Backpressure для LLM-шлюза: как сдержать очередь
Backpressure для LLM-шлюза помогает остановить рост очереди до таймаутов: лимиты, отсечение лишних запросов, приоритеты и метрики для прода.
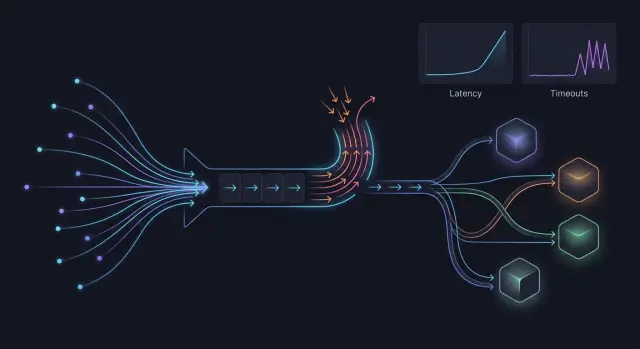
Почему очередь ломает шлюз раньше, чем кажется
Очередь почти никогда не растет линейно. Если шлюз получает 200 запросов в минуту, а провайдер успевает обработать только 120, лишние 80 не исчезают. Они копятся. Через несколько минут вы боретесь уже не с пиком, а с хвостом старых запросов.
Проблема не только в длине очереди. Каждый запрос держит память, соединение, слот воркера, а иногда и контекст стриминга. Поэтому переполненная очередь бьет по шлюзу раньше, чем CPU доходит до предела. Снаружи это выглядит как "внезапные таймауты", хотя сбой начался на пару минут раньше.
Таймаут через 30 секунд обычно хуже быстрого отказа. Пользователь ждет, приложение держит открытый запрос, а потом часто запускает повтор. Один неуспешный вызов превращается в два или три. Быстрый ответ 429 или 503 неприятен, но честен: клиент сразу понимает, что шлюз перегружен, и может снизить частоту запросов, подождать или переключить сценарий.
У шлюза для LLM есть еще одна ловушка. Один медленный провайдер легко тянет вниз весь контур. Если несколько маршрутов делят общий пул воркеров, исходящих соединений или лимит по стримам, задержка на одном провайдере быстро заражает соседние. Очередь растет уже не только на проблемном маршруте, а в общих ресурсах.
Это особенно заметно в прокси-схеме с единым API, совместимым с OpenAI. Снаружи все выглядит как один стабильный эндпоинт, но внутри у провайдеров разная скорость ответа, разные лимиты и разное поведение под нагрузкой. Если не резать поток заранее, медленный провайдер начинает съедать емкость для всех остальных.
Дальше запускается петля усиления: запросы дольше стоят в очереди, клиенты упираются в таймаут и делают повторы, в шлюз прилетает еще больше копий тех же вызовов, а соседние сервисы тоже получают всплеск. Поэтому защита от таймаутов начинается не на 30-й секунде, а в тот момент, когда очередь только пошла вверх. В этом и смысл backpressure: не дать системе взять больше работы, чем она может переварить без цепной реакции.
Где ставить backpressure в цепочке запроса
Один общий лимит редко спасает. Если поставить его слишком низко по цепочке, очередь просто переедет дальше и начнет душить уже не шлюз, а соседние сервисы, воркеры и базу с метаданными.
Первый барьер нужен на входе HTTP. Не после аутентификации, не в очереди задач и не на уровне провайдера. Шлюз должен быстро решить, что делать с запросом: принять его сейчас, попросить повторить позже или сразу отклонить. Иначе открытые соединения копятся, память растет, а таймаут приходит раньше, чем модель вообще увидит запрос.
На этом слое обычно хватает двух ограничений: лимита на число параллельных запросов и короткой очереди на прием. Если у вас единый API, совместимый с OpenAI, это удобно еще и тем, что поведение меняется на стороне шлюза, а клиентский код можно не трогать.
