Доступ модели к внутренним API: чек-лист перед tool call
Доступ модели к внутренним API требует правил до первого tool call: scope, логи, лимиты, откат, проверка рисков и роли команд.
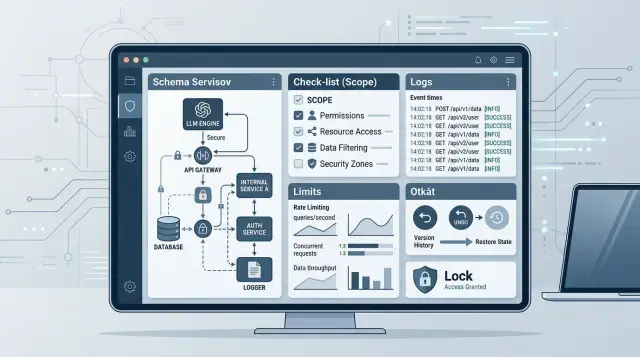
Почему вызов инструмента без правил быстро ломает процесс
Вызов инструмента выглядит как обычный запрос к функции, но по смыслу это уже право что-то сделать внутри вашего контура. Модель не знает границы бизнеса сама по себе. Она не понимает, когда можно менять адрес клиента, когда нужно второе согласование, а когда запрос надо остановить и передать человеку.
Поэтому доступ к внутренним API ломает процесс быстрее, чем кажется. Ошибка в промпте, неточный маппинг поля или лишнее разрешение в scope дают не "немного шума", а реальное действие: запись в CRM, смену статуса, отправку сообщения, списание бонусов. Человек замечает такую ошибку позже, чем API успевает выполнить запрос.
Обычно сбой выглядит просто. Модель получает слишком широкий инструмент, выбирает его по похожему описанию, отправляет неверный параметр или customer_id, а внутренняя система честно меняет данные. Если агенту нужен только просмотр заказа, а рядом лежат update_order или create_refund, модель будет считать их доступными вариантами. Она не читает ваш регламент между строк. Она видит список инструментов и текст рядом с ними.
Пример из поддержки показательный. Клиент спрашивает, где посылка. Боту достаточно прочитать статус доставки. Но если тот же инструмент умеет править карточку клиента, модель может записать новый телефон из сообщения без проверки, перепутать контакт и испортить CRM за секунды.
Отдельная проблема - полные логи. Если команда пишет в журнал весь запрос и весь ответ без маскирования, туда быстро попадают телефоны, адреса, номера договоров, токены и внутренние комментарии операторов. Для компаний с требованиями 152-ФЗ это уже не мелкий недочет, а прямой риск.
Еще один частый провал связан с порядком проверок. Модель делает действие раньше проверки, если вы явно не запретили такой путь. Она не различает "можно показать" и "можно изменить" так же надежно, как это делает человек. Если операция обратимая, ошибку еще можно откатить. Если нет, инцидент уже случился.
Поэтому правила для tool call пишут до запуска, а не после первого сбоя. Иначе даже аккуратный агент ведет себя как сотрудник с мастер-ключом и без журнала входа.
Как подготовить доступ
Начните не с сервисов, а с конкретных методов. Формулировка вроде "дать модели доступ к CRM" почти всегда слишком широкая. Нужен короткий список API, ручек и операций, с которыми модель правда будет работать в первой версии.
Напротив каждого метода запишите цель простым языком. Не "интеграция с заказами", а "показать статус заказа оператору" или "проверить, есть ли активный тариф". Если цель расплывчатая, доступ пока выдавать рано. Обычно это значит, что команда еще сама не решила, зачем ей этот вызов.
Сразу отсейте методы, которые выглядят похоже, но несут разный риск. Например, getOrderStatus часто нужен уже в первый день. А changeDeliveryAddress лучше не открывать, пока не появятся подтверждение действия, журнал и понятный откат. Один и тот же API нередко содержит и безопасные, и опасные вызовы. Их нельзя открывать пакетом.
Дальше назначьте двух ответственных. Владелец сервиса отвечает за сам метод: что он принимает, что возвращает, какие есть ограничения и где он ломается. Владелец риска отвечает за последствия ошибки: что случится, если модель вызовет метод не к тому клиенту, слишком часто или не в тот момент. Иногда это один человек, но роли все равно стоит назвать явно.
