Feature flags для LLM-функций без правки конфигов вручную
Feature flags для LLM-функций помогают включать модели по аккаунтам, ролям и сегментам без правки конфигов и с понятным контролем риска.
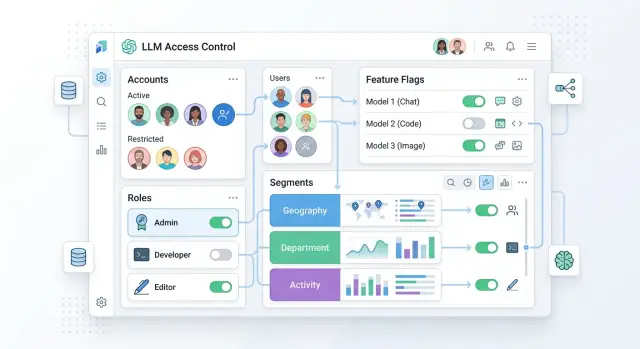
Где ломается ручное включение моделей
Ручная схема почти всегда начинается безобидно. Появляется новая модель, и команда добавляет пару строк в конфиг для одного клиента. Через месяц таких клиентов уже десять, правил - несколько десятков, а быстро ответить, кто и почему получил доступ, уже не получается.
Конфиг постепенно превращается в склад исключений. Одному аккаунту модель открыли по договоренности с продажами, другому - по просьбе CTO, третьему - на неделю для пилота. Когда правила живут в разных файлах, таблицах и заметках, продукт начинает вести себя непредсказуемо.
Часто все ломается на ролях. В интерфейсе у пользователя роль analyst или admin, но доступ к модели настраивают не по роли, а по аккаунту, тарифу или личной договоренности. В итоге интерфейс говорит одно, саппорт видит другое, а сервер применяет третье правило.
С пилотными группами еще сложнее. Вы хотите дать новую модель только пяти клиентам, чтобы проверить качество и стоимость. Если команда делает это вручную, кто-то почти всегда забывает один аккаунт, копирует старое правило или включает модель сразу на весь сегмент. Одна ошибка, и дорогая модель уходит не тем пользователям.
В среде с регуляторными требованиями это особенно неприятно. Если компания обязана объяснить, кто получил доступ к какой функции и когда, ручные правки плохо проходят такую проверку. В логах видно, что запрос ушел, но не всегда понятно, по какому правилу система пустила пользователя именно к этой модели.
Даже единый эндпоинт не решает эту проблему сам по себе. Если команда работает через совместимый с OpenAI шлюз вроде RU LLM, маршрут до модели действительно становится проще. Но хаос никуда не исчезает, если правила доступа по-прежнему сидят в конфигах.
Самая дорогая ошибка здесь не техническая, а организационная. Люди перестают доверять схеме. Разработчики боятся включать новые модели, саппорт не может быстро ответить клиенту, а поэтапный запуск тормозит из-за каждой мелкой правки. В этот момент feature flags для LLM-функций перестают быть удобной опцией и становятся обычной рабочей практикой.
Что должен решать feature flag
Если функцию на базе LLM приходится включать через правку конфига, команда быстро теряет контроль. Сегодня вы открыли новую модель двум пилотным клиентам, завтра забыли убрать временное правило, а через неделю уже никто не может объяснить, почему доступ есть у одной группы и нет у другой.
Хороший feature flag решает не только задачу вкл/выкл. Он отвечает на более полезный вопрос: кому можно пользоваться этой функцией прямо сейчас. Для LLM это обычно зависит от аккаунта, роли, сегмента клиента, тарифа и иногда от региона.
На практике хватает четырех вещей. Система должна уметь открывать доступ одному аккаунту, списку аккаунтов, роли или сегменту. Правила не должны спорить друг с другом, поэтому им нужен фиксированный приоритет. Доступ должен включаться и выключаться одним действием, без ручного обхода сервисов. И еще нужна история изменений: кто поменял правило, зачем и до какой даты оно действует.