Второй барьер ставят до выбора модели и провайдера. Маршрутизация тоже тратит ресурсы: правила, проверки политик, подсчет стоимости, запасные маршруты. Если держать длинную очередь до этого шага, вы уже жжете CPU на запросы, которые не успеют в целевую задержку. Небольшая очередь и ранний отказ обходятся дешевле.
Отдельный контроль нужен для стриминга. Модель может ответить быстро, но медленный клиент держит соединение еще минуту и больше. В этот момент заняты буферы, сетевые сокеты и иногда сам воркер. Для запросов со стримингом лучше задавать свой лимит открытых потоков, порог на размер буфера и таймаут на слишком медленное чтение ответа клиентом.
Трафик тоже стоит разделить. Интерактивные запросы лучше держать в самой короткой очереди и пропускать первыми. Пакетные задачи отправляют в отдельный пул и режут без сожаления при перегрузе. Внутренние задачи вроде eval или пересчета кэша должны жить под жестким лимитом и не спорить с пользовательским трафиком.
Нормальный контроль очереди выглядит скучно: короткие очереди, быстрый отказ и разные лимиты по классам трафика. Это надежнее, чем "терпеливый" шлюз, который принимает все подряд и потом валит таймаутами половину системы.
По каким сигналам резать входной поток
Очередь редко ломает шлюз сама по себе. Сначала растет время ожидания, потом клиенты начинают повторять запросы, а уже после этого сыпятся соседние сервисы. Поэтому backpressure лучше включать не по одному порогу, а по нескольким сигналам сразу.
Первый сигнал - длина очереди и скорость ее роста. Само число запросов мало что значит. Очередь в 50 задач может быть нормой утром и аварией вечером, если за минуту она выросла с 5 до 50 и не замедляется. Смотрите не только на текущую точку, но и на наклон.
Второй сигнал - отношение времени ожидания к времени обработки. Если запрос ждет 8 секунд, а модель отвечает за 2, проблема уже не в модели, а во входном потоке. Когда ожидание сравнялось с обработкой или обогнало ее, очередь перестает быть буфером и начинает съедать запас по задержке.
Третий сигнал - лимиты соединений и параллелизма у провайдеров. Шлюз при этом может выглядеть живым: CPU не забит, память еще держится, но пул соединений уже уперся в потолок. После этого каждый новый запрос только удлиняет хвост очереди.
Четвертый сигнал - токены в секунду. Считать только RPS грубо. Десять коротких запросов и десять длинных диалогов выглядят одинаково по числу вызовов, но нагружают систему по-разному. Если токены на входе растут быстрее, чем шлюз и провайдеры успевают их обработать, поток пора резать даже при нормальном RPS.
Еще один маркер - отмены, таймауты и доля повторов. Они показывают, что система уже пошла вразнос. Если клиент отменяет запросы из-за долгого ожидания или сервисы начинают дергать один и тот же вызов повторно, реальная нагрузка становится выше видимой.
На практике удобно держать простое правило: режьте входной поток, если одновременно выполняются хотя бы два условия. Очередь растет несколько минут подряд, ожидание стало дольше обработки, пул соединений почти заполнен, токены в секунду уперлись в потолок, а таймауты и повторы пошли вверх. Один сигнал может шуметь. Два сигнала обычно уже говорят, что пора тормозить вход, пока очередь не превратилась в аварию.
Как ввести backpressure по шагам
Начинать лучше не с очереди, а с бюджета. Сначала решите, сколько трафика шлюз вообще может принять без срыва целевой задержки. Считать стоит сразу в трех плоскостях: запросы в секунду, токены в минуту и число одновременных соединений.
Один общий лимит почти всегда врет. Интерактивный чат, пакетные задачи и длинные суммаризации нагружают шлюз по-разному. Если у вас единый вход для разных моделей и провайдеров, задайте бюджеты хотя бы по типам трафика и крупным клиентским пулам.
