрагмента с одной мыслью, она воспринимает это как сильный сигнал, даже если все три куска пришли из одной и той же устаревшей инструкции. Дедупликация по смыслу и по источнику обычно режет шум лучше, чем попытка поднять recall любой ценой.
Еще одна частая ошибка после поиска - брать абзац без соседей. Оговорки часто живут рядом: в следующем пункте, в примечании или в таблице под текстом. Если фрагмент содержит правило, подтяните один соседний абзац до и после него. Контекст станет чуть длиннее, зато модель увидит исключения, сроки действия и условия применения.
Длинная свалка из 15-20 кусков редко помогает. Для большинства запросов лучше оставить 3-6 фрагментов, но каждый должен быть чистым и понятным. Хороший контекст не выглядит большим. Он выглядит собранным.
Полезно передавать не только сам текст, но и короткую карточку рядом с ним: источник документа, дату обновления, версию, тип документа и статус, если он есть. Тогда модель опирается не на голые абзацы, а на понятную иерархию. Для внутренней базы это заметно снижает ошибки после поиска: ответ чаще ссылается на действующую редакцию, а не на случайный похожий кусок.
В командах с требованиями 152-ФЗ это особенно заметно. Если вопрос касается хранения логов или маскирования PII, один фрагмент из старого регламента может испортить весь ответ. Лучше дать модели четыре актуальных куска с датой и версией, чем десять фрагментов без контекста происхождения.
Если коротко, сборка контекста должна делать две вещи: убирать лишнее и возвращать утраченный смысл. Когда эти два шага работают, промпт уже не пытается спасать плохую выборку, и галлюцинации заметно падают.
Как править промпт, а не только поиск
Галлюцинации часто рождаются не в поиске, а на последнем шаге, когда модель превращает найденные куски в гладкий ответ. Если промпт просит "ответь полно и уверенно", модель добирает недостающее сама. Поэтому правка промпта часто снижает ошибки быстрее, чем еще один раунд настройки поиска.
Сначала уберите у модели право фантазировать. В промпте лучше прямо сказать: используй только факты из переданных фрагментов. Если в них нет ответа, напиши "нет данных в контексте". Для людей это звучит сухо, зато в проде такая честность лучше красивой выдумки.
Хорошо работает и требование показывать опору после каждого тезиса. Это может быть номер фрагмента, название документа или короткая цитата. Когда модель знает, что ей придется предъявить источник, она реже придумывает детали и чаще замечает пробелы.
Особенно жестко стоит ограничить числа, сроки и условия. Именно их модель любит достраивать "по смыслу": даты запуска, лимиты, проценты, штрафы, версии договора. Если факт не назван в контексте для RAG, его нельзя оценивать, округлять или угадывать.
Один прием помогает сильнее, чем кажется: разделите ответ на два шага. Сначала модель выписывает факты из контекста. Потом отдельно делает вывод только на их основе. Так сразу видно, где закончились данные и где началась интерпретация.
- Блок 1: "Факты из контекста" с цитатой или ID фрагмента
- Блок 2: "Ответ" без новых фактов
- Если данных мало, модель пишет, чего именно не хватает
- Если фрагменты спорят друг с другом, модель отмечает конфликт, а не склеивает версии
Для внутренней базы это видно сразу. Допустим, в одном документе сказано, что возврат возможен в течение 14 дней, а про исключения ничего нет. Плохой промпт даст уверенный ответ про "стандартные исключения". Нормальный промпт остановит модель на том, что есть в тексте, и покажет источник.
Короткий шаблон может выглядеть так:
Ответь только по контексту ниже.
После каждого тезиса укажи источник: [doc_id] или короткую цитату.
Если в контексте нет данных, так и напиши: "нет данных в контексте".
Не додумывай числа, сроки, условия, названия версий и ограничения.
Сначала выпиши факты из контекста, затем дай итоговый ответ без новых фактов.
Простой пример из внутренней базы знаний
Сотрудник банка спрашивает внутреннего помощника: какой лимит по карте и какой срок льготного периода действует сейчас. Поиск делает то, что от него ждут, но только на первый взгляд. Он находит новый тариф с актуальным лимитом и старую памятку, где остался прежний срок.
