Переключение модели без потери контекста в диалоге
Переключение модели без потери контекста требует простой схемы хранения: сообщения, резюме, служебные поля, fallback и короткие проверки.
Почему разговор ломается при смене модели
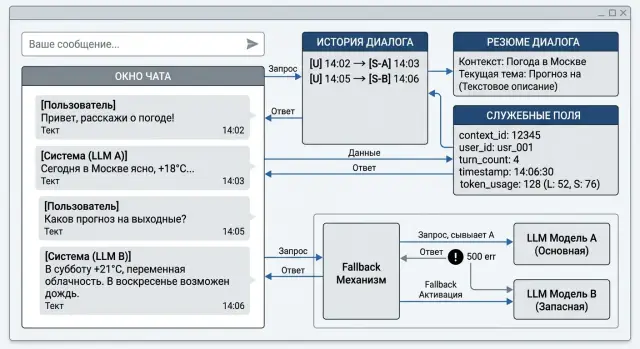
Разговор обычно ломается не из-за самой смены модели, а из-за того, что меняется состояние диалога. Пока чат идет с одной моделью, система привыкает к ее ожиданиям: длине истории, формату system-сообщения, именам полей, служебным меткам. Когда включается fallback между LLM, эти допущения быстро всплывают.
Первая проблема простая: модели по-разному держат контекст. Одна помнит детали из начала чата - имя клиента, запрет на сокращения, выбранный тариф, прошлое решение. Другая теряет это через несколько ходов или хуже сжимает длинную историю. Пользователь видит странный эффект: он уже все объяснил, а новый ответ будто начинает разговор заново.
Часто первой теряется system-подсказка. Причина не только в лимите контекста. При переключении провайдера команда иногда передает только историю user и assistant, а system-сообщение не копирует, обрезает или склеивает с первой репликой. После этого меняется тон, формат ответа, правила безопасности и поведение на спорных запросах. Чат, который должен отвечать сухо и по шаблону, вдруг пишет свободным текстом и спорит с инструкцией.
Есть и более приземленная причина: провайдеры по-разному читают формат сообщений. Даже если у вас один OpenAI-совместимый endpoint, за ним могут стоять модели с разными ожиданиями к ролям, tool calls, JSON-ответам и порядку полей. Если слой маршрутизации не нормализует запрос, новая модель получает уже не тот разговор, который видела старая.
Обычно ломаются одни и те же вещи:
- исчезает
system-сообщение или его часть - меняются роли сообщений и порядок блоков
- пропадают
tool results,function calls,session_id, язык или режим вывода - новая модель получает слишком длинную историю и отбрасывает начало
Служебные поля влияют сильнее, чем кажется. Если вы не передали locale, policy tags, флаг JSON mode, имя сценария или метку пользователя, ответ меняется даже при той же истории диалога. В системах с требованиями к обработке данных это особенно заметно: маскирование PII, audit trail и похожие поля нельзя считать второстепенными. Они меняют и поведение модели, и сам маршрут запроса.
Поэтому при смене модели нужно переносить не только текст переписки. Нужен весь контракт диалога: инструкции, краткое резюме, формат ответа и служебные метки. Иначе fallback чинит доступность, но ломает сам разговор.
Что хранить в состоянии диалога
Если вы храните только последние реплики, fallback почти всегда теряет смысл разговора. Одна модель помнит детали из длинного окна, другая обрезает старые сообщения, и пользователь получает ответ вроде "уточните вопрос", хотя уже все объяснил.
Рабочее состояние диалога лучше держать в нескольких слоях. Один слой почти никогда не хватает. Сырые сообщения нужны для точной передачи смысла. Резюме помогает экономить токены. Отдельные поля нужны, чтобы новая модель не угадывала правила разговора заново.
Минимальный набор такой:
- полная история сообщений с ролями
system,user,assistant,tool - короткое резюме беседы с решениями, ограничениями и открытыми вопросами
- отдельные факты о пользователе и сессии: продукт, тариф, номер заявки, регион, уже пройденные шаги
- настройки диалога: язык, тон, формат ответа, запреты, лимиты и правила по данным
- технические идентификаторы вроде
session_idиmessage_id
Если смешать все это в одном поле prompt, потом трудно понять, что можно сжимать, а что трогать нельзя. При смене модели такая путаница обычно и ломает разговор.