Дальше нужен жесткий потолок очереди. Не "пусть подождет", а конкретное число, после которого шлюз больше не принимает новые запросы в этот пул. Если пользователь готов ждать 10 секунд, а модель часто тратит 7-8, очередь не должна съедать еще 15. Короткая очередь раздражает меньше, чем долгое ожидание с таймаутом в конце.
Для старта хватает нескольких простых правил. Зафиксируйте бюджет на входе для каждого пула, задайте максимум одновременных запросов и длину очереди, режьте прием сразу после исчерпания лимита и отделите быстрый интерактивный трафик от длинных задач.
Код ответа тоже лучше выбрать заранее. Если клиент превысил свой лимит, отдавайте 429. Если сам шлюз или провайдер уже уперся в потолок, честнее вернуть 503. Быстрый отказ за 50-100 мс почти всегда лучше, чем запрос, который висит, потом падает по таймауту и тянет за собой соседние сервисы.
Даже простая приоритизация дает заметный эффект. Короткие пользовательские запросы стоит пускать в отдельный пул с маленькой очередью. Длинные задачи, которые могут сжечь много токенов и держать соединение десятки секунд, лучше вынести в свой пул или пропускать через отдельный лимитер.
С повторами нужна жесткость. Один неудачный запрос не должен порождать лавину дублей на каждом слое. Обычно хватает одной-двух повторных попыток со случайной паузой, например 200-800 мс. Если и клиент, и шлюз, и воркер повторяют запрос независимо друг от друга, перегрузка растет сама от себя.
Перед выкладкой проверьте схему и на обычном, и на пиковом трафике. Прогоните нагрузку в 2-3 раза выше средней и смотрите не только на p95, но и на длину очереди, долю отказов, время ожидания до старта обработки и число таймаутов в соседних сервисах. Нормальный результат выглядит так: отказов стало больше раньше, чем начали сыпаться таймауты по всей системе.
Сценарий из прода: вечерний пик в поддержке
В 19:10 у банка падает мобильное приложение после неудачного релиза. Через несколько минут чат поддержки получает поток в несколько раз выше обычного. Люди пишут коротко: не могу войти, где перевод, почему карта отклонена. Операторам нужны быстрые подсказки от модели, а клиентам нужен ответ почти сразу.
Проблема начинается, когда в тот же шлюз летят совсем другие задачи. Супервайзеры просят сводку по инциденту, команда качества запускает длинные разборы диалогов, аналитики тянут отчеты по темам обращений. Такие запросы больше и дороже. Они держат воркеры заметно дольше, чем короткий ответ оператору в чате.
Если шлюз складывает все в одну очередь, длинные запросы занимают свободные слоты первыми. Чат начинает ждать 10, 15, 20 секунд. Потом приходят таймауты, операторы жмут отправку повторно, и очередь пухнет еще быстрее. В этот момент страдает уже не только слой моделей. Проседают соседние сервисы, которые ждут ответ от шлюза и копят свои повторы.
Здесь backpressure нужен не для красоты, а чтобы тяжелый трафик не задавил интерактивный. Сообщения из операторского чата стоит пустить в отдельный класс с высоким приоритетом. Длинные аналитические запросы надо резать по параллелизму и по лимиту токенов. Несрочные задачи лучше увести в отдельную очередь до спада нагрузки.
Такой расклад обычно работает лучше, чем одна "честная" очередь для всех. Операторскому чату хватает маленького пула воркеров и жесткого лимита ожидания в несколько секунд. Если слот не освободился вовремя, шлюз сразу отказывает или дает упрощенный маршрут на более быструю модель. Это неприятно, но намного лучше, чем молчание и повторные клики по кнопке отправки.
