Бюджеты деградации для LLM: что отключать при перегрузе
Бюджеты деградации для LLM помогают пережить перегруз без спешки: покажем порядок отключений, метрики и простой план для продакшена.
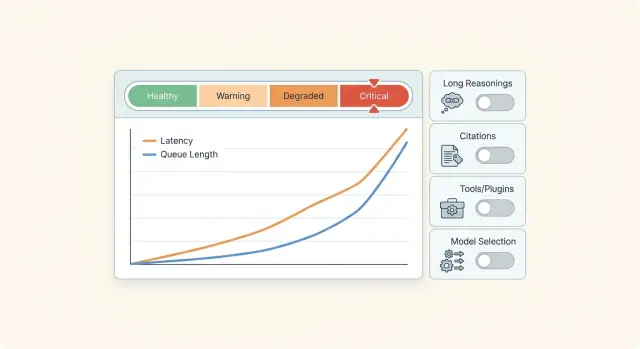
Где начинается перегруз
Перегруз начинается не тогда, когда сервис уже падает, а заметно раньше. Обычно команда сначала видит рост p95, потом очередь запросов, и только после этого приходят таймауты и жалобы пользователей. Если смотреть только на среднюю задержку, этот момент легко пропустить.
Ранние сигналы обычно простые: p95 и p99 растут быстрее обычного, очередь перестает разбираться между пиками, внешние вызовы и инструменты чаще уходят в таймаут, а ретраи начинают съедать заметную долю трафика. Еще один тревожный признак - один и тот же промпт все чаще уходит на более дорогую модель.
При перегрузе почти всегда растут и цена, и число ошибок. Причина понятна: система дольше держит запросы в работе, пользователи повторяют запросы, а ретраи раздувают нагрузку еще сильнее.
Что нельзя ломать первым
Во время перегруза нужно защищать не красоту ответа, а его смысл. Если после упрощения пользователь уже не может решить задачу, сервис сломан, даже если ответ стал быстрее и дешевле.
Сразу отделите обязательный результат от приятных добавок. Для одной фичи обязательным будет точный факт из базы. Для другой - короткая и понятная инструкция. Для третьей - безопасный отказ без домыслов. Цитаты, длинные объяснения, расширенный стиль ответа и часть форматирования часто можно убрать без боли. А вот статус заказа, сумма платежа или причина блокировки обычно неприкосновенны.
Минимум для каждого сценария
Полезно заранее описать минимальный формат ответа для каждого типа запроса. Не общий минимум для всей фичи, а отдельный для FAQ, операций по данным клиента, спорных случаев и регуляторных тем.
Для FAQ часто хватает короткого ответа и одного следующего шага. Для операций с данными клиента нужен точный результат из инструмента или честный отказ. Для спорных случаев нужен понятный перевод в саппорт с категорией обращения. Для регуляторных тем нужен ответ без выдумок и с сохранением следов проверки.
Такой минимум лучше формулировать очень приземленно. Не "полезный ответ", а, например, "назвать статус заявки, дату обновления и что делать дальше". Тогда сразу видно, что можно отключать первым. Длинные рассуждения почти всегда можно убрать. Цитаты тоже часто можно сократить. Премиальную модель иногда можно заменить. Но если ответ держится на вызове инструмента, отключать инструмент первым опасно.
Хорошая проверка звучит так: без какой части ответ станет неверным, пустым или начнет злить людей. Если после отключения растет число повторных обращений, оператор тратит больше времени, а пользователь жалуется, это не украшение, а основа сценария.
Привязка к SLA и жалобам
Границу минимума лучше закреплять не в описании модели, а в операционных метриках. Смотрите на три вещи: уложились ли вы в SLA, может ли саппорт подхватить диалог без ручного расследования и растут ли жалобы на "бот не помог".
Для команд с требованиями по 152-ФЗ это особенно важно в сценариях с персональными данными и аудитом. Если во время деградации пропадает проверяемость ответа или след запроса, проблема уже не только в качестве текста. Если вы работаете через шлюз вроде RU LLM, логично экономить на длине ответа или на более дорогой модели, но не трогать маскирование PII, хранение логов в РФ и аудит-трейлы. Более короткий ответ пользователь простит. Неверный ответ или потерю проверяемости - нет.
Как посчитать цену каждой опции
Чтобы понять, что можно отключать без боли, мало смотреть на общий счет. Нужна цена каждой функции отдельно: сколько она добавляет токенов, задержки и ошибок на 1000 запросов.