Приоритет лучше определить один раз и больше не обсуждать его в каждом релизе. Рабочий вариант простой: явный запрет выше явного разрешения, правило аккаунта выше правила сегмента, сегмент выше роли, а общий флаг по умолчанию стоит внизу. Тогда система ведет себя предсказуемо. Если крупному клиенту временно нельзя давать новую модель, более широкое правило для всего сегмента этот запрет не перетрёт.
Нужен и сценарий быстрого закрытия доступа. У новой модели может вырасти задержка, цена или число ошибок. В этот момент команде нужен один переключатель, а не цепочка правок в нескольких репозиториях. Если доступ к моделям идет через единый шлюз, флаг должен менять поведение сразу, без смены SDK, клиентского кода и промптов.
Без истории изменений такой механизм быстро теряет смысл. В журнале должен оставаться не только сам факт смены статуса, но и контекст: кто изменил правило, по какой задаче, для какого клиента, до какой даты и что система сделает после истечения срока. Тогда временный доступ не живет вечно, а спорные случаи можно разобрать без догадок.
Если после изменения флага команда за минуту понимает, кто получил доступ, почему и на какой срок, схема работает нормально.
Как разложить правила доступа
Проблемы начинаются там, где в одном правиле смешали все сразу: функцию, модель, тариф, роль и лимиты. Тогда любое изменение тянет за собой правку конфигов, а потом никто не понимает, почему один клиент видит новую функцию, а другой нет.
Проще разнести это по слоям. Флаг функции отвечает только за то, доступна ли возможность вообще. Выбор модели решает, какая модель подходит этому пользователю или сценарию. Роли описывают, кто может запускать сценарий внутри аккаунта. Тариф и лимиты задают объем, частоту и бюджет. Резервный маршрут определяет, что делать при сбое или пустом правиле.
Такой разбор убирает лишнюю путаницу. Например, функция суммаризации звонка может быть включена для аккаунта целиком, но менеджер получает одну модель, а аналитик другую. При этом лимит на число запросов живет отдельно и не ломает доступ по ролям.
Новый аккаунт должен получать понятный дефолт. Обычно это безопасный режим: функция выключена или включена только базовая модель с жестким лимитом. Худший вариант - оставлять пустое состояние, когда система пытается угадать поведение на лету. Именно из таких дыр потом вырастают случайные доступы и лишние расходы.
Приоритет правил
Приоритет нужен один, короткий и записанный явно. На практике удобно, когда правило аккаунта сильнее правила сегмента, а сегмент сильнее роли. Тогда персональное исключение для конкретного клиента не затирается общей логикой для всей группы.
Роли лучше не смешивать с тарифами. Роль отвечает на вопрос кому можно, тариф - что входит, лимит - сколько раз и по какой цене. Если склеить это в одну сущность, любой апгрейд тарифа начнет случайно открывать модели людям, которым их давать не собирались.
Нужен и резервный вариант. Если правило не сработало, система не должна падать с ошибкой выбора модели. Она должна сделать одно из двух: вернуть явный отказ в доступе или переключить запрос на заранее заданную базовую модель. Для внутренних инструментов чаще удобнее второй путь. Для сценариев с чувствительными данными и строгим аудитом надежнее первый.
Хорошее правило можно прочитать вслух одним предложением. Например: функция включена для сегмента pilot, роль analyst может ей пользоваться, для аккаунта bank-17 выбрана модель A, а при недоступности используется модель B. Если такое правило нельзя объяснить без длинной схемы, конструкция уже слишком сложная.
Как настроить схему без ручной правки
Ручная правка конфигов ломается сразу, как только у вас появляется больше одной модели и больше одного типа доступа. Сегодня вы открыли новую функцию двум аккаунтам, завтра дали ее только аналитикам, а через неделю закрыли доступ для тестового сегмента. Если делать это через файлы и деплой, команда быстро запутается.
Надежнее собрать схему из двух слоев. В первом слое вы описываете, что вообще можно включать и выключать: модели, режимы, инструменты, длинный контекст, web search, дообученные варианты. Во втором слое храните правила, которые отвечают на один вопрос: кому это доступно сейчас.