Потом выберите среду. Для первого запуска почти всегда хватает теста или стейджа с непустыми, но безопасными данными. Прод открывают только после проверки логов, лимитов и сценария отката. Если в тесте модель уже путает параметры или делает лишние вызовы, в проде будет только хуже.
И еще один вопрос, который часто спасает от лишней работы: нужен ли вызов инструмента вообще. Если данные меняются раз в сутки, иногда проще передавать модели готовую выгрузку или короткий контекст, чем давать живой доступ к внутреннему API. Tool call нужен там, где ответ быстро устаревает или где без реального действия модель бесполезна.
Признак нормальной подготовки простой: у каждого метода есть понятная цель, известен владелец, выбрана среда, и команда может объяснить, почему без этого вызова нельзя. Если одного пункта нет, доступ лучше не открывать.
Как сузить scope до нужного минимума
Scope должен описывать не все возможности API, а один конкретный рабочий путь. Чем уже границы, тем меньше шанс, что обычный запрос пользователя превратится в лишнее изменение в боевой системе.
Сначала разведите чтение, изменение и удаление по разным разрешениям. Запросить статус заказа и поменять адрес доставки - это разный уровень риска. Удаление лучше вообще выносить в отдельный инструмент или оставлять только человеку.
Потом урежьте поля и параметры. Если модели нужен номер заказа, статус и дата отгрузки, не отдавайте ей всю карточку клиента. На запись действует то же правило: разрешайте только те параметры, которые реально нужны, и запрещайте произвольные фильтры, raw query и служебные флаги.
Минимальный scope отвечает на четыре вопроса: что именно можно сделать, с какими объектами можно работать, какие поля доступны на чтение и изменение, и от чьего имени идет вызов. Последний пункт недооценивают чаще всего. Если оператор видит только свою очередь тикетов или один регион, модель должна жить в тех же рамках. Общий сервисный ключ, который видит все, ломает ролевые ограничения за один вызов.
От wildcard-токенов лучше отказаться сразу. Даже если вы переходите на единый шлюз и оставляете прежние SDK и код, scope не надо переносить как есть. Его стоит собрать заново, под реальный сценарий.
Еще один полезный слой защиты - ограничение по resource ID или сегменту. Если модель работает только с клиентами одного tenant, проекта или очереди, это должно быть записано в политике доступа, а не лежать в промпте. Промпт можно обойти, переписать или просто неверно понять. Проверка по ID и сегменту на стороне API надежнее.
Нормальный scope выглядит скучно, и это хороший знак. Если разрешение нельзя описать одним коротким абзацем, оно почти всегда шире, чем нужно.
Что писать в журналы, а что скрывать
Журнал нужен не для полной копии каждого запроса, а для ответа на три вопроса: кто вызвал инструмент, что система решила и чем это закончилось. Если в записи нет request_id, user_id, имени инструмента и результата, разбор инцидента быстро превращается в догадки.
Обычно хватает такой структуры: request_id и время вызова, user_id или внутренний идентификатор сессии, имя инструмента и версия схемы, решение allow или deny с короткой причиной, а также итог вызова - статус, код ошибки или идентификатор измененного объекта.
Причину deny лучше писать коротко и по делу. Например: "нет scope billing.write", "превышен лимит", "операция требует ручного подтверждения". Для allow тоже полезно оставить основание, если решение проходило через политику доступа или отдельный фильтр.
Скрывать стоит все, что не помогает расследовать сбой, но повышает риск утечки. В журналы не кладут токены, cookie, номера документов, полные телефоны, адреса, номера договоров и свободный текст пользователя без маскирования. Если запись нужна только для связи событий, хватит хеша, последних четырех цифр или внутреннего surrogate id.
Сырые payload лучше хранить отдельно и только там, где они правда нужны: для разбора инцидентов, споров по операциям или проверки политики безопасности. Даже в этих случаях полезно сократить срок хранения и сильно сузить доступ. Большинству команд хватает структурированного audit trail без полного тела запроса.