Модель читает оба фрагмента и собирает ответ так, будто все сходится. Лимит она берет из нового файла, срок - из старого. Получается гладкая, уверенная фраза, но в базе нет документа, где эти два условия стоят рядом.
Так и выглядят галлюцинации в рабочем процессе. Поиск не соврал. Контекст не пустой. Ошибка появляется в момент склейки, когда модель видит несколько похожих источников и не понимает, какой из них главнее.
Где ломается ответ
Во внутренней базе это случается часто. Новый тариф уже вступил в силу, а старая памятка все еще лежит в индексе, потому что ее не сняли с публикации или не понизили в приоритете. Для человека разница заметна по дате и типу документа. Для модели оба текста похожи: в обоих есть карта, лимит, льготный период и служебные формулировки.
Если в промпте нет жесткого правила, модель старается дать полный ответ, а не честный. Она не пишет, что данные расходятся. Она достраивает недостающий кусок из соседнего документа.
Что убирает ошибку
Обычно помогают две простые правки. Первая - фильтр по дате и статусу документа перед сборкой контекста. Если есть действующий тариф, старую памятку лучше вообще не отдавать в окно модели. Вторая - жесткий промпт: брать связанные параметры только из одного документа или одной версии.
Формулировка может быть простой: если лимит и срок найдены в разных источниках, не объединяй их в один ответ; сообщи о конфликте и назови документы, где найдены значения. Это звучит строже, зато резко снижает ошибки после поиска.
В банке такой промах дорогой даже без внешнего клиента. Сотрудник колл-центра прочитает ответ, поверит ему и передаст неверные условия дальше. Намного лучше получить короткий отказ с пометкой о конфликте версий, чем красивый ответ, которого нет ни в одном документе.
Ошибки, которые команды повторяют
Чаще всего команды чинят не ту часть пайплайна. Они смотрят на recall поиска, точность reranker или средний score по выдаче, а потом удивляются, почему финальный ответ все равно врет. Пользователь видит не поиск, а итоговый текст. Если модель смешала два фрагмента, додумала пропущенную дату или уверенно пересказала черновик, метрики retrieval уже не спасают.
Первая частая ошибка - держать в индексе все подряд. В базу попадают черновики, старые регламенты, отмененные версии и страницы с пометкой "обновим позже". Поиск честно находит такой текст, а модель честно делает из него ответ. Если в базе лежат две несовместимые версии инструкции, модель редко признает конфликт. Обычно она склеивает их в одну правдоподобную выдумку.
Вторая ошибка - резать документы по символам, а не по смыслу. Когда абзац с условием попал в один chunk, а исключение к нему - в другой, модель видит только половину правила. Так рождаются ошибки после поиска: кусок найден, но смысл потерян. Намного лучше работают фрагменты по логическим блокам: раздел, подпункт, таблица с подписью, вопрос-ответ.
Третья ошибка - складывать весь найденный текст в один большой запрос. На бумаге это выглядит безопасно: чем больше контекста, тем меньше шанс придумать. На деле модель получает шум, дубли и противоречия. Она хуже различает, какой фрагмент главный, а какой просто похож по словам. Длинное окно не лечит плохой контекст, оно часто прячет проблему.
Еще одна привычка, которая портит ответы, - просить модель звучать слишком уверенно. Фразы вроде "дай точный ответ", "не сомневайся", "отвечай как эксперт" толкают ее к догадкам там, где в контексте дыра. Для RAG лучше другое поведение: цитируй источник, помечай неопределенность, прямо говори, что данных не хватает.
Быстрый тест обычно вскрывает эти ошибки. Сравните найденные фрагменты и финальный ответ на 20 реальных вопросах. Проверьте, нет ли в индексе отмененных и дублирующих документов. Посмотрите, где chunk обрезает мысль посередине. Уберите лишние фрагменты из prompt и замерьте, стал ли ответ точнее. И замените требование "отвечай уверенно" на правило "не заполняй пробелы догадками".