У этих слоев разный срок жизни. История чата быстро растет и регулярно обрезается. Факты о пользователе могут жить неделями. Ограничение вроде "отвечай по-русски и не выводи персональные данные" должно пережить хоть пять переключений подряд.
Резюме не заменяет историю. Оно страхует разговор, когда вы уходите на более дешевую модель, на модель с меньшим окном контекста или на резервного провайдера. Если у вас один OpenAI-совместимый шлюз для нескольких маршрутов, например RU LLM, такую схему проще держать одинаковой: меняется модель, а контейнер состояния остается тем же.
Небольшой пример. Пользователь трижды уточнил условия доставки, потом прислал номер заказа, потом попросил ответить в двух пунктах. Если в состоянии лежит только последний вопрос, новая модель пропустит половину смысла. Если у вас есть история, короткое резюме, факт order_id и поле response_format = bullet_list_2, диалог продолжится без заметного сбоя.
Как разделить историю, резюме и служебные поля
Если хранить все в одном messages, разговор рано или поздно сломается. Новая модель увидит системную логику вперемешку с репликами пользователя и начнет путать факты, инструкции и внутренние флаги.
Состояние чата лучше разделять на несколько слоев. Тогда fallback меняет только исполнителя запроса, а не смысл диалога.
Простой каркас состояния
Удобно держать данные в такой форме:
{
"schema_version": 3,
"messages": [...],
"summary": "...",
"request_meta": {
"locale": "ru",
"safety_mode": "strict",
"channel": "support"
},
"fact_sources": [...]
}
messages - это только история диалога: кто что сказал, в каком порядке, с какими вложениями или результатами инструментов. Не добавляйте сюда флаги вроде fallback_used=true, лимиты токенов или внутренние пометки маршрутизации. Модель легко примет их за часть разговора.
summary храните отдельно. Это не замена истории, а короткая рабочая память поверх нее. В резюме стоит держать только то, что должно пережить длинный диалог: цель пользователя, уже принятые решения, ограничения и открытые вопросы. Если положить резюме прямо в историю как обычное сообщение, одна модель воспримет его как инструкцию, а другая как пересказ. Ответы начнут расходиться.
Служебные поля передавайте рядом с запросом, а не зашивайте в текст промпта без нужды. Язык ответа, режим модерации, тарифный план клиента, номер сценария поддержки и факт переключения на запасную модель должны жить в request_meta. Так вы меняете поведение системы без риска испортить сам диалог.
Источник каждого важного факта тоже лучше помечать отдельно. Утверждение пользователя, системное правило и результат вызова инструмента имеют разный вес. Если клиент сказал: "Мне нужен счет в рублях", а CRM вернула старый долларовый тариф, система должна видеть два разных источника, а не один общий факт.
Перед сменой модели версионируйте схему полей. Мера скучная, но рабочая. Одна модель нормально понимает tool_result, другая ждет tool_output. Если у состояния есть schema_version, вы сможете привести данные к нужному виду до отправки. В маршрутизации через единый API, в том числе через RU LLM, это особенно полезно: модели можно менять быстро, а формат состояния остается предсказуемым.
Как настроить fallback по шагам
Чтобы разговор не развалился после ошибки модели, собирайте запрос заново из состояния диалога, а не из памяти приложения "как получилось". Для переключения модели нужен один и тот же порядок сборки на каждом ходе.
Обычно хватает такой последовательности:
- Возьмите последние сообщения в рабочее окно. Это короткий хвост диалога, который модели нужен для живого ответа: недавние вопросы пользователя, уточнения и ответы ассистента.
- Перед этим хвостом подставьте резюме диалога. Оно передает факты, цели, ограничения и уже принятые решения, если полная история не помещается.
- Добавьте служебные поля отдельно и явно. Не прячьте их в текст сообщения. Лучше хранить
dialog_id,user_id, язык ответа, выбранные инструменты, флаги политики, состояние формы и метки аудита в своей схеме. - До отправки посчитайте токены. Если лимит близко, сначала ужимайте историю, а не режьте служебные поля и не выбрасывайте системные инструкции.
- Если модель вернула ошибку, таймаут или плохой формат, включайте fallback без смены структуры данных. Та же схема сообщений, то же резюме, те же поля.
