Единая схема ошибок LLM API для разных провайдеров
Единая схема ошибок LLM API помогает свести timeout, rate limit, policy block и битый ответ к ясным кодам, ретраям и понятным сообщениям.
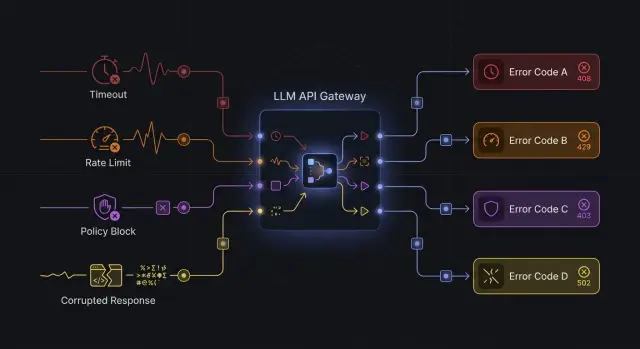
Почему ошибки у провайдеров не совпадают
Один и тот же сбой разные LLM API описывают по-разному. Один провайдер вернет 429 и честно скажет, что вы уперлись в лимит. Другой в похожей ситуации отдаст 503, потому что у него лимит завязан на перегрузку пула. Третий вообще вернет 200, а внутри положит текст ошибки или пустой ответ, который клиент попытается разобрать как нормальный JSON.
Один сбой, три разных ответа
Представьте обычный запрос на генерацию. У провайдера A модель занята, и вы получаете 429 с полем rate_limit_exceeded. У провайдера B та же модель под той же нагрузкой отвечает 503 с сообщением вроде "upstream unavailable". У провайдера C HTTP-статус равен 200, но в теле лежит {"error":"model overloaded"} или обрезанный кусок JSON.
Для клиента это три разные ветки кода, хотя смысл один: запрос сейчас не обработали, позже можно повторить. Если приложение смотрит только на HTTP-статус, оно начинает вести себя странно. На 429 включает retry, на 503 показывает пользователю "сервис упал", а ответ с 200 принимает за успех и падает уже на разборе результата.
Так же ломаются fallback и метрики. Команда думает, что видит два типа проблем: лимиты и падения сервиса. На деле это один класс временных отказов, просто каждый провайдер назвал его по-своему.
Почему текст ошибки не может быть контрактом
Текст ошибки пишут для человека, а не для кода. Сегодня там будет "quota exceeded", завтра "too many requests", послезавтра - локализованная строка или новый формат поля. Стоит привязать логику к тексту, и клиент начнет вести себя непредсказуемо после любого мелкого изменения.
Проще разделить ошибки на четыре слоя:
- сеть: DNS, TLS, timeout, разрыв соединения
- ваш шлюз: auth, валидация, внутренний timeout, ошибки маршрутизации
- провайдер: rate limit, недоступность, битый JSON, пустой stream
- сама модель: policy block, refusal, превышение контекста
Это сразу убирает путаницу. Timeout сети и policy block нельзя обрабатывать одинаково. В первом случае клиенту нужен retry или fallback. Во втором нужен понятный код отказа без повторов запроса. Когда вы сводите такие случаи к одной схеме, OpenAI-совместимый API перестает зависеть от чужих формулировок и начинает вести себя предсказуемо.
Какие коды нужны клиенту
Клиентскому коду не нужен весь зоопарк ошибок от провайдеров. Ему нужен короткий и стабильный набор кодов, по которым сразу понятно, что делать: повторять запрос, показать сообщение пользователю или поднять алерт.
Для шлюза это особенно важно. Один запрос может уйти к разным моделям и провайдерам, но SDK, ретраи и мониторинг должны видеть один и тот же контракт. Если сегодня провайдер вернул 429, а завтра текстовую ошибку с тем же смыслом, клиентская логика не должна меняться.
Обычно хватает 6-10 кодов. Меньше - вы смешаете разные причины в одну кучу. Больше - клиент начнет разбирать детали апстрима, а это уже не его работа.