Для начала хватает одной понятной таблицы правил. В ней обычно есть идентификатор функции или модели, тип субъекта - аккаунт, сегмент или роль, конкретное значение, действие allow или deny, приоритет, срок действия и автор изменения. Не пытайтесь описать все случаи жизни сразу. Если таблица понятна человеку без диаграммы на двадцать экранов, вы выбрали нормальную отправную точку.
После этого задайте жесткий порядок проверки. Иначе два правила начнут спорить друг с другом. Сначала система проверяет обязательные запреты, потом точечные правила по аккаунту, потом роли, потом сегменты, и только в конце смотрит на дефолтное правило. Если сработало правило с более высоким приоритетом, дальше проверка не идет.
Где менять флаги
Менять такие правила лучше не через git и не через редактирование JSON на сервере. Вынесите управление в простую панель или внутренний API с валидацией. Пользователь выбирает модель, субъект и срок действия, а система сразу показывает предварительный результат: кому доступ откроется, а кому нет.
Если вы работаете через совместимый с OpenAI эндпоинт, такой слой удобно держать выше маршрутизации. Сначала продукт решает, можно ли дать доступ конкретному аккаунту или роли, и только потом отправляет запрос в нужную модель.
У каждого флага должен быть срок жизни и понятный откат. Временные включения должны истекать сами. Для рискованных запусков заранее задайте состояние rollback, чтобы при ошибке не вспоминать ночью, какой конфиг был активен вчера.
Простой пример: вы даете новую модель только сегменту pilot до пятницы, но закрываете ее для роли contractor. Такое правило читается за минуту и меняется без деплоя.
Пример: новая модель только для части клиентов
Допустим, вы хотите открыть доступ к новой модели не всем сразу, а только пилотной группе B2B-клиентов. Это обычная ситуация: модель может отвечать лучше, но пока неясно, как она ведет себя по цене, задержке и качеству на живых запросах. Старую модель в такой схеме лучше оставить вариантом по умолчанию.
Рабочее правило выглядит просто. Если аккаунт входит в сегмент pilot_b2b, а пользователь имеет роль admin, интерфейс показывает новую модель в списке. Для остальных ничего не меняется: они продолжают работать со старой моделью. Так поэтапный запуск не ломает привычный сценарий и не создает лишнюю нагрузку на поддержку.
Лучше начать с 5-10 аккаунтов, где команда готова давать обратную связь. На первом шаге откройте новую модель только администраторам аккаунта. Старую оставьте дефолтной для всех остальных сценариев. Дальше в течение недели собирайте метрики и короткие отзывы, а потом решайте, расширять пилот или нет.
Почему только администраторы? Обычно они быстрее замечают странное поведение, понимают, где модель помогает, и могут сами решить, стоит ли давать доступ коллегам позже. Если открыть функцию сразу всем пользователям пилотного аккаунта, вы смешаете полезный отзыв с обычным шумом.
На первой неделе смотрите не на одну цифру, а на связку показателей. Полезно отслеживать ошибки по типам, среднюю стоимость запроса, долю таймаутов, частоту ручного возврата на старую модель и короткий комментарий от администратора аккаунта. Если новая модель отвечает на 12% лучше, но счет растет вдвое, это уже неудачный пилот, а дорогой эксперимент.
Еще лучше заранее задать правило остановки. Например, если доля ошибок выше базовой модели на 3% или средняя цена на задачу выросла больше чем на 25%, пилот не расширяют. Если метрики в норме, можно открыть доступ следующему сегменту и снова двигаться постепенно.
Такой запуск выглядит скучно. И это хорошо. Когда новая модель входит в продукт тихо и предсказуемо, команда получает нормальные данные вместо аварийных правок по ночам.
Где проверять флаги в продукте
Проверку нужно ставить в двух местах: перед показом функции в интерфейсе и на сервере во время самого запроса. Если проверить доступ только в UI, пользователь все равно сможет вызвать метод напрямую через API, SDK или старую версию клиента.