Длинные запросы при этом не пропадают. Они ждут в своей очереди с низким приоритетом и отдельным бюджетом. Когда пик спадает, система добирает их без вреда для чата. На практике такая приоритизация часто удерживает ответ в пределах SLO даже во время сбоя: пользователь видит, что поддержка жива, оператор не борется с зависшим интерфейсом, а команда не тушит пожар сразу в трех сервисах.
Что делать с длинными и дорогими запросами
Если вы настраиваете backpressure, считать только число запросов мало. Один запрос с промптом на 60 000 токенов и длинной генерацией может держать слот десятки секунд и съесть столько же ресурса, сколько сотни коротких диалогов.
Из-за этого очередь часто ломается тихо. По RPS все выглядит терпимо, а по факту воркеры заняты, таймауты растут, а повторы добивают соседние сервисы. Поэтому нагрузку лучше считать в токенах на входе, токенах на выходе и секундах выполнения.
Жесткие пределы для тяжелых запросов
Сразу режьте два параметра: размер промпта и ожидаемый объем вывода. Если клиент просит слишком большой контекст или ставит max_tokens без разумного потолка, шлюз должен отклонить такой запрос еще до общей очереди. Ранний отказ почти всегда дешевле, чем медленный отказ через 40 секунд.
Длинный контекст лучше отправлять в отдельную очередь. Суммаризация отчетов, разбор больших документов и пакетные задачи не должны стоять рядом с интерактивными запросами из чата или поддержки. Иначе один тяжелый пакет задержит все короткие ответы, а пользователи увидят, что сервис тормозит, хотя проблема только в одном классе трафика.
Простое правило здесь такое: короткие запросы идут через быструю очередь с низкой задержкой, длинные - через отдельный пул с малой конкуренцией, а пакетные задачи запускаются только на остаточной емкости.
Сокращайте лишнюю работу
Если роутер опрашивает несколько моделей параллельно, стоимость и нагрузка резко растут. Под давлением лучше уменьшить число кандидатов, чем держать красивую, но дорогую схему выбора. Когда система близка к пределу, один маршрут к подходящей модели обычно лучше, чем три параллельных запроса ради небольшого выигрыша в качестве.
Еще одна частая потеря ресурса - запросы, которые клиент уже бросил. Пользователь закрыл вкладку, мобильное приложение оборвало соединение, провайдер словил таймаут, а генерация все еще идет. Шлюз должен сразу отменять такой запрос у провайдера и освобождать слот. Иначе вы тратите токены и GPU-время на ответ, который никто не получит.
На дашборде полезнее видеть не просто число запросов в минуту, а входные токены, выходные токены и суммарное занятое время по длинной очереди. Эти метрики намного точнее показывают, когда пора резать поток.
Ошибки, которые быстро выбивают соседние сервисы
Самая частая ошибка проста: команда слишком долго терпит растущую очередь. Всем кажется, что пик скоро спадет и шлюз догонит хвост. На деле очередь съедает память, держит соединения открытыми и тянет вниз сервисы рядом с ней: авторизацию, биллинг, логирование, аудит.
Когда запрос висит в очереди 5-10 секунд, он все еще занимает слот, таймеры и сетевые ресурсы. Потом клиент получает таймаут и часто отправляет новый запрос. Так один всплеск быстро превращается в два. Для такого шлюза честный отказ части трафика почти всегда безопаснее, чем медленное падение всего контура.
Вторая ошибка - один общий лимит на весь поток. Так нельзя, если вместе идут чат, фоновые пакетные задачи и внутренние оценки. Пакетная обработка легко съест весь запас, а поддержка и продуктовый интерфейс будут ждать в той же очереди. Приоритеты должны быть явными: кто идет первым, кто подождет, а кому вы сразу вернете отказ.
Еще один короткий путь к аварии - агрессивные повторы. Если клиент, воркер и сам шлюз делают по три повтора без паузы, один неудачный запрос превращается в 9 или 27 попыток. Это уже не восстановление, а усилитель перегруза. Нужны пауза, случайный сдвиг и жесткий предел повторов.
