Аудит-трейл для LLM в банке: что логировать по запросу
Аудит-трейл для LLM в банке: какие события писать по каждому запросу, чтобы ИБ, разработка и внутренний аудит сверяли факты по одним данным.
Почему споры начинаются без следа по запросу
В банке один и тот же эпизод легко превращается в несколько разных версий. ИБ видит ночной вызов модели с большим объемом текста и считает его подозрительным. Продуктовая команда смотрит на тот же случай и говорит, что сотрудник просто несколько раз переформулировал запрос.
Спор начинается там, где нет полного следа по каждому запросу. Если в логах остался только финальный ответ модели, уже нельзя точно восстановить, что отправил пользователь, какой маршрут выбрал шлюз, сработала ли маскировка PII, был ли ретрай и что вернул провайдер на каждом шаге. Аудитор просит цепочку событий, а команда показывает фрагменты из разных систем.
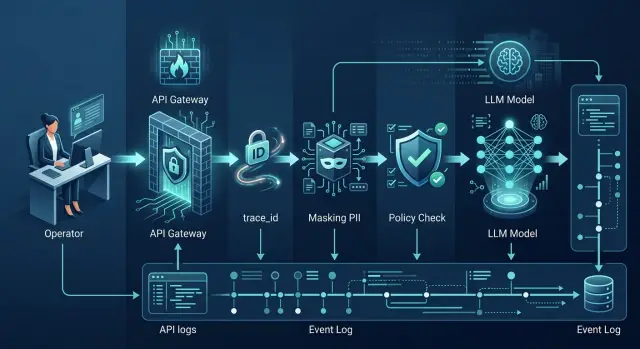
Проблема быстро становится практической. В одном журнале время запроса - 14:03:11, в другом - 14:03:14, в третьем запись вообще живет под своим внутренним ID. Приложение, API-шлюз, прокси, провайдер модели и SIEM часто пишут события в разном формате. Если у них нет общего request_id, собрать одну понятную историю трудно.
В банковской среде это особенно заметно. Один запрос может пройти через фронт, сервис оркестрации, DLP-проверку, LLM-шлюз и только потом попасть в модель. Когда на каждом этапе свои часы и свои идентификаторы, любая проверка превращается в ручное расследование. На это уходят часы, а иногда и дни.
Поэтому аудит-трейл для LLM нужен не для отчета. Он нужен, чтобы у ИБ, разработки, внутреннего аудита и владельца продукта был один набор фактов. Когда у каждого шага есть единый request_id, точное время и понятная последовательность событий, разговор сразу становится спокойнее. Обсуждают уже не догадки, а конкретный запрос и конкретные действия системы.
Что считать одним запросом
Для аудита один запрос - это не каждый сетевой вызов модели. Это одно действие пользователя или один шаг бизнес-процесса, который система обрабатывает как целое.
Если клиент в мобильном банке спрашивает, почему не прошел перевод, внутри может появиться целая цепочка: входной API-вызов, поиск по базе знаний, tool call в CRM, обращение к модели и еще один вызов из-за ретрая. Для аудита это один запрос с несколькими шагами, а не пять отдельных историй.
Чаще всего команды путают запрос с попыткой доставки. Ретрай после таймаута, повтор у другого провайдера или fallback на вторую модель не создают новый запрос. Это новая попытка внутри того же запроса. Если считать иначе, ИБ видит одно число, разработка другое, а аудит потом спорит, сколько событий было на самом деле.
На старте цепочки стоит ввести три уровня идентификаторов:
session_id- вся сессия клиента или сотрудникаrequest_idилиtrace_id- один пользовательский запрос внутри сессииspan_id- отдельное действие внутри обработки
Если шаг порождает другой шаг, сохраняйте parent_span_id. Тогда порядок событий можно восстановить без догадок.
Сразу добавьте и бизнес-контекст. Одних технических ID мало. Обычно хватает канала, сессии и кода сценария. Каналом может быть мобильное приложение, чат оператора или внутреннее рабочее место сотрудника. Сценарий лучше хранить как фиксированное значение, например card_dispute, loan_review или aml_check, а не как свободный текст. Так потом проще искать инциденты и строить выборки.
Если банк идет к моделям через единый OpenAI-совместимый шлюз, trace_id лучше создавать до первого внешнего вызова и передавать дальше по всей цепочке. Тогда один и тот же идентификатор пройдет через маршрутизацию, ретраи и обращения к разным провайдерам.