Если после такого теста ответ стал короче, но чище, это хороший знак. Значит, проблема была не в том, что поиск нашел мало текста, а в том, что система давала модели слишком много поводов додумывать.
Быстрые проверки перед релизом
Многие галлюцинации видно не на демо, а в коротком чек-листе перед запуском. Если пройти его честно, часть выдумок уйдет еще до первых пользователей.
Смотрите не на то, как убедительно звучит ответ, а на то, откуда взялась каждая спорная фраза. Хороший тон часто маскирует плохой контекст.
Перед релизом стоит проверить несколько простых вещей. Убедитесь, что в каждом чанке есть дата, источник и версия документа. Если модель видит абзац без метаданных, она не понимает, что новее и чему верить. Проверьте, видит ли модель соседний абзац там, где смысл зависит от оговорки, сноски или исключения. Спорные места почти всегда ломаются на границе чанков.
Добавьте явный путь к ответу "не знаю". Если в контексте нет точного факта, система должна остановиться, а не достраивать пробелы. Сверяйте результат по цитатам, а не по общему впечатлению. Ответ может звучать логично и при этом подменять формулировку из источника. И отдельно ловите конфликт двух источников до генерации. Если одна инструкция обновлена, а другая нет, модель часто склеивает их в несуществующее правило.
Особенно часто это всплывает во внутренних базах знаний. Например, в старом регламенте написано, что запрос согласует один отдел, а в новой версии - уже другой. Если retrieval принес обе версии без пометки приоритета, модель может собрать гибридный ответ, которого нет ни в одном документе.
Отдельно проверьте отказ на неполном контексте. Дайте системе вопрос, на который в базе нет прямого ответа, но есть похожие фрагменты. Если она все равно отвечает уверенно, у вас не поиск слабый, а политика генерации слишком мягкая.
Для команд, которые работают с регламентами, договорами или документами по 152-ФЗ, это особенно важно. Там ошибка редко выглядит как явная фантазия. Чаще это один неверный срок, одна пропущенная оговорка или ссылка на старую редакцию.
Нормальный релизный тест выглядит скучно: 20-30 вопросов, ручная сверка цитат, несколько намеренных конфликтов в источниках и отдельная группа запросов без ответа в базе. Но именно такие проверки лучше всего режут ошибки после поиска.
Что делать после первых правок
После первых изменений не смотрите только на общий процент удачных ответов. Он часто прячет главную проблему: поиск стал лучше, а финальный ответ все равно додумал лишнее или перепутал детали.
Соберите короткий набор живых вопросов, на которых система уже ошибалась. Лучше 30-50 реальных запросов из саппорта, базы знаний или внутреннего поиска, чем 300 слишком чистых тестов, придуманных вручную. В таком наборе обычно быстро видно, где именно рождаются галлюцинации.
Разберите пайплайн по слоям
Проверяйте каждый прогон отдельно по трем частям: что нашел поиск, какой контекст ушел в модель и что модель ответила в итоге. Если смотреть только на финальный текст, команда часто чинит не ту часть системы.
Например, вопрос про лимиты API мог получить правильный документ, но в контекст попал длинный кусок с устаревшей таблицей и соседним разделом про тарифы. Поиск в этом случае сработал нормально. Ошибка сидит в сборке контекста или в промпте, который не требует опираться только на явные факты из фрагментов.
Для каждого вопроса полезно вести простую карточку: запрос пользователя, найденные документы и их порядок, итоговый контекст, который увидела модель, финальный ответ и тип ошибки. Этого хватает, чтобы увидеть повторяющийся сбой, а не спорить по ощущениям.
Меняйте один параметр за раз. Сначала, например, уменьшите число фрагментов с 8 до 5. Потом проверьте эффект. После этого поменяйте инструкцию в промпте. Если крутить все сразу, вы не поймете, что реально помогло, а что просто случайно совпало.
Записывайте эффект не только в духе "стало лучше" или "стало хуже". Смотрите на более приземленные вещи: сколько ответов начали ссылаться не на тот документ, сколько раз модель добавила факт, которого нет в контексте, сколько раз она честно сказала "не знаю". Иногда рост таких отказов - это хороший знак, а не регресс.