По 152-ФЗ заранее проверьте две вещи: сколько вы храните журналы и кто их читает. Срок хранения должен быть привязан к задаче, а не выбран по привычке. Доступ лучше давать по ролям: инженеру поддержки одно, службе безопасности другое, разработчику только обезличенные записи.
Проверка тут очень простая. Если модель вызвала API возврата заказа, вы должны увидеть request_id, user_id, имя инструмента, решение allow, причину и id заказа. Но вы не должны увидеть полный номер карты, паспортные данные или сырой текст обращения целиком.
Если вызовы моделей идут через единый шлюз, где уже есть маскирование PII и аудит-трейлы, эту схему проще держать в одном месте. Например, в RU LLM такие механизмы встроены в сам контур запроса, и это снижает шанс, что команда забудет про них на уровне отдельного сервиса. Но правило остается тем же: в журнале должен жить контекст решения, а не лишние данные.
Какие лимиты ставить с первого дня
Без жестких порогов модель почти всегда тратит больше запросов, чем человек ожидает. Один неудачный цикл уточнений легко превращает доступ к внутренним API в десятки лишних вызовов, рост счета и очередь в бэкенде.
Стартовый набор лимитов должен сдерживать и частоту, и глубину работы. Ставьте порог не только на запросы в минуту, но и на общий дневной объем. Минутный лимит спасает от всплесков, дневной - от тихой утечки, когда бот весь день дергает один и тот же метод из-за плохого промпта или странного ответа инструмента.
Для первого запуска обычно хватает нескольких правил:
- 3-10 вызовов в минуту на одну сессию или диалог
- 50-200 вызовов в день на пользователя или кейс
- не больше 1-2 параллельных вызовов инструмента на один запрос модели
- timeout 3-10 секунд и не более 1-2 повторов только для безопасного чтения
- автостоп после 3-5 ошибок подряд по одному инструменту
Параллельность недооценивают часто. Модель любит "проверить сразу все": профиль клиента, историю заказов, статус доставки, остаток бонусов. Для поддержки это звучит удобно, но внутренние сервисы получают всплеск нагрузки без пользы. Если ответ можно собрать по шагам, лучше разрешать один вызов за раз.
С повторами нужна жесткость. Повторять можно чтение, если сеть моргнула или сервис вернул 502. Повторять создание заявки, списание бонусов или смену тарифа опасно. Даже если API считает операцию идемпотентной, модель не должна бесконечно жать retry.
Отдельно ограничьте дорогие операции. У некоторых методов цена не в деньгах, а в ресурсе: долгий SQL-запрос, пересчет рекомендаций, поиск по большому архиву, запуск внешнего скоринга. Для них задают свой бюджет. Например, не больше пяти запусков на диалог или не больше одного тяжелого расчета после подтверждения человека.
Простой пример: бот поддержки ищет заказ и проверяет статус возврата. Это дешево. Но если он начинает заново пересчитывать компенсацию после каждого нового сообщения клиента, вы сжигаете ресурсы без пользы. Такой метод лучше закрыть отдельным лимитом и останавливать после серии ошибок или двух пустых результатов подряд.
Если у команды уже есть API-шлюз или единая точка вызова, лимиты лучше ставить там же. Тогда всплеск видно сразу, а не после разбора логов на следующий день.
Как отделить обратимые и необратимые действия
Не все действия в API можно исправить одинаково легко. Одно дело - обновить тег у заявки и вернуть старое значение. Другое - списать деньги, удалить запись или отправить письмо клиенту, которое уже ушло.
Поэтому инструменты лучше делить не по названию метода, а по цене ошибки. На практике хватает трех классов: чтение, обратимая запись и необратимое действие. Схема простая, но она сразу убирает много лишнего риска.
Обратимым считайте только то, что можно откатить быстро и без ручной чистки. Если для отката нужен инженер, ночной SQL-скрипт или разговор с клиентом, это уже не обратимое действие.
Списания, удаления, смену прав доступа, закрытие договоров и отправку внешних сообщений лучше сразу относить в отдельный класс. Для них модель не должна делать финальный вызов сама. Она может подготовить аргументы, собрать контекст и показать оператору понятный предпросмотр.