Простое правило выглядит так: один запрос - это одно намерение пользователя или один шаг процесса, даже если внутри система сделала десять технических действий.
Что писать на входе
В начале запроса нужно зафиксировать несколько опорных фактов. Если их нет, спор потом идет не о рисках, а о том, что вообще произошло и кто запустил сценарий.
Сначала запишите request_id и точное время старта. Этот идентификатор должен жить на всем пути запроса, чтобы связать между собой gateway, бизнес-сервис, проверку политик и ответ модели. Время лучше хранить с миллисекундами и в одном формате для всех систем. Иначе журнал не собрать в одну линию.
Дальше сохраните источник запроса. Обычно хватает нескольких полей: сервис, канал, имя сценария, actor_type и идентификатор пользователя или сотрудника, если правила доступа позволяют его хранить. В банковском сценарии это может быть CRM оператора, мобильное приложение или внутренний помощник. Для обращений сотрудников часто полезны operator_id, case_id, tenant_id и код подразделения.
Если до вызова модели уже известны версия шаблона, версия политики или класс данных, запишите и это. Тогда позже не придется гадать, какая именно конфигурация работала в момент инцидента.
На входе полезно зафиксировать и базовое решение по данным: содержит ли запрос персональные данные, нужен ли режим повышенного контроля, допустим ли внешний провайдер, требуется ли обработка только в российском контуре. Эти поля выглядят скучно, но именно они потом объясняют, почему система выбрала один маршрут, а не другой.
Что записывать во время обработки
Во время обработки спор обычно возникает не из-за финального ответа, а из-за цепочки решений. Журнал должен показать, как запрос прошел через роутер, кеш, поиск по документам и вызовы внешних сервисов. У каждого события должны быть время, номер шага и связка с trace_id.
Сохраняйте фактические значения, а не только то, что прислал клиент. Если шлюз или внутреннее правило поменяли модель, это должно быть видно в логе. Обычно достаточно полей effective_model, provider и base_url, а рядом - имя правила маршрутизации, его версия и короткая причина выбора. Например: обработка только в РФ или переход на резервный маршрут после ошибки основного провайдера.
Удобно фиксировать четыре группы событий:
- события маршрутизации: какая модель выбрана, у какого провайдера, по какому правилу и по какой причине
- события контекста: сработал ли
prompt caching, был лиcache hitилиcache miss, какойcache_idиспользован - события retrieval и инструментов: какие
index_id,document_idи версии документов попали в контекст, к какимexternal_system_idобращалась система, сколько длился шаг и чем он закончился - события контроля: применились ли маскирование PII, метки
AI-Law,policy_idи другие проверки
Для retrieval мало знать только ID документов. Лучше хранить еще index_id, версию эмбеддингов и порог отбора. Тогда команда видит, почему модель получила именно эти фрагменты, а не соседние. Для вызовов инструментов полезны код результата, длительность и причина повторного вызова, если он был.
Если часть маршрута проходит через RU LLM, единый trace_id удобно протянуть через маршрутизацию, ретраи и обращения к разным провайдерам без смены SDK, клиентского кода и промптов. Это упрощает разбор, особенно когда в одной цепочке участвуют несколько моделей.
Что фиксировать на выходе и при ошибке
На выходе спорят чаще всего. Один человек видит нормальный ответ, другой помнит отказ, третий находит таймаут в клиенте. Поэтому журнал должен сохранять не только сам факт ответа, но и итоговый статус запроса.
Успешный ответ
Для каждого завершенного запроса запишите точное время ответа, общую задержку и разложение по этапам, если оно у вас есть: очередь, маршрутизация, ответ провайдера, постобработка. Общая цифра полезна, но для разбора почти всегда нужен состав задержки.
Рядом сохраните число входных и выходных токенов, finish_reason и код ответа API. Если модель остановилась по length, safety или tool_call, это меняет и оценку качества, и стоимость. Один и тот же пользовательский текст может выглядеть как плохой ответ, хотя причина гораздо проще - лимит токенов.
Отдельно отметьте, что произошло с ответом после модели. Система могла отредактировать текст, скрыть часть фрагментов, полностью заблокировать выдачу или перевести диалог на человека. Такие действия лучше логировать как отдельные события с причиной и rule_id, а не прятать в одном поле status.
Ошибка и разбор
Если запрос завершился ошибкой, сохраните ее класс и место возникновения: клиент, шлюз, провайдер, фильтр безопасности или внутренняя бизнес-логика. Одного кода 500 недостаточно. Команде безопасности нужен тип сбоя, а аудиту нужен маршрут, по которому система пришла к этому итогу.