На практике сбой чаще всего случается на пятом шаге. Команда меняет не только модель, но и способ упаковки контекста. Тогда вторая модель видит уже другой разговор. Пользователь этого не знает, но сразу замечает, что ассистент "забыл" имя клиента, цель задачи или запрет на определенный ответ.
После успешного ответа сразу сохраняйте новый снимок состояния. Обычно в него входят обновленный хвост истории, новое резюме, если смысл разговора изменился, и служебные поля после вызовов инструментов или проверки правил.
Если вы работаете через единый OpenAI-совместимый шлюз, такой подход особенно удобен. Можно переключать провайдера или модель, не переписывая клиентский код и формат чата. В RU LLM это выглядит именно так: команда меняет base_url на api.rullm.com и продолжает использовать те же SDK, код и промпты. Но даже при такой схеме целостность состояния диалога остается вашей задачей.
Как обновлять резюме без вреда
Резюме помогает при fallback, но только если вы обновляете его в правильный момент. Делайте это после завершенного ответа, когда у вас есть финальная версия реплики ассистента и понятный итог шага. Во время стрима резюме лучше не трогать: в середине ответа модель часто меняет формулировку, а иногда и сам вывод.
Если ответ оборвался, пользователь отменил запрос или инструмент вернул ошибку, не тащите этот черновик в память диалога. Иначе следующая модель получит как факт то, чего на самом деле не произошло.
Что писать в резюме
В резюме должны жить только подтвержденные вещи:
- факты, которые сообщил пользователь
- решения, которые принял пользователь или система
- ограничения и предпочтения, которые уже проверили
- незакрытые задачи с понятным статусом
- последняя актуальная договоренность
Догадки модели туда не попадают. Если ассистент предположил город пользователя, тип тарифа или причину ошибки, это еще не факт. Пока пользователь не подтвердил это явно или данные не пришли из доверенного источника, такие вещи лучше оставить в текущем сообщении, а не в резюме.
Есть простое правило: резюме должно пережить смену модели без искажений. Если новая модель прочитает только его, она не должна продолжить разговор в неверную сторону.
Повторы режьте сразу. Если пользователь три раза написал, что ему нужен счет в рублях, в резюме это остается один раз. Старые детали тоже убирайте, когда они потеряли смысл. Если в начале диалога пользователь просил выгрузку в PDF, а потом согласился на CSV, храните только новый выбор. История может помнить оба шага, резюме - нет.
Хорошо работает схема из двух версий. Короткая версия нужна для каждого запроса: 3-6 строк с текущим состоянием разговора. Полная версия нужна для восстановления контекста, аудита и сложных переключений, когда надо понять, как команда пришла к текущему решению.
На практике это выглядит так: короткое резюме отправляете вместе с последними сообщениями, а полное храните отдельно и обновляете реже. Это снижает шум в промпте и не стирает важные детали.
Относитесь к резюме как к журналу фактов, а не как к пересказу всего чата. Короткий, сухой и точный текст почти всегда работает лучше длинного и "умного" абзаца.
Пример с чатом поддержки
Пользователь пишет: "Хочу вернуть заказ 48371. Куртка пришла вовремя, но размер не подошел". Для оператора это обычный диалог. Для системы это место, где легко потерять контекст, если первая модель зависнет или ответит слишком поздно.
Сервис хранит состояние чата не одним длинным текстом, а тремя слоями: историю диалога, короткое резюме и служебные поля. В истории лежат последние реплики без сокращений. В резюме - уже подтвержденные факты. В служебных полях - order_id, канал, язык, версия правил возврата, intent и другие метки.
В резюме уже есть суть: заказ 48371, товар - куртка, причина возврата - не подошел размер, клиент просит порядок действий. В служебных полях лежит и правило магазина: возврат возможен в течение 14 дней, если товар без следов носки и сохранены ярлыки. Эти данные не нужно заново вытаскивать из всей переписки.
Первая модель начинает отвечать, но уходит в timeout. Частая ошибка в такой точке - отправить fallback-модели только последний вопрос пользователя. Тогда вторая модель видит фразу про возврат, но не знает номер заказа, не помнит, что товар уже назвали, и может спросить то, что клиент уже написал.
Нормальный fallback делает иначе. Сервис берет ту же историю, то же резюме и те же служебные поля, а затем отправляет их второй модели. Если у обеих моделей один шаблон system prompt и одинаковые правила тона, ответ выглядит цельно: "По заказу 48371 можно оформить возврат. Если куртку не носили и ярлыки на месте, я подскажу следующий шаг".