Часто поток режут только по QPS и считают задачу закрытой. Для LLM этого мало. Десять коротких запросов и десять промптов по 50 тысяч токенов дают разную нагрузку на очередь, GPU и сеть. Смотрите хотя бы на две оси: число запросов и ожидаемый объем токенов.
Что замечают слишком поздно
Средняя задержка часто успокаивает раньше времени. Пока среднее выглядит нормально, хвост уже горит. Если p95 и p99 растут, а очередь не сжимается даже после конца пика, соседние сервисы уже получают удар.
Поэтому метрики лучше разнести. Смотрите отдельно на длину очереди по приоритетам, число активных повторов, токены в обработке и токены в ожидании, долю таймаутов по каждому провайдеру и нагрузку на логирование с аудитом. Если рядом со шлюзом живут биллинг, маскирование PII и аудитные следы, ошибка в backpressure редко остается локальной. Сначала проседает ответ модели, а через минуту начинают захлебываться сервисы, которые вообще не должны платить за чужую очередь.
Быстрые проверки перед выкладкой
Перед выкладкой backpressure лучше проверять как аварийный тормоз, а не как красивую настройку. Пока трафик ровный, почти любая схема выглядит нормально. Проблемы начинаются в тот момент, когда один медленный провайдер отвечает дольше обычного, а очередь уже успела съесть память, воркеры и таймауты соседних сервисов.
Сначала проверьте потолок очереди. Он должен быть жестким и понятным: либо фиксированное число запросов, либо лимит по сумме ожидаемых токенов. Если очередь может расти еще чуть-чуть, она почти всегда вырастет слишком сильно. Для такого шлюза лучше честно отказать части новых запросов, чем держать их 20-30 секунд без шанса на нормальный ответ.
Вторая проверка - учет размера запроса до отправки к модели. Шлюз должен хотя бы грубо считать входные и ожидаемые выходные токены заранее. Иначе короткий чат и огромный пакет попадут в одну очередь как будто они равны, хотя второй заберет на порядок больше времени и денег.
Перед релизом обычно хватает пяти вещей: жесткого лимита очереди без мягкого переполнения, учета токенов до вызова модели, явного кода отказа вроде 429 или 503, раздельных метрик для ожидания, обработки и отмен, а также нагрузочного теста, который повторяет вечерний пик и отдельно добавляет медленного провайдера.
Метрики особенно часто пропускают. Если wait time, service time и cancel rate лежат в одной куче, команда поздно замечает, что проблема не в модели, а в накоплении запросов перед ней. Тогда люди начинают крутить таймауты, хотя надо резать входной поток раньше.
И еще одна простая проверка: откройте ответ отказа глазами клиента. Хороший ответ короткий и честный. Плохой маскирует перегрузку под внутреннюю ошибку, и потом поддержка тратит полдня на разбор того, что шлюз сам уже знал в первые миллисекунды.
Что делать дальше в проде
Backpressure редко чинят сразу по всей системе, и это нормально. Возьмите один сервис с понятной нагрузкой и один класс трафика, например обычные запросы из внутреннего чата поддержки. Если начинать со всего потока сразу, вы быстро запутаете и метрики, и причины отказов.
Сначала зафиксируйте SLO. На практике хватает двух чисел: приемлемой задержки для успешных ответов и доли быстрых отказов, которую сервис может пережить без каскада таймаутов. Быстрый отказ почти всегда лучше, чем очередь на 40 секунд, после которой падает и ваш шлюз, и соседние API.
Потом прогоните нагрузочный тест так, как люди работают в реальности. Не берите усредненный промпт на 500 токенов, если в проде летят длинные истории диалога, вложенные инструкции и повторы от клиента. На синтетике схема часто выглядит хорошо, а на первом же пике разваливается, потому что повторы умножают очередь в два или три раза.