На старте стоит ввести несколько простых правил. Для рискованных операций включайте подтверждение человека. Добавляйте dry run или предпросмотр итоговых изменений. Сохраняйте снимок данных до записи. Храните идентификатор отката или компенсирующее действие. И держите аварийный стоп для всех write-операций в проде.
Dry run полезен даже в простых сценариях. Модель может показать, какой объект она изменит, какие поля тронет, что станет после записи и почему она выбрала именно этот вызов. Оператор видит не намерение, а будущий результат.
Снимок до изменения нужен не только для аудита. Он помогает быстро вернуть прошлое состояние, если модель выбрала не тот аккаунт, перепутала тариф или подставила старый параметр. Без такого снимка команда часто спорит, что именно было до вызова, и теряет время.
Аварийный стоп должен быть максимально простым. Один флаг или правило на шлюзе, которое мгновенно режет все операции записи в проде, когда вы видите странную серию вызовов. Чем проще механизм, тем выше шанс, что он сработает в плохой день.
Практический тест здесь один: если модель ошибется в пятницу вечером, сможете ли вы все вернуть за 10 минут. Если нет, действие надо относить к необратимым и оставлять за человеком.
Простой сценарий для поддержки
Представим типичный запрос: оператор получает сообщение "Где мой заказ и можно ли его отменить?" Модель помогает быстро собрать факты, но не получает полный контроль над заказом.
В этом сценарии scope очень узкий. Модель может прочитать статус заказа, дату доставки, статус оплаты и историю последних изменений. Этого хватает, чтобы дать оператору черновик ответа за несколько секунд.
При этом модель не может менять адрес, тариф, способ доставки или состав заказа. Эти методы лучше вообще не открывать. Если клиент в переписке пишет "смените адрес на новый", модель должна ответить, что это делает сотрудник по отдельной проверке, а не пытаться вызвать внутренний API.
С возвратом логика такая же. Модель может подготовить черновик заявки: подставить номер заказа, причину возврата, список позиций и пометку для оператора. Но она не проводит выплату и не запускает возврат денег. Деньги, бонусы и отмена отгрузки должны оставаться за человеком или за отдельным подтвержденным процессом.
Отмена заказа тоже не уходит в автомат. Даже если клиент просит отмену прямо и без сомнений, система передает задачу сотруднику. Причина простая: отмена может затронуть склад, доставку, промокоды и уже созданные документы. Ошибка тут стоит дороже, чем лишняя минута ручной проверки.
В таком потоке у модели остаются два безопасных действия: прочитать данные по заказу и собрать черновик возврата или ответа. Журналирование тоже должно быть понятным. Для каждого обращения система хранит номер тикета, какие чтения делала модель, был ли создан черновик и чем все закончилось: "ответили без изменений", "передали человеку", "возврат подтвержден сотрудником". Этого уже достаточно, чтобы разобрать спорный случай и понять, где модель помогла, а где ее вовремя остановили.
Если вызовы моделей проксируются через единый шлюз, такой сценарий удобно держать в одном контуре: отдельно задать доступные методы, отдельно вести логи и отдельно требовать подтверждение для любых действий с деньгами или отменой. Для команд, которые работают в российском контуре и не хотят разносить логи, биллинг и маршрутизацию по разным системам, этот подход особенно удобен.
Где команды ошибаются чаще всего
Самая частая ошибка проста: команда открывает доступ через продовый токен уже в первый день. Так быстрее проверить сценарий, но временные решения быстро становятся постоянными. Через несколько дней модель уже работает с живыми данными, а границы доступа никто толком не описал.
Следом появляется вторая ошибка: чтение и запись живут в одном scope. Тогда запрос на просмотр заказа идет с теми же правами, что и изменение статуса, скидки или адреса. Это удобно только до первого сбоя. Спокойнее разделять права по типу действия: отдельно читать, отдельно писать, отдельно удалять или отменять.