Сначала разбейте трафик на понятные типы запросов. Обычно хватает четырех групп:
- короткий вопрос без инструментов
- ответ с поиском по базе знаний
- длинный диалог с историей
- запрос, где нужен строгий JSON или цитаты
Для каждой группы снимите средние значения и p95 по входным и выходным токенам. Среднее покажет обычную цену, а p95 быстро найдет дорогие хвосты: раздутую историю, слишком длинные инструкции и многословные ответы.
Потом разложите задержку на части. Отдельно измерьте время ответа модели, вызовов инструментов и постобработки. На практике инструменты и проверки часто съедают больше времени, чем сама модель. Поиск по базе может добавить 300 мс, ранжирование еще 200 мс, а проверка цитат еще 400 мс. Без такого разреза легко обвинить модель там, где тормозит обвязка.
Дальше переведите это в деньги на 1000 запросов. Считайте не только токены модели, но и каждую опцию рядом с ней. Например, цитаты могут добавлять 18% входных токенов и 9% задержки, а премиальная модель может удваивать расход только на части трафика. В таком виде сразу видно, что обходится дорого почти всегда, а что - только в редких сценариях.
Сопоставьте цену с потерей качества
Экономия сама по себе ничего не решает. Для каждой опции нужен простой тест качества: точность ответа, полнота, доля успешных вызовов инструментов и процент диалогов без перевода на человека.
Сравнивайте не абстрактное "стало хуже", а потерю за конкретную экономию. Если отключение длинных рассуждений сократило выходные токены на 22% и почти не изменило долю принятых ответов, это хороший кандидат на первую ступень. Если смена премиальной модели дала экономию 35%, но число неточных ответов выросло вдвое, такое решение лучше держать ниже в очереди.
Когда у каждой функции есть четыре числа - токены, задержка, цена и просадка качества - бюджеты деградации перестают быть спором на ощущениях. Появляется таблица, по которой можно принимать решения на живом трафике.
Что отключать первым
Во время перегруза первым делом режьте то, что съедает много токенов, но слабо меняет итог для пользователя. Обычно это длинные рассуждения модели и слишком длинные ответы. Если бот вместо шести коротких предложений пишет четыре абзаца с повторами, вы платите больше, а пользы почти не прибавляется.
Следом обычно убирают длинные цитаты из документов, писем и базы знаний. Полная цитата нужна редко. В большинстве случаев хватает короткого фрагмента на одно-два предложения или аккуратного пересказа с указанием источника внутри системы. Смысл сохраняется, ответ становится короче, а нагрузка падает и на входе, и на выходе.
Премиальную модель не стоит менять вслепую. На бумаге переход на более дешевую модель выглядит как простой способ пережить перегрузку LLM-сервиса, но на реальных задачах просадка бывает болезненной: растет число уточнений, падает точность классификации, бот чаще уходит в общие формулировки. Сначала прогоните живой набор запросов - хотя бы 100-200 диалогов со сложными случаями, спорными формулировками и важными действиями.
Инструменты отключайте последними, если они дают факты или совершают действие. Поиск по базе, проверка статуса заказа, вызов CRM или калькулятора часто влияют на ответ сильнее, чем класс модели. Бот без инструмента звучит гладко, но может ошибаться в самом важном.
Порядок всегда зависит от сценария. Для поиска обычно сначала режут длину ответа и стиль, а доступ к данным оставляют. Для суммаризации чаще сокращают цитаты и объем вывода, потому что инструментов там обычно меньше. Для чата поддержки сначала убирают длинные объяснения, потом смотрят на смену модели, а действия через инструменты держат до последнего.
Простое правило такое: сначала отключайте украшения, потом дорогой интеллект, и только в конце - доступ к фактам и действиям. Иначе сервис формально останется жив, но перестанет решать задачу.
Как ввести ступени деградации
Ступени деградации лучше задавать заранее, а не придумывать в момент сбоя. Обычно хватает четырех режимов: норма, нагрузка, пик и авария. Этого достаточно, чтобы сервис не прыгал между десятком состояний и команда понимала, что происходит.
У каждого режима должны быть свои рамки. Опишите не только доступные функции, но и сухие лимиты: сколько входных токенов вы принимаете, сколько выходных токенов даете модели, сколько секунд ждете ответ и сколько ретраев разрешаете. Когда этих цифр нет, режимы быстро превращаются в слова без смысла.
- Норма: полный сценарий, обычные таймауты, стандартная модель, длинные ответы там, где они действительно нужны.
- Нагрузка: немного режете output tokens, снижаете таймауты, убираете дорогие необязательные шаги.