Базовый набор можно держать таким:
upstream_timeout- провайдер не ответил вовремя, запрос можно повторитьrate_limited- лимит на стороне провайдера или шлюза, нужен retry с паузойprovider_unavailable- провайдер недоступен, часто нужен fallback на другую модельpolicy_blocked- запрос или ответ заблокировала политика, пользователю можно показать понятное сообщение
Эти коды покрывают большую часть сбоев в проде. Они простые, читаются без документации и хорошо ложатся на алерты.
Еще несколько кодов полезны для случаев, где повтор бесполезен или вреден:
invalid_request- клиент отправил плохие параметры, retry не поможетauthentication_failed- неверный ключ или права доступаinvalid_upstream_response- провайдер прислал битый JSON, пустой stream или сломанный форматunknown- редкий или новый случай, который вы еще не разложили по полкам
unknown нужен почти всегда. Без него команда рано или поздно сломает контракт: появится новый тип сбоя, и кто-то добавит внезапный код, который старые клиенты не знают. Лучше временно отдать unknown, залогировать детали и спокойно расширить маппинг позже.
Полезно сразу разделить коды по действию. upstream_timeout, rate_limited и часть provider_unavailable идут в retry-логику. policy_blocked, invalid_request и authentication_failed идут в понятные сообщения и поддержку. invalid_upstream_response и unknown почти всегда должны попадать в алерты, потому что тут уже есть риск тихой поломки интеграции.
Если после чтения кода разработчик за пару секунд понимает, что делать дальше, схема получилась удачной.
Как собрать схему по шагам
Когда шлюз отправляет один и тот же запрос к разным провайдерам, хаос начинается не на уровне моделей, а на уровне ошибок. Один источник вернет 429 с понятным телом, другой ответит 503 без деталей, третий оборвет поток на середине JSON. Если у клиента на каждый случай свой разбор, код быстро расползется.
В OpenAI-совместимом слое схему лучше строить вокруг причины сбоя, а не вокруг формулировок конкретного провайдера. Тогда клиент меняет только точку входа, но не переписывает обработку ошибок под каждый новый апстрим.
Рабочий порядок
- Сначала соберите сырой набор ошибок. Нужны реальные HTTP status, тело ответа, transport error, время ожидания, request id провайдера и факт, пришел ли ответ целиком. Без этой выборки схема обычно выглядит красиво только на бумаге.
- Потом разложите случаи по причине. Сообщения вроде "too many requests", "rate limit exceeded" и "quota reached" могут относиться к разным лимитам, но для клиента это один класс: запрос сейчас не пройдет. То же самое с timeout, policy block и битым ответом.
- Для каждой причины назначьте один client code и один HTTP-статус. Если сегодня timeout у вас 504, а завтра 502, клиенту придется гадать. Стабильность здесь важнее тонких различий между провайдерами.
- Добавьте служебные поля для поведения клиента. Минимум такой:
retryable,retry_after_msиprovider_code. Тогда SDK сможет сам понять, надо ли повторить запрос, ждать ли две секунды или сразу идти в fallback. - Зафиксируйте все это в тестах и SDK. Берите сохраненные ответы провайдеров, прогоняйте их через нормализатор и проверяйте, что результат не меняется после новых релизов.
На практике часто хватает такой базы: upstream_timeout -> 504, rate_limited -> 429, policy_blocked -> 403, invalid_upstream_response -> 502. Уже этого достаточно, чтобы клиент принимал предсказуемые решения.
Проверка простая: инженер смотрит на код ошибки и сразу понимает действие. Повторить запрос, подождать, переключить модель или показать пользователю понятное сообщение. Если для этого нужно читать сырой текст провайдера, схема еще не готова.
Для шлюза вроде RU LLM это особенно заметно. За одним контрактом могут стоять внешние провайдеры и собственные модели, размещенные в российских ЦОДах, но клиенту все равно нужен один и тот же формат ошибок.