С журналами команды тоже часто промахиваются. Они включают полное логирование вызовов модели и сохраняют весь ответ целиком. Если внутри есть ФИО, телефон, адрес, номер договора или другие ПДн, эти данные начинают расходиться по очередям, хранилищам и бэкапам. В среде с требованиями 152-ФЗ это быстро превращается в лишний риск. Для обычного лога обычно хватает идентификатора запроса, имени инструмента, результата, кода ошибки и замаскированных полей.
Еще одна типовая проблема - отсутствие лимитов на массовые вызовы. Модель не устает и не делает паузу сама. Если промпт, маршрут или обработчик ответа сломался, она может за минуту отправить десятки одинаковых запросов. Так появляются массовые чтения, повторные записи и лишние изменения в учетных системах.
На старте достаточно четырех ограничений: лимит вызовов в минуту на один инструмент, лимит на число записей в одной операции, лимит на сумму или размер изменения и отдельный стоп для повторяющихся ошибок.
Самая дорогая ошибка всплывает позже. Команда дает модели право писать в CRM, биллинг или внутренний реестр, но не продумывает путь отката. Пока все идет спокойно, проблему не видно. Когда модель делает неверную запись, выясняется, что отменить ее можно только вручную, а иногда уже нельзя без следа.
Перед запуском полезно проверить три вещи: что модель может прочитать, что она может изменить и кто отменит каждое изменение за короткое время. Если на любой из этих вопросов ответ расплывчатый, доступ еще не готов.
Быстрая проверка перед запуском
За 15 минут до релиза полезнее не писать новые промпты, а пройтись по пяти точкам контроля. Если хотя бы одна из них неясна, модель лучше не пускать в прод.
У каждого вызова инструмента должен быть живой владелец внутри команды. Не абстрактный "backend", а конкретная роль: тимлид, владелец сервиса, дежурный инженер. Каждый scope должен быть привязан к задаче и роли. Если боту поддержки нужно читать статус заказа, ему не нужен доступ к смене тарифа или удалению аккаунта.
Логи должны скрывать ПДн, но сохранять полезный контекст: какой инструмент вызвали, с каким request_id и по какому правилу запрос отклонили. Лимиты должны реально срабатывать в тесте. Команда уже до релиза должна увидеть, как запрос получает deny после превышения квоты, rate limit или попытки вызвать запрещенный метод. И наконец, при инциденте никто не должен спорить, кто жмет стоп. Нужен один человек на смене или понятный канал эскалации.
Чаще всего проваливают именно логи и лимиты. В журналах оставляют email, телефон или номер договора, а ограничения существуют только в документе. Потом первый сбой случается уже на живых данных. Если вы работаете в российском контуре, это быстро упирается не только в безопасность, но и в требования по ПДн и аудиту.
Нормальный тест выглядит скучно, и это плюс. Вы берете один безопасный сценарий, например чтение статуса заявки, а потом специально ломаете его: даете лишний scope, превышаете лимит, отправляете строку с ПДн, вызываете не тот метод. Система должна отреагировать предсказуемо: скрыть чувствительные данные, записать причину отказа и не пропустить опасный вызов дальше.
Если команда использует RU LLM как единый OpenAI-совместимый шлюз, стоит до релиза проверить, что маскирование PII и аудит-трейлы уже включены на уровне маршрута, а не лежат в планах на потом. Иначе первый спорный вызов инструмента придется разбирать почти вслепую.
Признак готовности простой: любой дежурный за пару минут отвечает, какие методы доступны модели, где смотреть deny в журналах и как отключить вызовы без деплоя.
Что делать в первую неделю после запуска
Первая неделя после включения tool call редко проходит тихо. Именно в эти дни видно, где доступ слишком широкий, где схема инструмента неясна, а где модель вообще не понимает, когда нужно вызывать API, а когда лучше ответить без него.
Смотрите логи каждый день. Не общий график, а сами события: deny, ошибки валидации, таймауты и пустые вызовы. Пустой вызов выглядит так: модель выбрала правильный инструмент, но отправила пустые аргументы, перепутала обязательные поля или вызвала API без причины.
Полезно держать короткий ежедневный разбор: какие вызовы получили deny, какие запросы завершились ошибкой, где модель дернула API без нужды, какие scope ни разу не использовались и сколько раз оператору пришлось исправлять действие вручную.