- Пик: сильнее ограничиваете длину ответа, отключаете часть tool calls, переводите часть запросов на более дешевую модель.
- Авария: оставляете только базовый поток, короткие ответы, строгий таймаут и отказ от всего, без чего сервис может прожить несколько минут или часов.
Переходы между уровнями должна делать автоматика по метрикам, а не дежурный инженер в чате. Чаще всего хватает четырех сигналов: p95 latency, размер очереди, error rate и расход токенов в минуту. Например, режим "пик" можно включать, если p95 держится выше 6 секунд три минуты подряд или очередь растет быстрее, чем воркеры успевают ее разбирать.
Возврат в полный режим задавайте отдельно. Если включать возврат по тем же порогам, сервис начнет дергаться туда-сюда. Лучше использовать более мягкое условие: вход в "пик" при p95 > 6 с, возврат только когда p95 < 4 с хотя бы 10 минут и доля ошибок снова в норме.
Если у вас есть единый OpenAI-совместимый шлюз и маршрутизация моделей, эти правила удобно держать рядом с роутингом. Тогда один и тот же запрос можно отправлять на другую модель или с другими лимитами без правок в приложении. В этом и есть практический плюс такого слоя: правила деградации живут рядом с маршрутами, а не размазаны по сервисам.
Перед релизом прогоните каждый режим хотя бы на части трафика. Даже 5-10% хватает, чтобы увидеть неприятные вещи: обрезанные ответы, сломанные JSON-схемы, таймауты инструментов и странные повторы. Бумажный план почти всегда выглядит лучше, чем ведет себя живой трафик.
Пример для чат-помощника поддержки
Бюджеты деградации проще всего проверять на чат-помощнике поддержки. У такого бота почти всегда есть ясная цель: дать верный ответ быстро и не разогнать стоимость запроса.
Представим бота для банка или ритейла. В обычном режиме он ищет ответ в базе знаний, берет несколько фрагментов, вставляет цитаты и пишет подробное объяснение на шесть-восемь абзацев. Читать такой ответ приятно, но он дорогой: поиск, длинный контекст и большой вывод съедают много токенов.
Когда очередь растет, первой лучше резать не поиск, а многословность. Если пользователь спросил, как перевыпустить карту или вернуть товар, ему редко нужен длинный разбор. Ему нужен короткий, точный ответ и понятный следующий шаг.
Это может выглядеть так:
- Уровень 0: поиск по базе, две-три цитаты, подробный ответ.
- Уровень 1: поиск остается, ответ сокращается до трех-четырех абзацев, внутренние рассуждения не выводятся.
- Уровень 2: поиск остается, бот дает одну короткую выдержку вместо длинных цитат.
- Уровень 3: поиск остается, но бот уходит с дорогой модели на более дешевую.
Такой порядок может показаться скучным, но он работает. Если убрать поиск слишком рано, бот начнет отвечать увереннее, чем знает, и поддержка быстро увидит всплеск ошибок. Если оставить поиск и урезать многословность, пользователь чаще всего почти не заметит разницы.
Ошибки, которые ломают план
Чаще всего план деградации ломается не на схеме, а в мелких решениях под нагрузкой. Команда спешит срезать то, что кажется дорогим, и случайно убирает то, что держало качество ответа на приемлемом уровне.
Самая частая ошибка - первой отключать инструмент, который тянет факты из базы, CRM или поиска. Да, вызов инструмента добавляет задержку и цену. Но без него модель начинает отвечать по памяти и угадывать. Для чат-помощника поддержки это хуже, чем короткий ответ или менее точная формулировка. Если бот больше не видит статус заказа или лимит по счету, он звучит уверенно, но ошибается.
Вторая ошибка - резко переводить трафик на более слабую модель без контрольного набора запросов. На глаз это почти всегда выглядит лучше, чем есть на самом деле. Нужны хотя бы 30-50 типовых диалогов: простые вопросы, конфликтные случаи, запросы с длинным контекстом, обращения с цифрами и датами.
Еще одна частая ошибка - пытаться "спасти" систему жестким лимитом токенов. После этого ответы обрываются на полуслове, теряют шаги инструкции или не доходят до развязки. Пользователь не видит экономию. Он видит сломанный ответ. Обычно лучше сначала убрать длинные рассуждения, сократить цитаты и шаблоны, а уже потом снижать лимит вывода.
Плохой план часто пытаются сделать общим для всех. Но сценарии у команд разные. Внутренний copilot для аналитиков может пережить короткий ответ. Помощник в поддержке платежей - нет, если исчезает доступ к инструменту проверки данных. Один и тот же порядок отключений редко подходит банку, ритейлу и SaaS-команде.