Как маппить частые сбои
У разных провайдеров одна и та же проблема выглядит по-разному: где-то приходит 429, где-то соединение рвется без тела ответа, а где-то stream просто зависает. Клиенту не нужно разбирать этот набор частных случаев. Ему нужна стабильная схема, где один тип сбоя всегда означает одно действие.
Практичное правило такое: маппить нужно не тексты от провайдера, а класс проблемы.
- Если апстрим не уложился в ваш таймаут, завис в stream или оборвал ответ слишком поздно, верните
upstream_timeout. Обычно рядом ставят HTTP 504. - Если провайдер уперся в лимит запросов, токенов или параллельных сессий, сводите это к
rate_limited. Полеretry_afterлучше отдавать в секундах. Даже грубая оценка полезнее, чем пустой 429 без подсказки. - Если модель или провайдер заблокировали запрос по safety, moderation или внутренней policy, код должен быть
policy_blocked. Сырой текст провайдера наружу лучше не отдавать: он шумный, иногда раскрывает лишние детали и ломает единый контракт. - Если апстрим прислал битый JSON, пустой body, обрезанный chunk или ответ не совпал с ожидаемой схемой, верните
invalid_upstream_response. Это не ошибка клиента и не обычный таймаут. - Все, что не вошло в эти группы, складывайте в
unknownилиprovider_unavailable, в зависимости от вашей схемы. Но детали не теряйте: в логах сохраняйте исходный статус, код провайдера,request_id, модель и транспортную причину.
Есть простой тест. Один и тот же клиентский код должен одинаково отработать, если один провайдер вернул 429, второй закрыл соединение на 20-й секунде, а третий прислал пустое тело. Для клиента это три понятные ветки, а не три отдельные интеграции.
Что положить в тело ошибки
Клиенту нужен не сырой ответ провайдера, а короткий и понятный объект, по которому код сразу решает: повторять запрос, переключать модель или показать сообщение пользователю.
Минимальный набор полей небольшой:
code- стабильный машинный код, напримерrate_limited,upstream_timeout,policy_blocked,invalid_upstream_responsemessage- короткий текст для лога и интерфейса без деталей внутренней кухниrequest_id- идентификатор запроса, по которому команда найдет след в логах и аудит-трейлеproviderиupstream_status- чтобы быстро понять, где сломалось: у маршрутизатора, у провайдера или на моделиretryable- явный флагtrueилиfalse, чтобы клиент не гадал
Этого хватает для большей части клиентской логики. Если API отдал retryable: true, приложение может сделать повтор или уйти на fallback. Если false, оно сразу покажет ошибку и не сожжет лимиты пустыми ретраями.
Поле retry_after добавляйте только тогда, когда верхний слой правда знает паузу. Чаще всего это rate limit или временная блокировка на стороне провайдера. Если точного значения нет, лучше не придумывать. Ложный таймер хуже пустого поля: клиент замрет на 30 секунд там, где можно было повторить через 2.
Для разбора инцидента полезно видеть и провайдера, и его статус. Например, provider: "anthropic" и upstream_status: 429 сразу объясняют, почему маршрутизатор вернул общий rate_limited.
При этом тело ошибки не должно тянуть за собой PII, сырые промпты, токены и куски внутренней трассировки. Достаточно безопасного текста и идентификаторов. Если вы работаете в контексте 152-ФЗ, это уже не мелочь, а базовая гигиена. В RU LLM такой подход особенно уместен: у платформы есть маскирование PII и аудит-трейлы на уровне запросов, поэтому ошибки тоже стоит держать короткими и безопасными.
{
"error": {
"code": "rate_limit",
"message": "Provider rate limit exceeded",
"request_id": "req_8f23ab",
"provider": "openai",
"upstream_status": 429,
"retryable": true,
"retry_after": 15
}
}
Такой формат читает и человек, и код. А ночью на дежурстве это экономит не пять минут, а целый час.
Пример на одном запросе
Представьте чат-бот магазина. После разговора с покупателем он просит модель сделать короткую сводку: что человек искал, какие возражения были и нужен ли менеджер. Для бизнеса это обычная операция, но без нормализации ошибок один и тот же запрос может ломаться по-разному у разных провайдеров.