Если вы гоняете много тестов на разных моделях, порядок тоже имеет значение. Нужны единые логи, понятный учет стоимости и одинаковая точка входа для всех прогонов. Для команд, которым важно держать логи, биллинг и обработку данных внутри РФ, это удобно делать через один OpenAI-совместимый эндпоинт, например через RU LLM на rullm.com. Так проще сравнивать модели между собой и не разносить эксперименты по разным провайдерам.
Хороший результат после первых правок выглядит скучно: меньше красивых ответов с выдумками, больше коротких и точных ответов по найденным данным. Для продакшена это почти всегда правильный обмен.
Часто задаваемые вопросы
Что вообще считается галлюцинацией в RAG?
Это не только случай, когда поиск ничего не нашел. Чаще поиск приносит полезные куски, а модель потом склеивает их в один гладкий ответ и добавляет связь, которой нет в документах.
Обычно ошибка появляется там, где в контексте не хватает прямого ответа, есть конфликт версий или правило оторвали от оговорки.
Почему хороший поиск все равно дает неверный ответ?
Да. Поиск может найти релевантные фрагменты, но они могут относиться к разным версиям документа, разным продуктам или разным условиям.
Модель видит все сразу и выбирает то, что звучит цельно. В итоге ответ выглядит уверенно, хотя ни один источник не говорит именно так.
Как нарезка документов ломает ответ?
Потому что чанк часто режет смысл пополам. В одном куске остается правило, а дата действия, исключение или примечание уезжает в соседний.
Если модель получает только первую часть, она отвечает так, будто правило действует всегда. Для регламентов, тарифов и договоров это частый источник ошибок.
Сколько фрагментов лучше отдавать модели?
Обычно лучше дать 3–6 чистых фрагментов, чем 15 похожих и спорящих между собой. Большая свалка текста чаще мешает, чем помогает.
Оставляйте куски, которые реально отвечают на вопрос, и убирайте дубли. Если правило зависит от соседнего абзаца, подтяните его тоже.
Какие метаданные сильнее всего снижают ошибки?
Минимум нужны дата, версия, тип документа и источник. Еще полезно знать статус: черновик это, действующая редакция или архив.
Без этих полей ранжирование почти слепое. Тогда модель легко берет старый текст как актуальный и смешивает его с новым.
Почему длинное окно контекста не спасает?
Потому что модель читает длинный контекст неравномерно. Она часто лучше использует начало и конец, а важный абзац в середине пропускает.
Еще вредят дубли, таблицы без заголовков и яркие фразы, которые перетягивают внимание. Поэтому длинное окно не заменяет аккуратную сборку контекста.
Что поменять в промпте, чтобы модель меньше выдумывала?
Сделайте промпт жестче. Прямо запретите модели добавлять факты вне контекста и разрешите честно писать: "нет данных в контексте".
Хорошо работает простой порядок: сначала выписать факты из фрагментов с указанием источника, потом дать вывод без новых деталей. Так модель реже додумывает числа, сроки и условия.
Что делать, если найденные документы противоречат друг другу?
Не давайте модели склеивать их в один ответ. Если лимит, срок или правило пришли из разных версий, система должна отметить конфликт и назвать источники.
На практике лучше отфильтровать старые документы еще до генерации. Если этого не сделать, модель почти всегда попытается собрать "средний" ответ.
Как быстро проверить RAG перед релизом?
Проверьте 20–30 реальных вопросов руками. Смотрите не на красивый тон ответа, а на то, откуда взялась каждая спорная фраза.
Отдельно полезно дать вопросы без прямого ответа в базе и вопросы с намеренным конфликтом версий. Если модель в таких случаях не останавливается, проблема в сборке контекста или в промпте.
Как понять, что правки реально помогли?
Смотрите на три вещи отдельно: что нашел поиск, какой контекст ушел в модель и что она сказала в итоге. Если смотреть только на финальный текст, легко чинить не тот слой.
Полезно считать, сколько раз модель сослалась не на тот документ, сколько раз добавила факт вне контекста и сколько раз честно отказалась отвечать. Рост таких отказов часто значит, что система стала надежнее.