У каждой проверки безопасности должна быть версия. Записывайте, какой фильтр сработал, какой версией правил он пользовался и что именно вернул: allow, redact, block или review. Если банк позже обновит политики, команда сможет отделить ошибку модели от старой версии фильтра.
Когда запрос уходит на разбор, привяжите к нему incident_id, тикет или номер очереди, а также финальный статус разбора. Через месяц это экономит много времени. Иначе никто уже не вспомнит, почему ответ не дошел до клиента и кто принял решение остановить его.
Как логировать без лишних персональных данных
В банке спор часто начинается не из-за модели, а из-за самих логов. Если в аудит попал полный клиентский текст с ФИО, номером карты и паспортом, ИБ видит риск. Если в журнале почти ничего нет, расследование теряет смысл.
Рабочий компромисс обычно проще, чем кажется. По умолчанию не храните в аудите полный промпт и полный ответ. Для большинства случаев достаточно трех вещей: хеш исходного текста, короткий фрагмент без чувствительных данных и идентификатор записи в защищенном архиве, где полный материал лежит по отдельным правилам доступа.
Такой подход помогает доказать факт обращения, сверить версию данных и не разносить персональные данные по десяткам систем. Хеш показывает, что текст не меняли. Короткий фрагмент дает быстрый контекст. Архив закрывает редкие случаи, когда нужен полный разбор.
Маскирование лучше делать до попадания события в централизованный лог. Иначе исходные данные успеют разойтись по очередям, резервным копиям и системам мониторинга. Обычно в первую очередь скрывают ФИО, телефон, номер карты, паспортные данные и адрес электронной почты.
Права доступа тоже лучше разводить сразу. Разработчикам чаще нужен технический контекст: ID запроса, модель, время, код ошибки, длина текста и хеш. ИБ и внутреннему аудиту могут понадобиться основания доступа к полному архиву, история просмотров и отметка, кто именно открывал запись. Один общий доступ для всех почти всегда создает лишний риск.
Есть простое правило, которое хорошо работает на практике: каждый просмотр полного текста должен оставлять отдельный след. Кто открыл запись, зачем, по какому инциденту или заявке и на какой срок выдан доступ. Без этого спор быстро смещается с инцидента на сам факт просмотра данных.
Если часть цепочки идет через RU LLM, на уровне шлюза уже есть хранение логов и бэкапов в РФ, маскирование PII, метки AI-Law и аудит-трейлы по каждому запросу. Это не отменяет внутренние правила банка по срокам хранения и доступу, но заметно сокращает объем ручной доработки.
Как собрать схему логов по шагам
Если каждый сервис пишет логи по-своему, аудит быстро упирается в ручную сверку. Один сервис хранит model_name, другой model, третий пишет только текст ошибки. Через месяц никто уже не скажет, где запрос сменил модель, кто сделал ретрай и почему ответ отклонили.
Практичнее начать с одного JSON-документа для всего пути запроса. У полей должны быть фиксированные имена, типы и статус обязательности. Для банка обычно хватает пяти шагов.
- Опишите базовую схему. В ней обычно нужны
request_id,session_id,tenant_id,actor_type,policy_id,model_id,provider_id, временные метки и статус шага. Если сервис не знает поле, пусть передаетnull, а не придумывает свой вариант. - Соберите справочники. Отдельно зафиксируйте коды ошибок, список моделей, причины отказа и
policy_id. Тогдаtimeout,provider_timeoutиt/oне превратятся в три разные проблемы. - Протяните
request_idчерез весь путь. Приложение, API-шлюз, сервис маскирования PII, маршрутизатор, кеш, модерация и вызов модели должны писать один и тот же идентификатор. - Добавьте автоматическую проверку качества логов. Система должна ловить пропуски обязательных полей, неверные типы, пустые
error_codeи неожиданныеmodel_id. - Прогоните три сценария: обычный успешный запрос, отказ по политике и ретрай после ошибки провайдера. После теста команда безопасности и внутренний аудит должны без устных пояснений восстановить всю цепочку событий.
Признак нормальной схемы простой: аналитик открывает логи по одному request_id и за пару минут видит вход, промежуточные шаги, итог и причину отклонения. Если для этого нужно сводить пять таблиц вручную, схема еще сырая.
Где команды чаще ошибаются
Самая частая ошибка - хранить только промпт и ответ. Для разбора инцидента этого мало. Без маршрута запроса никто не докажет, какая модель отвечала, через какого провайдера ушел вызов, был ли fallback и менялся ли путь после ретрая.