Сценарий может выглядеть так:
- приложение отправляет
chat.completionsна суммаризацию диалога - первый провайдер отвечает HTTP 429
- шлюз не отдает сырой ответ провайдера, а возвращает клиенту понятный код
rate_limited - клиент видит
retryable: true, ждет по своей политике и пробует снова - вторая попытка уходит к другому провайдеру, но тот не отвечает 30 секунд, и шлюз отдает
upstream_timeout
Для клиента оба сбоя выглядят одинаково по форме, хотя причина разная. В этом и смысл нормализации: приложение не разбирает десятки форматов, а смотрит на два поля - code и retryable.
Например, тело ошибки может быть таким:
{
"error": {
"code": "rate_limited",
"message": "Upstream provider rejected the request due to rate limit",
"retryable": true,
"provider": "provider_a",
"upstream_status": 429,
"request_id": "req_7f29"
}
}
А на второй попытке так:
{
"error": {
"code": "upstream_timeout",
"message": "Upstream provider did not respond in time",
"retryable": true,
"provider": "provider_b",
"timeout_ms": 30000,
"request_id": "req_7f29"
}
}
Заметьте, request_id один и тот же. Оператор открывает логи и сразу видит цепочку событий по одной сессии. Ему не нужно вспоминать, как именно каждый провайдер называет timeout или лимит.
Клиентская логика тоже становится проще. Она не делает retry для всего подряд. Если шлюз вернул retryable: true, приложение пробует снова или переводит запрос на fallback-модель. Если retryable: false, например при policy_blocked, клиент сразу показывает штатную ошибку и не тратит лишние попытки.
Где команды чаще ошибаются
Самая частая ошибка простая: команда строит общую схему как красивую обертку над чужими ответами. Клиенту нужна не чужая формулировка, а стабильный контракт. Если сегодня один провайдер пишет rate limit exceeded, завтра другой вернет длинный HTML или текст на другом языке, и SDK начнет вести себя по-разному на одном и том же сбое.
Не копируйте текст апстрима прямо в ответ клиенту. В таком тексте часто есть лишние детали: внутренние названия провайдера, нестабильные формулировки, иногда даже куски policy-сообщений, которые потом внезапно меняются. Лучше оставить у себя сырой ответ для логов и аудита, а клиенту отдать свой code, короткий message и поля вроде retry_after или upstream_status.
Другая частая путаница - смешивать ошибки клиента со сбоями апстрима. Если пользователь отправил битый JSON, выбрал несуществующую модель или передал неверный параметр, это его ошибка, а не проблема провайдера. Если провайдер завис, оборвал stream или вернул мусор вместо JSON, это уже сбой выше по цепочке. Когда оба случая получают один и тот же код, клиент не понимает, что делать: чинить запрос или повторять его.
Обычно команды спотыкаются в четырех местах:
- отдают 500 там, где нужен 429, и прячут
retry_after - меняют
codeчерез месяц после релиза, потому что новая формулировка кажется понятнее - не держат отдельный код для
policy_blocked - не тестируют обрезанный stream и битый JSON от провайдера
Смена кода задним числом бьет больнее, чем кажется. Мобильное приложение, бэкенд и очередь ретраев уже завязаны на старое значение. Если раньше upstream_timeout означал повтор, а потом вы заменили его на provider_unavailable, часть клиентов перестанет ретраить, а часть начнет делать это бесконечно.
С rate limit ошибаются особенно часто. Для OpenAI-совместимого API ответ 429 должен оставаться 429, даже если конкретный провайдер прислал странный текст или нестандартное тело. Иначе клиент видит 500, считает это аварией сервера и запускает неверный fallback.
С битыми ответами история еще хуже. Команды проверяют только счастливый путь: валидный JSON, аккуратный stream, полный finish_reason. В проде провайдер может вернуть половину объекта, пустую строку или оборванный SSE-поток. На такие случаи нужен отдельный код сбоя апстрима, иначе поиск причины растягивается на часы.