Пользователь не видит, что модель сменилась. Он не повторяет номер заказа. Ему не задают второй раз тот же вопрос. Диалог не распадается на два разных разговора.
Если routing идет через единый OpenAI-совместимый шлюз, такой сценарий проще держать в коде. Приложение отправляет один и тот же пакет данных, а меняется только целевая модель или провайдер.
Ошибки, которые ломают контекст
Большинство сбоев появляется не в момент смены модели, а раньше - на этапе хранения состояния и сборки запроса.
Первая частая ошибка - отправлять в запрос весь диалог без отбора. Сначала все работает, потом история упирается в лимит контекста. Дальше система тихо обрезает ранние сообщения, и вместе с ними исчезают ограничения, договоренности и детали задачи. Пользователь видит это как "модель вдруг забыла, о чем мы говорили".
Обратная крайность тоже вредна: нужные правила лежат только в старых репликах. Если вы один раз задали формат ответа, стиль, запреты или бизнес-правило в начале чата, а потом перестали добавлять это в каждый запрос, fallback легко потеряет эти условия. Долгоживущие инструкции лучше хранить отдельно от обычной истории.
С резюме часто ошибаются еще грубее. Его пишут общими фразами вроде "пользователь обсуждает интеграцию" или "нужна помощь с документами". Такое резюме почти бесполезно. Нормальное резюме хранит факты: что уже решили, что отклонили, какие поля заполнили, какой вопрос остался открытым и на чем настаивает пользователь.
Еще одна поломка начинается, когда внутренние теги смешивают с текстом для модели. Причина переключения, служебные пометки маршрутизации, флаги модерации, AI-Law метки и debug-поля не должны попадать в тот же текстовый блок, где идет разговор с пользователем. Иначе модель начинает повторять служебные слова или делает странные выводы из технических меток.
Отдельный источник сбоев - смена формата ролей при переходе между API. Где-то system, developer и tool идут отдельными сообщениями, а где-то их превращают в обычный текст. Если вы меняете только base_url на OpenAI-совместимый шлюз, это еще не значит, что сериализация точно совпадет. Проверьте, что роли, tool calls и имена полей остаются теми же.
И еще один момент, который часто забывают: сохраняйте причину fallback. Иначе после сбоя вы не поймете, что случилось - таймаут, 429, лимит бюджета, ошибка провайдера или неверный роутинг. Если в состоянии чата есть причина переключения, исходная модель и момент смены, такие проблемы ищутся намного быстрее.
Проверки перед запуском
Для переключения модели без потери контекста важнее не сама модель, а дисциплина в состоянии диалога. Разговор обычно ломается из-за мелочей: потерянного идентификатора, слишком длинного резюме или фактов пользователя, спрятанных в обычной переписке.
Перед запуском проверьте несколько вещей:
- у каждого диалога должен быть стабильный
session_id, а у каждого сообщения свойmessage_id - резюме должно входить в жесткий лимит токенов вместе с системными инструкциями, последними репликами и служебными полями
- факты о пользователе лучше хранить отдельно от свободного текста
- при смене модели роли и имена полей не должны меняться
- логи должны записывать причину fallback и выбранную модель
Один тест быстро показывает, готова ли система к реальной нагрузке. Возьмите длинный чат поддержки, где пользователь уже назвал имя, номер заказа и попросил писать только в чате. Потом принудительно переключите модель в середине диалога. Если новая модель не переспрашивает то, что уже известно, и не теряет ограничения, состояние собрано нормально.
Отдельно проверьте старые записи в хранилище. Команды часто обновляют схему в коде, но забывают, что вчерашние сессии живут по прежним правилам. Без версии схемы такие случаи всплывают уже после релиза.
Если вы используете шлюз вроде RU LLM, маршрутизация между провайдерами действительно становится проще. Но целостность истории, резюме и служебных полей все равно остается на стороне приложения.
Что сделать дальше в продакшене
Самый практичный следующий шаг - ввести один контракт состояния для всех моделей и провайдеров. Если одна модель читает только историю сообщений, другая ждет отдельное резюме, а третья опирается на служебные флаги, fallback быстро превращается в набор частных костылей.