Вторая проблема - отсутствие общего request_id или trace_id у чата, оркестратора, шлюза, retrieval и постобработки. Тогда аудит видит набор отдельных записей, а не один проверяемый запрос.
Еще один частый сбой связан с версиями. Команда меняет system prompt, правила маскирования или блок инструкций для RAG, но не пишет их версию. Через неделю ответ уже другой, а сравнить нечего. В логе должны жить prompt_template_version, policy_version и версия пайплайна. Иначе расследование быстро превращается в спор по памяти.
Команды часто смешивают и сами типы журналов. Аудит фиксирует факт, маршрут, исполнителя, время и итог. Debug помогает инженеру понять сбой. Продуктовая аналитика считает использование и поведение пользователей. Когда все это сваливают в один поток, журнал разрастается, в нем появляются лишние поля, а доступ получают люди, которым не нужен полный след.
Отдельная боль - время. Один сервис пишет UTC, другой локальное время сервера, третий время браузера оператора. В итоге события идут будто в обратном порядке. Лучше выбрать один стандарт для всех систем, обычно UTC, и уже в интерфейсе показывать локальное время.
И наконец, команды часто теряют след на границе внешнего шлюза и внутренних сервисов. Если этот переход не связан общим идентификатором, внутренний аудит видит только факт обращения к LLM, но не весь путь запроса от экрана сотрудника до модели и обратно.
Пример из банковского сценария
Оператор контактного центра получает обращение по спорной комиссии и просит LLM подготовить короткую сводку: что уже обещали клиенту, какие документы есть в деле и какой ответ можно дать сейчас. Если позже клиент подаст жалобу, банку мало сохранить только финальный текст. Нужна полная цепочка событий по одному trace_id.
Сначала шлюз принимает запрос, привязывает его к case_id, operator_id и trace_id, а затем маскирует телефон, номер договора и другие PII. В журнал попадает не сам паспорт или телефон, а факт маскирования: какие типы данных нашли, чем заменили и какая политика сработала.
Дальше система выбирает разрешенную модель из белого списка. В логе должны сразу появиться модель, провайдер, версия, контур обработки и причина выбора маршрута. После этого retrieval подтягивает регламент по спорным комиссиям и историю обращения клиента. В аудит лучше писать не полный текст документов, а их ID, версию, источник и хеш фрагментов, которые попали в контекст.
Потом модель предлагает фразу с обещанием вернуть комиссию в тот же день, хотя по внутренней политике оператор не может этого гарантировать до ручной проверки. Фильтр блокирует этот кусок, записывает rule_id, причину блокировки и действие системы, например regenerate или refuse. Следующая версия ответа уже безопаснее: заявка передана на проверку, срок ответа - до пяти рабочих дней.
Когда внутренний аудит открывает этот trace_id, он должен сразу видеть, кто отправил запрос, какие PII система скрыла на входе, какую модель разрешил шлюз, какие документы retrieval добавил в контекст и какой фильтр остановил рискованную формулировку. Такой след обычно закрывает спор за несколько минут.
Быстрая проверка перед запуском
Перед первым боевым трафиком прогоните несколько тестовых запросов и проверьте логи руками, а не по схеме на бумаге. Если команда безопасности не может за минуту восстановить путь одного запроса, журнал еще не готов.
Смотрите один запрос целиком: от входа до ответа, ошибки или блокировки. В нем должны читаться request_id и trace_id, фактическая модель и провайдер, версия промпта, сработавшая политика маскирования, все ретраи и блокировки, а также история просмотров полного лога. Если часть этой картины лежит в другом месте и собирается только вручную, на прод лучше пока не идти.
Хороший тест очень простой: дайте внутреннему аудитору один request_id и попросите за пять минут ответить на четыре вопроса. Кто отправил запрос. Что с ним случилось. Почему система приняла именно такое решение. Кто потом открывал эту запись. Если хотя бы один ответ требует догадок, запуск лучше отложить.
Что делать дальше
Не пытайтесь сразу покрыть весь банк. Возьмите один живой сценарий, где LLM уже приносит пользу и риск понятен команде. Например, разбор обращений в контакт-центре или черновик ответа оператору. Для пилота достаточно минимального набора событий: вход запроса, шаги обработки, выбор модели, ответ, ошибка и ручное вмешательство.