В интерфейсе правило нужно проверять рано. Пользователь не должен видеть кнопку, модель в списке или тарифную опцию, если доступ ему не положен. Это убирает лишние вопросы в поддержку и не создает ложных ожиданий. Но UI дает только удобство. Защиту он не обеспечивает.
Настоящую защиту дает сервер. Когда приходит запрос на генерацию, сервер заново считает то же правило: аккаунт, роль, сегмент, тариф, регион и стадию запуска. Если правило не прошло, сервер должен остановить вызов до обращения к модели. Так вы не откроете доступ случайно, даже если фронтенд ошибся, кеш устарел или кто-то отправил запрос вручную.
Лучше держать одну точку принятия решения. Не три разные проверки в разных сервисах, а общий policy layer, который UI и API читают одинаково. Иначе рассинхрон появится очень быстро: в кабинете функция скрыта, а через сервер она доступна. Или наоборот.
Пользователю достаточно короткой причины отказа. Например: модель недоступна для вашей роли или функция еще не включена для аккаунта. Лишние детали лучше не показывать. Не нужно раскрывать внутренний сегмент, порядок правил или условия, по которым проходит другой клиент. Эти сведения должны оставаться в логах и админке.
Если вы запускаете новую модель поэтапно, проверьте простой сценарий: обычный сотрудник не видит кнопку, менеджер аккаунта видит, а сервер в обоих случаях ведет себя так же. В доступе к моделям именно такие скучные проверки чаще всего спасают от дорогих ошибок.
Ошибки, которые ломают запуск
Чаще всего запуск ломает не сама модель, а логика доступа. Feature flags быстро превращаются в путаницу, если правила растут по ходу дела, а команда чинит их точечно.
Первая типичная ошибка - смешивать роль пользователя и тип аккаунта. Это разные вещи. Роль отвечает за права внутри продукта, а аккаунт - за тариф, договор, регион хранения данных или сегмент клиента. Если склеить это в одно правило, вы рано или поздно откроете модель не тем людям.
Вторая ошибка - держать список клиентов прямо в коде. Сначала это кажется быстрым решением: добавили пять account_id и пошли дальше. Через месяц никто не помнит, зачем там половина записей, а любое изменение требует релиза. Если аккаунтов десятки, а моделей несколько, такой список начинает жить своей жизнью.
Третья ошибка - забыть выключить старый эксперимент. В продукте уже работает новый запуск, но старый флаг все еще активен для части трафика. В итоге две логики спорят друг с другом. Пользователь то видит кнопку, то теряет доступ, то снова получает его после следующего деплоя. У каждого флага нужен владелец и дата отключения.
Четвертая ошибка - закрыть только интерфейс и забыть про сервер. Кнопку можно скрыть за флагом, но этого мало. Если сервер или шлюз не проверяет то же правило, запрос все равно уйдет в модель. Поэтому проверка должна стоять до маршрутизации запроса, а не только в UI.
Наконец, команды часто недооценивают откат. Новая модель может резко поднять счет или дать всплеск задержки. Если у вас нет простого переключения на резервную модель, запуск быстро превращается в пожар.
Короткий минимум выглядит так: разделяйте роль, аккаунт и сегмент в разных полях, храните правила вне кода, задавайте дату отключения для каждого эксперимента, проверяйте доступ и в UI, и на сервере, а сценарий отката готовьте до первого запуска.
Что писать в логах и аудите
Журнал смены флага должен отвечать на простой вопрос: кто, что и зачем изменил, и как это сказалось на реальных запросах. Если через неделю модель начала отвечать иначе или выросли расходы, команда должна быстро собрать цепочку событий без переписки в чате и поиска по коммитам.
Для каждой смены правила фиксируйте не только новое значение, но и контекст решения. Нужны имя сотрудника или сервиса, точное время изменения, время вступления правила в силу, затронутая модель, аккаунт, роль или сегмент, а также причина. Причина не должна быть пустой. Короткой записи вроде пилот для retail уже достаточно, если она понятна всем.
