Атрибуция расходов по LLM-запросам: пользователь, фича, A/B-тест
Атрибуция расходов по LLM-запросам помогает понять, кто тратит токены, какая фича дороже и как A/B-тест меняет бюджет.
Где теряются деньги
Деньги обычно теряются не в тарифе модели, а в слепой зоне между запросом, логом и отчетом. Счет растет, токены списываются, а источник расхода не виден. Команда видит общую сумму за месяц, но не понимает, кто именно ее создал: конкретный пользователь, новая фича или неудачный эксперимент.
Проблема быстро становится заметной, когда одна и та же модель работает сразу в нескольких частях продукта. Один endpoint может отвечать в чате поддержки, помогать менеджерам в CRM и генерировать тексты в личном кабинете. Если все эти вызовы попадают в один поток, финансы видят только расход по модели, а продуктовые команды спорят, чей это бюджет.
Если компания идет через единый OpenAI-совместимый шлюз, путаницы часто еще больше. Один адрес скрывает много моделей и провайдеров, поэтому по одному названию модели уже трудно понять, какой сценарий сжег токены и зачем.
A/B-тесты добавляют еще один слой путаницы. Вариант A может просить короткий ответ на 150 токенов, а вариант B - длинный ответ с расширенным системным промптом и лимитом в 800 токенов. В интерфейсе разница кажется небольшой, а в расходах она становится заметной уже через пару дней.
Чаще всего деньги утекают в четырех местах:
- запрос не помечен пользователем или аккаунтом;
- у фичи нет стабильного имени в логах;
- эксперимент записан без варианта, только общим названием;
- нет
request_id, и лог нельзя сверить с биллингом.
Последний пункт часто недооценивают. Без request_id нельзя связать три вещи: событие в приложении, запись в LLM-шлюзе и строку в финансовом отчете. Тогда любая проверка превращается в ручной разбор: кто отправил запрос, почему ответ оказался длинным и на каком этапе выросла стоимость.
Простой пример: в чате поддержки вырос средний чек на диалог. Если у вас нет request_id и меток по фиче, вы не поймете, что случилось. Причиной может быть новая версия промпта, длинные ответы в варианте B или один крупный клиент, который резко поднял нагрузку.
Нормальная атрибуция начинается не с красивого дашборда. Она начинается с дисциплины в каждом вызове: кто отправил запрос, из какой фичи, в рамках какого теста и как этот вызов потом найти в логах и оплате.
Какие поля передавать в каждом запросе
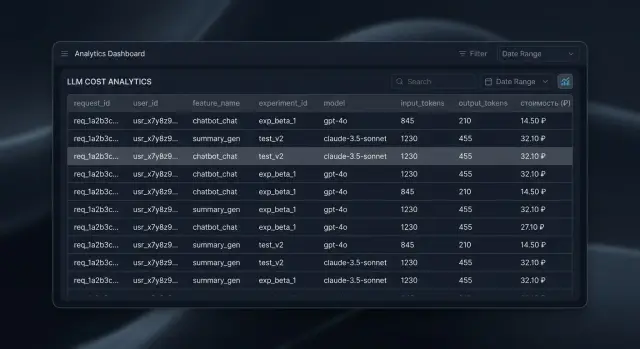
Если в логах есть только текст промпта, токены и модель, вы увидите общий счет, но не поймете, кто и на что его создал. Для нормальной атрибуции нужен короткий, но строгий набор полей, который команда пишет в каждый вызов без исключений.
Сначала заведите request_id. Он должен быть уникальным для каждой попытки, а не только для пользовательского действия. Если клиент нажал кнопку один раз, а ваш код сделал три ретрая, это три разных request_id. Иначе вы смешаете стоимость, задержку и ошибки в одну запись и потеряете реальную картину.
Дальше нужен идентификатор того, кому вы потом спишете расход: user_id или account_id. Не пишите ФИО, email, телефон и другие персональные данные. Для финансовой аналитики достаточно внутреннего ID. Так вы сохраните точность учета и не превратите логи в лишний риск для комплаенса.
Отдельно фиксируйте feature_name. Это имя экрана, сценария или функции продукта, где возник запрос. Лучше брать простое и стабильное значение: support_chat, search_copilot, draft_reply. Если команда сегодня пишет чат поддержки, завтра support, а через неделю support-v2, отчеты быстро ломаются.
Для экспериментов добавляйте experiment_id и variant. Без этой пары A/B-тест почти всегда врет по деньгам. Конверсия может вырасти, и расход на один успешный сценарий вырастет тоже. Когда эти поля есть в каждом запросе, сразу видно, какой вариант дороже, где растет длина ответа и какой тест съедает бюджет.
Еще одна группа полей нужна для самой цены запроса: model, input_tokens, output_tokens и время ответа. По ним вы считаете стоимость, среднюю задержку и находите перекосы. Одна и та же функция может быть дешевой на коротких входах и очень дорогой на длинных диалогах.
Минимальный набор обычно такой:
request_id;user_idилиaccount_id;feature_name;experiment_idиvariant, если идет тест;model, токены иlatency_ms.
Если вы работаете через единый OpenAI-совместимый шлюз вроде RU LLM, эти поля удобно передавать как метаданные рядом с запросом. Тогда прикладную логику почти не нужно трогать, а учет по пользователю, фиче и тесту появляется уже в первом отчете.
Есть одно простое правило: все поля должны появляться в момент запроса, а не достраиваться потом из разных таблиц. Постфактум почти всегда теряются ретраи, варианты теста и часть токенов.