Потом соберите одну короткую встречу с ИБ, внутренним аудитом и владельцем продукта. Покажите не презентацию, а схему одного request_id от входа до результата: что система получила, что скрыла, куда отправила запрос, какую модель вызвала, сколько токенов ушло, что вернулось и кто потом открыл лог. Когда все смотрят на один и тот же след, споров о трактовках становится заметно меньше.
После этого договоритесь о базовых правилах: где лежат логи и резервные копии, кто видит сырые промпты и ответы, какие поля можно хранить только в маске или хеше, как удаляются или архивируются записи и кто имеет право выгружать аудит-трейл. Банки чаще ошибаются не в самом факте логирования, а в том, что сырые данные начинают копиться сразу в нескольких местах: в приложении, очередях, прокси, аналитике и бэкапах.
Если часть LLM-инфраструктуры уже идет через RU LLM, полезно сверить свой минимальный набор полей с тем, что шлюз фиксирует сам: маршрут, провайдера, метки AI-Law, маскирование PII и аудит по каждому запросу. Это помогает убрать дубли между приложением, прокси и аналитикой.
Когда пилот спокойно проживет две-три недели, не останавливайтесь на журнале событий. Добавьте к тем же request_id оценку качества и контроль затрат. Тогда у вас появится один общий след для ИБ, аудита, ML-команды и бизнеса: не только что произошло, но и сколько это стоило, какой ответ дала модель и где процесс реально ломается.
Часто задаваемые вопросы
Что считать одним запросом в LLM-аудите?
Считайте одним запросом одно действие пользователя или один шаг процесса. Если внутри система сделала поиск, вызов инструмента, ретрай и fallback, это все равно один запрос, пока пользователь не сделал новое действие.
Зачем нужны session_id, request_id и span_id?
Обычно хватает трех уровней: session_id для всей сессии, request_id или trace_id для одного запроса и span_id для шагов внутри него. Если один шаг запускает другой, сразу пишите parent_span_id, чтобы потом не собирать цепочку вручную.
Что логировать в самом начале запроса?
На старте запроса сохраните request_id, точное время, источник, сценарий и того, кто запустил действие. Если уже известны версия шаблона, policy_id, класс данных и требование об обработке в РФ, запишите это сразу, чтобы потом не спорить, почему система выбрала такой маршрут.
Что важно записывать во время обработки запроса?
Во время обработки пишите не только входные данные, но и фактические решения системы. Полезно сохранять effective_model, провайдера, base_url, правило маршрутизации, причину выбора, события кеша, обращения к retrieval и внешним системам, а также факт маскирования PII и срабатывания проверок.
Какие поля нужны для retrieval и tool calls?
Не ограничивайтесь только document_id. Сохраняйте index_id, версию эмбеддингов, порог отбора, external_system_id, длительность шага, код результата и причину повтора, если система запускала его еще раз.
Что фиксировать при успешном ответе модели?
Для успешного ответа запишите время завершения, общую задержку, разбор задержки по этапам, токены, finish_reason и код ответа API. Если после модели система скрыла часть текста, заблокировала ответ или отправила диалог человеку, оформите это как отдельное событие с причиной и rule_id.
Что сохранять, если запрос завершился ошибкой или блокировкой?
При ошибке сохраните не только код, но и место сбоя: клиент, шлюз, провайдер, фильтр или бизнес-логика. Если проверка что-то остановила, пишите версию правил, решение вроде allow, redact, block или review, а для разбора привязывайте incident_id или номер тикета.
Как логировать запросы без лишних персональных данных?
Да, и обычно так даже лучше. По умолчанию храните хеш текста, короткий фрагмент без чувствительных данных и ссылку на защищенный архив, где полный материал лежит по отдельным правилам доступа. Маскируйте PII до отправки события в общий лог, иначе сырые данные быстро разойдутся по другим системам.
Что дает для аудита единый шлюз вроде RU LLM?
Единый шлюз упрощает трассировку, если он тянет один trace_id через маршрутизацию, ретраи и вызовы к разным провайдерам. В случае RU LLM это еще помогает держать логи и бэкапы в РФ, применять маскирование PII и собирать аудит по одному OpenAI-совместимому эндпоинту без смены SDK и клиентского кода.
С чего начать, если нормального аудит-трейла еще нет?
Возьмите один живой сценарий и проверьте его руками от входа до ответа. Если аудитор по одному request_id за несколько минут понимает, кто отправил запрос, что система сделала, почему она так решила и кто потом открывал запись, значит база уже рабочая. Если нет, сначала выровняйте схему полей и общий идентификатор во всех сервисах.