Быстрая проверка перед релизом
Перед релизом схема ошибок должна пройти короткую, но жесткую проверку. Если клиент видит понятный код, но не знает, что делать дальше, схема еще сырая.
У каждого нормализованного кода должно быть ровно одно действие на стороне клиента. upstream_timeout повторяем с backoff, rate_limited замедляем или уходим на запасную модель, policy_blocked не ретраим и сразу показываем причину, invalid_upstream_response переводим на fallback или в алерт. Когда один код ведет к двум разным сценариям, SDK быстро обрастает костылями.
Свободный текст нужен человеку, не программе. SDK должен опираться на error.code, HTTP-статус и флаг retryable, а не искать в сообщении слова quota, timeout или blocked. Иначе первый же провайдер поменяет формулировку, и клиент начнет ошибаться там, где логика раньше работала.
Перед выкладкой проверьте пять вещей:
- Каждый код маппится на одно действие клиента, и это действие одинаково описано в SDK и документации.
- Логи связывают
client_request_idсupstream_request_id, именем провайдера и модели. Без этого разбор инцидента превращается в гадание. - Мониторинг считает
rate_limitedиupstream_timeoutотдельно. Если сложить их в одну метрику "ошибки провайдера", вы не поймете, где уперлись в лимиты, а где виноваты сеть или очередь. - Контрактные тесты искусственно вызывают четыре частых сбоя: timeout, 429,
policy_blockedи битый ответ от upstream. На выходе клиент всегда получает один и тот же формат тела ошибки. - Тесты проверяют, что текст ошибки может меняться без поломки SDK. Это хороший способ поймать скрытый парсинг сообщений.
Если вы работаете через один шлюз и меняете только точку входа, клиентский контракт должен оставаться стабильным. Пользователь не должен знать, какой именно upstream ответил криво или вернул свой особый 429. Эту разницу должен поглотить шлюз.
Что сделать дальше
Начните с малого. Для старта схема не должна быть большой. Чаще всего хватает четырех кодов: upstream_timeout, rate_limited, policy_blocked и invalid_upstream_response. Этого уже достаточно, чтобы клиент понял, надо ли повторить запрос, переключить модель или сразу вернуть понятную ошибку пользователю.
Не расширяйте схему заранее. Сначала соберите журналы за несколько дней, посмотрите реальные сбои и только потом добавляйте новые коды. Если новый код не меняет поведение клиента, он почти всегда лишний.
Нормализацию лучше держать в шлюзе, а не размазывать по сервисам. Когда каждый сервис сам трактует 429, 408 или битый ответ провайдера, команда быстро получает разный retry и разный fallback для одного и того же случая. Один слой маппинга решает это проще: вы один раз приводите ошибки к общему виду и отдаете всем клиентам одинаковый формат.
Отдельно проверьте, как схема живет в OpenAI-совместимом API. Тест должен быть скучным и строгим: смените только точку входа, отправьте один и тот же запрос через двух провайдеров и сравните статус, error.code, текст для клиента, request_id и признак того, можно ли повторить запрос. Если клиентский код ведет себя одинаково, вы на верном пути.
Если вы используете RU LLM, такой слой удобно зафиксировать один раз в шлюзе и не трогать клиентские SDK, код и промпты. Это особенно полезно для команд, которые уже работают с OpenAI-совместимыми библиотеками и не хотят заново учить каждое приложение особенностям десятков провайдеров.
Перед продом проверьте еще несколько вещей:
- логи сохраняют исходную причину сбоя и ваш внутренний код маппинга
- маскирование PII работает и в ошибках, а не только в успешных ответах
- аудитный след связывает запрос клиента, ответ шлюза и ответ провайдера
- мониторинг отдельно считает timeout, rate limit, policy block и битые ответы
Если через неделю трафика почти все ошибки укладываются в эти четыре кода, схема уже приносит пользу. Если нет, добавляйте новый код только там, где клиенту правда нужно другое действие.