Полезный набор полей обычно такой: идентификатор изменения и автора, старое и новое правило, модель и субъект изменения, время активации, срок действия, комментарий с причиной и номером задачи. Но этого мало без связи с боевыми запросами.
После смены флага каждый запрос тоже должен оставлять след. Лог должен показывать, какой флаг проверили, какое правило совпало, какую модель система выбрала, был ли резервный переход, сколько занял маршрут и чем закончился вызов. Тогда видно не только сам факт изменения, но и его эффект.
Пример простой. Команда открыла Qwen 3 только для двух B2B-аккаунтов и роли analyst с 10:00. В аудите должна остаться запись, кто включил правило, с какой даты оно активно и почему его одобрили. А в запросных логах после 10:00 нужно видеть, что аккаунт A попал под новое правило и ушел в Qwen 3, а аккаунт B не попал из-за другой роли и остался на прежней модели.
Если вы используете RU LLM, полезно связывать запись о флаге с идентификатором запроса и следом аудита по каждому вызову. Для сред с требованиями 152-ФЗ это практичная мера, а не формальность. И отдельно стоит маскировать PII в комментариях и полезной нагрузке, иначе хороший аудит сам станет источником риска.
Быстрые проверки перед запуском
Перед запуском полезно пройти короткий чек не по коду, а по реальному доступу. Часто команда включает новую модель для пары аккаунтов, а потом выясняет, что ее уже видят все пользователи в интерфейсе, хотя вызвать через API ее пока нельзя. Бывает и наоборот: кнопка скрыта, а интеграции уже шлют запросы в прод.
Проверьте это на тестовом аккаунте и на одном реальном аккаунте из целевого сегмента.
- Убедитесь, что модель видят только нужные люди. Отдельно проверьте обычного пользователя, администратора и внутреннюю команду.
- Отдельно проверьте API. Пользователь может не видеть модель в списке, но все равно вызвать ее по
id, если сервер не проверяет флаг. - Сверьте лимиты. Нужны хотя бы бюджет на аккаунт и rate limit, чтобы один пилот не сжег месячный запас за вечер.
- Дайте support простой экран или внутреннюю команду, где видно, какой флаг включен, для кого, с какого времени и кто его менял.
- Проверьте откат. Команда должна снять доступ за минуту, без деплоя и без ручной правки конфигов в нескольких сервисах.
Особенно часто ломается граница между видит и может вызвать. Если у вас есть веб-приложение, мобильный клиент и API, каждый канал нужно проверить отдельно. Один и тот же флаг должен работать одинаково везде.
Хороший быстрый тест выглядит так: вы берете аккаунт из пилотной группы, делаете запрос, видите модель в интерфейсе, получаете успешный ответ через API, затем выключаете флаг и сразу повторяете оба действия. После этого интерфейс скрывает модель, а сервер возвращает понятную ошибку доступа, а не 500.
Если трафик идет через единый шлюз, перед запуском полезно сверить и фактический маршрут запроса. Так вы сразу увидите, куда ушел вызов, какой лимит сработал и остался ли след в аудите. Это сильно экономит время в первый день запуска.
Что делать дальше
Начните с простой матрицы доступа. По строкам укажите аккаунты или типы клиентов, по столбцам - роли, сегменты и модели. В одной таблице должно быть видно, кто может видеть модель в интерфейсе, кто может вызывать ее через API и кто получает доступ только после отдельного одобрения.
Такая матрица быстро находит путаницу. Команде часто кажется, что правило одно, а потом выясняется, что enterprise-клиенты, внутренние тестеры и support живут по разным условиям. Если матрицы нет, флаги начинают спорить друг с другом в самый неудобный момент.
Не пытайтесь покрыть все случаи сразу. Начните с одного флага и одного пилотного сегмента. Например, откройте новую модель только для двух финтех-аккаунтов и только для ролей admin и analyst. Этого уже достаточно, чтобы проверить логику, логи и откат без шума на всю клиентскую базу.