В этом контракте обычно хватает трех слоев: полной или сокращенной истории диалога, текущего резюме и служебных полей. К служебным полям относят язык, идентификатор сессии, версию резюме, причину fallback, результаты tool calls, флаги безопасности и маскированный идентификатор пользователя. Модель можно менять, но схема состояния должна оставаться одной и той же.
После этого стоит прогнать сценарии, которые чаще всего ломаются под нагрузкой:
timeout: новая модель должна получить тот же state и тот жеturn_id, без потери последней репликиrate limit: повтор не должен второй раз дергать внешний инструмент или повторно списывать действие- пустой ответ: оркестратор должен пометить причину, запустить
retryили fallback и сохранить след в логах - обрыв резюме: если
summaryне обновилось, чат не должен терять факты из последних сообщений - смена провайдера: формат ролей,
tool callsиmetadataдолжен остаться единым
Потом сравните ответы после fallback на реальных диалогах, а не на коротких примерах. Возьмите выборку из поддержки, онбординга и сложных многошаговых чатов. Смотрите не только на качество текста. Часто проблема в другом: новая модель забывает обещанный срок, теряет статус заявки, меняет тон или повторно задает уже закрытый вопрос.
Логи тоже нужны не для галочки. Записывайте, какая модель ответила, почему случился fallback, какое резюме использовалось, какие поля были замаскированы и какие данные ушли в tool call. Для команд в РФ это особенно полезно: аудит и маскирование персональных данных лучше встраивать в каждый запрос, а не пытаться добавить потом.
Если вам нужен один OpenAI-совместимый endpoint в российском контуре, RU LLM на rullm.com позволяет переключать модели и провайдеров через api.rullm.com, не меняя SDK, код и промпты. Это упрощает интеграцию, но не отменяет базовое правило: разговор остается цельным только тогда, когда история, резюме и служебные поля собраны одинаково на каждом ходе.
Часто задаваемые вопросы
Почему fallback заставляет модель забывать начало разговора?
Потому что при переключении часто меняют не только модель, но и сам пакет данных. Новая модель получает другой набор сообщений, теряет system-инструкции, не видит tool-результаты или читает уже обрезанную историю.
Что нужно хранить кроме последних сообщений?
Храните не только последние реплики. Нужны полная история с ролями, короткое резюме с подтвержденными фактами, настройки диалога вроде языка и формата ответа, а также служебные поля вроде session_id и данных после tool calls.
Нужно ли каждый раз отправлять system-сообщение?
Да, передавайте его на каждом ходе. Если вы один раз задали тон, формат ответа или запрет на вывод персональных данных, не надейтесь, что новая модель сама это восстановит по старым репликам.
Чем резюме отличается от истории чата?
История хранит сами реплики и порядок разговора. Резюме держит только то, что должно пережить длинный чат: цель пользователя, принятые решения, ограничения и открытые вопросы.
Когда лучше обновлять резюме диалога?
Обновляйте резюме после завершенного ответа, когда смысл шага уже ясен. Во время стрима и после оборванного ответа лучше ничего не записывать, иначе вы занесете в память черновик вместо факта.
Что не стоит писать в summary?
Не заносите догадки модели, спорные выводы и временные формулировки. В резюме оставляйте только подтвержденные факты от пользователя, системы или доверенного инструмента.
Куда класть locale, session_id и другие служебные поля?
Держите их отдельно от текста диалога, например в request_meta. Так вы сможете менять язык, режим JSON, теги политики и метки аудита без риска сломать сам разговор.
Как не сломать tool calls при смене провайдера?
Сначала приведите роли и названия полей к одной схеме. Если одна модель ждет tool_output, а другая читает tool_result, ваш роутер должен переименовать поле до отправки, а не надеяться на удачу.
Как проверить, что переключение модели работает без потери контекста?
Возьмите длинный диалог, где пользователь уже дал имя, номер заказа и ограничения, а потом принудительно переключите модель в середине чата. Если новая модель не переспрашивает известное и не меняет формат ответа, схема состояния собрана нормально.
Что делать, если новая модель снова спрашивает то, что пользователь уже сообщил?
Если это случилось, значит вы потеряли факт между ходами. Сохраните этот факт отдельно, пересоберите запрос из истории, резюме и метаданных, а затем проверьте логи: часто проблема в обрезанном system-сообщении или пропавшем поле после fallback.