Поэтому полезно заранее зафиксировать несколько вещей:
- какие функции остаются неприкосновенными
- какие метрики команда смотрит в первые 15 минут
- какие сценарии нельзя переводить на слабую модель
- кто сообщает продукту и поддержке о включении режима деградации
Есть и еще одна ошибка, которая кажется мелкой, но бьет сильно: продукт и саппорт не предупреждают, что ответы станут короче. В итоге бизнес решает, что качество внезапно упало, хотя это запланированный режим. Если длина ответа, число цитат или глубина объяснения меняются, это нужно описать заранее простыми словами. Тогда короткий ответ не выглядит багом, а деградация остается управляемой.
Быстрая проверка перед релизом
Перед релизом нужен не еще один созвон, а короткий прогон по бумажному списку. Если сервис войдет в перегрузку ночью, команда не должна спорить, что выключать на уровне L2 и кто нажимает кнопку.
Хуже всего работает план, который существует только в голове у двух инженеров. Уровни деградации надо назвать прямо: например, L1 - убираем цитаты, L2 - режем длинные рассуждения, L3 - ограничиваем часть инструментов, L4 - переводим трафик на более дешевую модель. Рядом должен быть указан владелец решения: on-call, backend-лид, ML-инженер или дежурный SRE.
Чек-лист за 15 минут
Перед выкладкой проверьте пять вещей.
- Уровни деградации записаны в одном месте, и для каждого уровня есть человек, который может включить его без согласований в чате.
- На дашборде видны токены на запрос, p95, доля ошибок и стоимость. Если одна метрика спрятана, в реальной аварии ее никто не найдет.
- Для каждого уровня есть эталонные запросы. Это 10-20 типовых промптов, на которых видно, что сломалось после отключения цитат, tools или премиальной модели.
- Есть условие возврата в полный режим. Не "когда станет лучше", а конкретно: p95 ниже порога 15 минут, ошибки меньше 1%, очередь не растет.
- Даже в самом жестком режиме пользователь получает полезный минимум, а не пустую отписку.
Эталонные запросы лучше брать не красивые, а неприятные. Добавьте длинный диалог, запрос с вызовом инструмента, промпт с большим контекстом и один спорный кейс, где модель любит уходить в длинный ответ.
Полезный минимум тоже стоит сформулировать заранее. Для чат-помощника поддержки это может быть короткий ответ без поиска по системам: "Сейчас не могу проверить статус автоматически. Попробуйте номер заказа в личном кабинете или передайте оператору вот эти данные". Такой ответ слабее полного, но он помогает человеку сделать следующий шаг.
Если после проверки команда не знает, когда вернуть полный режим, релиз еще не готов. Перегрузка пройдет. Путаница в действиях останется надолго.
Что сделать дальше
Соберите простую матрицу по всем функциям LLM-фичи. Для каждой опции запишите три вещи: сколько она стоит, сколько добавляет задержки и насколько заметно влияет на ответ. Такой список быстро отрезвляет. Часто оказывается, что длинные рассуждения съедают много токенов, а цитаты из поиска тормозят ответ сильнее, чем смена модели на класс ниже.
Удобно держать это в одной таблице, где строка - отдельная функция: поиск по базе, цитирование источников, tool calling, расширенный system prompt, премиальная модель, длинный контекст, повторный запрос после ошибки. Рядом ставьте не абстрактную оценку, а числа из логов: медианную задержку, p95, среднюю цену на запрос и долю сессий, где функция действительно помогла.
После этого прогоните план деградации не на проде, а на обезличенных логах. Возьмите типичные диалоги за неделю и проиграйте их по ступеням: полный режим, мягкая деградация, жесткая деградация. Потом включите это на небольшой доле трафика и посмотрите, где пользователи начинают чаще переспрашивать, бросать сессию или звать оператора.
Не смешивайте разные сценарии в одно правило. Поиск, суммаризация и агентные цепочки ломаются по-разному:
- для поиска чаще можно урезать число документов и длину цитат
- для суммаризации безопаснее сокращать контекст и убирать рассуждения
- для агентных сценариев сначала режут число шагов, таймауты и дорогие инструменты
- смену модели лучше проверять отдельно, потому что она влияет на стиль ответа иначе, чем отключение инструментов
Если у вас несколько моделей и провайдеров, настройте fallback заранее. Нужны не только резервные маршруты, но и лимиты: максимум токенов, таймаут на провайдера, порог ретраев, бюджет на сессию и правило, когда запрос уходит на более дешевую модель. Иначе в момент перегруза команда начнет принимать решения вручную, а это почти всегда поздно.