Если какой-то scope за несколько дней не понадобился, убирайте его. Команды часто делают наоборот: открывают доступ с запасом, а потом забывают его сузить. В первую неделю лучше резать права быстро, пока трафик еще небольшой и поведение модели легко проверить вручную.
Отдельно проверьте точность выбора инструмента. Не нужен сложный стенд. Хватит набора из 30-50 реальных диалогов: где нужен вызов инструмента, где не нужен и какой именно API модель должна выбрать. Такой тест быстро показывает две частые проблемы: модель зовет не тот инструмент или зовет его слишком часто.
Спокойная первая неделя выглядит неэффектно, но именно это и нужно. Deny становится меньше, пустых вызовов почти нет, операторы не жалуются, а модель не просит лишних прав. Только после этого имеет смысл подключать следующий API. Если открыть сразу пять внутренних методов, ошибки маршрутизации, проблемы схемы и вопросы прав доступа смешаются в один шумный поток.
Если у вас уже несколько провайдеров моделей и нужен единый вход, хранение логов в РФ и аудит-трейлы по каждому запросу, полезно сверить свой контур с тем, как это устроено в RU LLM. Такой ориентир помогает быстро заметить пробелы в журналировании, хранении логов и контроле вызовов до того, как вы расширите набор инструментов.
Часто задаваемые вопросы
Когда модели вообще нужен tool call?
Да, если данные быстро меняются или без действия в системе модель бесполезна. Если вам хватает выгрузки раз в день или короткого контекста, живой доступ лучше не давать.
Можно ли начать с продового токена?
Нет. Для пилота берите тест или стейдж с безопасными, но не пустыми данными. Прод открывайте только после проверки логов, лимитов и сценария отката.
Почему нельзя дать модели доступ ко всей CRM?
Потому что модель выбирает из того, что вы ей показали, а не из ваших внутренних правил. Если рядом лежат чтение и запись, она может вызвать не тот метод и поменять данные по чужому customer_id или заказу.
Как понять, что scope достаточно узкий?
Нормальный scope описывает один рабочий путь. Зафиксируйте, что именно можно сделать, с какими объектами, какие поля можно читать или менять и от чьего имени идет вызов. Чтение, запись и удаление сразу разводите по разным разрешениям.
Что обязательно писать в журнал каждого вызова?
Оставьте в записи то, что помогает разобрать событие: request_id, время, user_id или id сессии, имя инструмента, версию схемы, решение allow или deny с короткой причиной и итог вызова. Этого обычно хватает, чтобы понять, кто что вызвал и чем все закончилось.
Что нельзя класть в логи?
Скрывайте все, что не нужно для разбора инцидента: токены, cookie, полные телефоны, адреса, номера документов, договоров и сырой текст пользователя без маскирования. Для связи событий обычно хватает хеша, последних четырех цифр или внутреннего id.
Какие лимиты ставить с первого дня?
На старте ставьте простой набор: лимит вызовов в минуту на сессию, дневной лимит на пользователя или кейс, не больше одного-двух параллельных вызовов, короткий timeout и повторы только для чтения. Если один инструмент дает несколько ошибок подряд, система должна сама остановить новые вызовы.
Какие действия модель не должна выполнять без человека?
Деньги, удаления, смену прав доступа, отправку внешних сообщений, отмену заказа и финальный возврат средств лучше оставить человеку. Модель может собрать аргументы, сделать dry run и показать предпросмотр, но не должна нажимать последнюю кнопку сама.
Как быстро проверить готовность перед запуском?
Перед релизом проверьте пять вещей: у каждого метода есть владелец, scope привязан к задаче, логи маскируют ПДн, лимиты уже срабатывают в тесте, а дежурный знает, как выключить write-вызовы без деплоя. Если хоть один пункт висит в воздухе, запуск лучше отложить.
Что контролировать в первую неделю после запуска?
Смотрите не только на общий график, а на сами события: deny, ошибки валидации, таймауты, пустые вызовы и выбор не того инструмента. Если какой-то scope не пригодился за несколько дней, убирайте его сразу, пока трафик еще легко проверить вручную.