Минимальный план простой: выберите один маршрут и один лимит, который команда может объяснить; снимите базовые метрики до включения backpressure; прогоните тест с реальными размерами промптов, стримингом и повторами; включите быстрый отказ для лишнего трафика и проверьте, как его обрабатывает клиент; затем посмотрите, не поползли ли таймауты у зависимых сервисов.
Если у вас стек, совместимый с OpenAI или OpenRouter, такую схему удобно быстро проверить на RU LLM. Достаточно сменить base_url на api.rullm.com и оставить текущие SDK, код и промпты без изменений. Это позволяет посмотреть, как ведут себя маршрутизация, лимиты и очереди, без отдельной миграции клиента.
Для контуров с требованиями 152-ФЗ смотрите не только на задержку. Отдельно проверьте, где лежат логи и бэкапы, как устроены аудитные следы по запросам и скрываются ли персональные данные в логах. Если в пике вы режете поток, потом должно быть видно, какой запрос отклонили, по какому правилу и что именно увидел оператор.
После первого запуска не крутите все ручки сразу. Дайте системе прожить хотя бы один обычный день и один вечерний пик. Потом меняйте только один параметр за раз: размер очереди, лимит параллелизма или порог быстрого отказа. Так будет понятно, что именно помогло, а что просто совпало.
Часто задаваемые вопросы
Что такое backpressure простыми словами?
Это простой способ не брать в работу больше запросов, чем шлюз и провайдер реально тянут. Как только очередь растет слишком быстро, шлюз сразу режет лишний поток, а не держит его до таймаута.
Почему быстрый отказ лучше долгого таймаута?
Потому что быстрый отказ не забивает очередь и не провоцирует лишние повторы. Если клиент уперся в свой лимит, верните 429; если сам шлюз или провайдер уже на пределе, честнее отдать 503.
Где ставить первый лимит в LLM-шлюзе?
Ставьте первый барьер прямо на входе HTTP. Шлюз должен решить судьбу запроса сразу, иначе открытые соединения, память и воркеры забьются еще до вызова модели.
По каким сигналам понять, что очередь уже опасна?
Смотрите не на один график, а сразу на несколько. Обычно перегруз видно по росту очереди, по тому, что wait time догнал service time, по забитому пулу соединений, по росту токенов в секунду и по всплеску таймаутов с повторами.
Нужен ли отдельный лимит для стриминга?
Да, для стриминга лучше держать свой лимит. Медленный клиент может долго держать сокет и буферы, даже если модель ответила быстро, поэтому задайте потолок на число потоков и таймаут на слишком медленное чтение.
Как разделить интерактивный и пакетный трафик?
Не кладите их в одну очередь. Чат и поддержка должны идти через короткий пул с малым ожиданием, а пакетные и фоновые задачи — через отдельный пул с низким приоритетом и своим бюджетом.
Что делать с длинными и дорогими запросами?
Режьте такие запросы еще до общей очереди. Ограничьте размер промпта и ожидаемый вывод, а длинные суммаризации и большие документы отправляйте в свой пул, чтобы они не тормозили короткие ответы.
Сколько повторов стоит разрешать?
Не давайте каждому слою повторять запрос по своему правилу. На практике хватает одной-двух попыток со случайной паузой вроде 200–800 мс; больше обычно только раздувает перегруз.
Как проверить backpressure перед релизом?
Прогоните нагрузку хотя бы в 2–3 раза выше средней и отдельно добавьте медленного провайдера. Потом проверьте, что очередь упирается в жесткий потолок, отказы приходят быстро, а соседние сервисы не тонут в таймаутах.
С чего начать внедрение backpressure в проде?
Начните с одного маршрута и одного класса трафика, например с чата поддержки. Зафиксируйте SLO, снимите базовые метрики, включите короткую очередь и быстрый отказ, а потом меняйте по одному параметру за раз, чтобы видеть реальный эффект.