Командам с OpenAI-совместимым стеком проще держать такие переключения в одном слое. Например, через RU LLM можно менять маршруты между моделями и провайдерами без правок SDK, кода и промптов: приложение продолжает ходить в тот же совместимый API, а команда меняет правила на уровне шлюза. Это особенно удобно, если у вас уже есть fallback между несколькими моделями и нужно быстро ввести лимиты под нагрузкой.
Если времени мало, начните с одного упражнения на этой неделе: выберите три самые дорогие функции, посчитайте их цену на тысячу запросов и решите, в каком порядке вы отключите их при росте трафика в два раза. После этого план перестает быть теорией.
Часто задаваемые вопросы
Как понять, что перегруз уже начинается?
Смотрите не на среднюю задержку, а на хвосты. Если p95 и p99 растут, очередь не успевает пустеть между пиками, а таймауты и ретраи занимают все больше трафика, перегруз уже начался.
Еще один частый сигнал — один и тот же запрос чаще уходит на более дорогую модель, а цена на 1000 запросов растет быстрее обычного.
Что отключать первым при росте нагрузки?
Сначала режьте то, что делает ответ длиннее и дороже, но почти не меняет смысл. Обычно это длинные рассуждения, многословные ответы и большие цитаты.
Так вы снижаете токены и задержку, не ломая сам сценарий для пользователя.
Почему не стоит сразу отключать инструменты?
Потому что инструмент часто приносит факт или делает действие. Если бот не видит статус заказа, сумму платежа или данные из CRM, он начинает гадать и ошибается в самом нужном месте.
Лучше оставить доступ к данным и упростить форму ответа, чем получить гладкий, но неверный текст.
Стоит ли сразу переводить трафик на более дешевую модель?
Нет, не первой. Смена модели выглядит как быстрая экономия, но на живом трафике она часто повышает число неточных ответов, уточнений и переводов на оператора.
Сначала прогоните хотя бы небольшой набор реальных диалогов со сложными случаями. Если качество держится, только тогда включайте более дешевую модель как следующую ступень.
Как определить минимально полезный ответ?
Опишите минимум отдельно для каждого сценария. Для FAQ это может быть короткий ответ и один следующий шаг, а для операций по данным клиента — точный результат из инструмента или честный отказ.
Проверьте себя просто: если без части ответа пользователь уже не может решить задачу или начинает чаще писать повторно, значит вы убрали не украшение, а основу.
Какие метрики лучше использовать для включения деградации?
Обычно хватает четырех метрик: p95 latency, размер очереди, error rate и расход токенов в минуту. Они показывают и скорость, и стабильность, и стоимость.
Порог возврата задавайте отдельно. Иначе сервис начнет дергаться между режимами, когда нагрузка колеблется около одного значения.
Как посчитать цену отдельной функции в LLM-фиче?
Разбейте трафик на типы запросов и для каждого посчитайте входные токены, выходные токены, задержку и ошибки. Потом измерьте, сколько добавляет каждая опция: поиск, цитаты, длинная история, строгий JSON, tool calling.
Считать удобнее в деньгах и миллисекундах на 1000 запросов. Тогда видно, что именно съедает бюджет почти всегда, а что срабатывает редко.
Как лучше настроить ступени деградации?
Заранее задайте 3–4 режима, например норма, нагрузка, пик и авария. Для каждого режима пропишите лимит входных и выходных токенов, таймауты, число ретраев и список доступных функций.
Автоматика должна переключать режим по метрикам, а не по сообщению в чате. Так команда не спорит ночью, что делать дальше.
Как проверить план деградации перед релизом?
Возьмите 10–20 неприятных запросов, а не красивые демо. Добавьте длинный диалог, вызов инструмента, большой контекст, спорный кейс и ответ с цифрами или датами.
Потом прогоните каждый режим на части трафика или на обезличенных логах. Если ответы обрываются, JSON ломается или пользователи чаще зовут оператора, план надо править до выкладки.
Что нельзя ломать в сценариях с персональными данными и аудитом?
Во время деградации не трогайте маскирование PII, хранение логов в РФ и аудит-трейлы. Экономить лучше на длине ответа, цитатах и выборе модели, а не на проверяемости запроса.
Если вы используете единый OpenAI-совместимый шлюз вроде RU LLM, команда может менять маршруты, лимиты и fallback без правок в приложении. Это помогает быстрее ввести нужный режим под нагрузкой.