Дальше сведите правила, аудит и откат в один слой. Продукту нужен понятный ответ на любой запрос: почему этот пользователь увидел модель, почему другой не увидел и кто изменил правило вчера вечером. Ошибку в баннере замечают быстро. Ошибку в доступе к модели часто находят только после счета или жалобы клиента.
Если своя система флагов у вас уже есть, не нужно ломать ее ради новой схемы. Проще оставить флаги в привычном месте, а слой маршрутизации моделей и регуляторных проверок вынести отдельно. Для команд, которым нужен единый совместимый с OpenAI эндпоинт, маршрутизация моделей и аудит внутри РФ, RU LLM можно поставить рядом с существующей системой правил: base_url меняется, а SDK, код и промпты остаются прежними.
Финальная проверка очень простая. Новый аккаунт должен получать доступ по матрице за несколько минут, без правки кода, без похода в три админки и без ручного отката ночью. Если это уже работает, схема готова к нормальному поэтапному запуску.
Часто задаваемые вопросы
Зачем нужен feature flag, если уже есть единый эндпоинт?
Нет. Единый эндпоинт упрощает маршрут до модели, но не решает право доступа. Флаг отвечает, кому сейчас можно видеть и вызывать модель: аккаунту, роли, сегменту или пилоту. Без него команда снова правит конфиги и теряет историю изменений.
Какой приоритет правил лучше задать?
Лучше взять простой порядок и не менять его от релиза к релизу. deny ставьте выше allow, правило аккаунта — выше сегмента, сегмент — выше роли, а дефолт держите внизу. Тогда персональный запрет для клиента не затрет общее разрешение для группы.
Чем роль отличается от сегмента и тарифа?
Роль отвечает за права человека внутри аккаунта. Сегмент описывает группу клиентов, а тариф — что входит в пакет и в каких объемах. Если смешать эти поля, апгрейд тарифа легко откроет модель тем, кому ее не планировали давать.
Где проверять доступ: в интерфейсе или на сервере?
Ставьте проверку в двух местах. Интерфейс должен скрывать кнопку и модель из списка, а сервер обязан заново считать правило перед вызовом модели. Так пользователь не обойдет ограничение через API, старый клиент или прямой запрос.
Как безопасно открыть новую модель только части клиентов?
Возьмите маленький сегмент, например 5–10 аккаунтов, и сначала откройте модель только администраторам. Старую модель оставьте по умолчанию. Через несколько дней посмотрите на ошибки, цену, таймауты и ручной возврат на старую модель, а потом решайте, расширять пилот или нет.
Что делать, если правило не сработало?
Не оставляйте это на случай. Заранее выберите одно поведение: либо сервер возвращает понятный отказ в доступе, либо переводит запрос на базовую модель. Для внутренних инструментов часто удобнее запасная модель, а для чувствительных сценариев лучше явный отказ.
Что писать в логах и аудите по флагам?
В журнале держите не только новое значение, но и контекст. Записывайте, кто изменил правило, когда оно вступило в силу, для какой модели, аккаунта, роли или сегмента, на какой срок и по какой задаче. В запросном логе храните совпавшее правило, выбранную модель, резервный переход и итог вызова.
Почему плохо держать список аккаунтов в коде?
Потому что такой список быстро теряет смысл. Сначала это пара account_id, а потом каждое изменение требует релиза, и никто не помнит, зачем половина записей осталась в файле. Правила лучше хранить в панели или внутреннем API, где видны срок, автор и причина изменения.
Как сделать быстрый откат без ночных правок?
Сделайте один переключатель выше слоя маршрутизации. Он должен сразу закрывать доступ или возвращать трафик на резервную модель без деплоя и без правок в нескольких сервисах. Еще задайте срок жизни флага, чтобы временное включение не осталось в проде навсегда.
С чего начать, если системы флагов еще нет?
Начните с одной таблицы правил и простой матрицы доступа. В таблице храните субъект, действие, приоритет, срок и автора, а в матрице проверяйте, кто видит модель в UI и кто может вызвать ее через API. Этого хватает, чтобы запустить первый пилот без ручной правки конфигов.