Как настроить атрибуцию шаг за шагом
Атрибуция ломается не на расчетах, а на схеме данных. Если сегодня один сервис пишет user_id, другой uid, а третий вообще ничего не пишет, через неделю отчет уже нельзя сверить ни с продуктом, ни с финансами. Поэтому сначала зафиксируйте один формат события и не давайте командам придумывать свои версии.
Для старта хватает пяти шагов:
- описать одно сырое событие для каждого вызова модели;
- передавать атрибуты из бекенда, где им можно доверять;
- сохранять цену и тариф модели в момент запроса;
- писать каждый ретрай отдельной строкой;
- собирать агрегаты из сырых событий по часу и по дню.
Лучше начать с сырых событий, а не с дашборда. Каждое событие должно жить само по себе: кто вызвал модель, какая функция продукта это сделала, в какой эксперимент входил запрос, сколько токенов ушло и по какой цене вы потом считаете расход. Если чего-то нет в сыром логе, потом это уже не восстановить.
Поля для атрибуции передавайте из бекенда. Клиентский код легко ломается: мобильное приложение может не дослать вариант эксперимента, браузерный фронт может потерять идентификатор пользователя, а злоумышленник может подменить метки. Бекенд обычно уже знает пользователя, tenant, feature flag и контекст A/B-теста. Значит, он и должен ставить эти значения перед вызовом модели.
Где команды чаще всего ошибаются
Частая ошибка - считать стоимость по текущему прайсу модели, а не по прайсу на момент вызова. Это дает тихую, но неприятную ошибку в отчетах, особенно если провайдер меняет ставки или вы переключаете маршрутизацию между моделями. Сохраняйте снимок цены прямо в событии: цена за входные токены, цена за выходные токены, валюта, провайдер и модель.
С ретраями нужна отдельная дисциплина. Не затирайте первый запрос вторым и не складывайте их в одну запись. Иначе вы не увидите, что один пользовательский ответ стоил вдвое дороже из-за двух повторов. Проще писать retry_of или другой указатель на исходный вызов и считать такие расходы отдельно.
После этого стройте не один общий отчет, а два слоя. Первый слой - сырые события без правок. Второй - почасовая и дневная сводка, где стоимость уже разнесена по пользователю, функции и тесту. Если вы работаете через шлюз вроде RU LLM, этот подход особенно удобен: маршрутизация может меняться, а схема учета остается одной и той же.
Как считать стоимость без путаницы
Стоимость одного запроса обычно ломают две ошибки: все токены складывают в одну кучу и берут одну цену на весь путь запроса. В самом начале так считать удобно. Потом отчеты перестают сходиться, а команды спорят, кто именно сжег бюджет.
Держите расчет на уровне факта запроса. Для каждой записи храните отдельно input_tokens и output_tokens, потому что у многих моделей цена на вход и выход разная. Если есть prompt caching, cached_tokens тоже пишите отдельным полем. Иначе вы не поймете, где у вас правда вырос расход, а где просто хорошо сработал кэш.
Базовая формула выглядит так:
- стоимость входа =
input_tokensx ставка за вход; - стоимость выхода =
output_tokensx ставка за выход; - стоимость кэша =
cached_tokensx ставка cached input; - стоимость фолбэка = отдельный расчет по той модели, на которую ушел запрос;
- итог = сумма всех частей в одной валюте отчета.
Особенно часто путают цену модели и внутренний лимит команды. Цена модели - это внешний факт: сколько стоит токен у провайдера или на вашей инфраструктуре. Лимит команды - это внутреннее правило, например 50 000 рублей в месяц на фичу поиска. Это разные вещи. Аналитик должен видеть и фактическую стоимость запроса, и то, как она соотносится с лимитом, но не подменять одно другим.
Еще одна частая ошибка - считать только успешный ответ и забывать про неудачные попытки. Таймаут, фолбэк на другую модель, повторный запрос после 429 - все это тоже деньги. Если вы учитываете только финальный успешный вызов, отчет всегда будет выглядеть чуть лучше, чем реальность.
Пример: чат поддержки с двумя вариантами
Представьте чат поддержки в личном кабинете банка. Команда тестирует два варианта ответов на одних и тех же вопросах: вариант "A" отвечает коротко и по делу, а вариант "B" пишет длиннее, добавляет пояснения и чаще предлагает следующий шаг. Оба потока должны входить в один experiment_id, иначе сравнение быстро ломается.
Если запросы идут через единый OpenAI-совместимый шлюз вроде RU LLM, теги удобно собирать в одном месте и потом разбирать в отчетах без ручной склейки. Для этого в каждый запрос достаточно передавать одни и те же поля:
{
"user_id": "u_48291",
"feature": "support_chat",
"experiment_id": "support_chat_v1",
"variant": "B"
}
Дальше появляется простая картина. За день вариант "A" обработал 12 000 сообщений и в среднем тратил 900 токенов на диалог. Вариант "B" обработал столько же, но уже 1450 токенов. Если считать деньги по фактическим ставкам модели, видно не ощущение, а расход: вариант "B" обходится, например, на 55-60% дороже только потому, что генерирует более длинные ответы.
На уровне variant это уже полезно, но user_id дает еще один слой. Часто самые дорогие диалоги создают не все пользователи, а маленькая группа. Один клиент пять раз переспрашивает про лимиты по карте. Другой копирует длинные фрагменты переписки. Третий открывает чат каждый раз, когда не находит выписку в интерфейсе. В отчете это видно сразу: 4% пользователей могут давать четверть всех расходов на чат.
Тогда команда смотрит на три среза:
- сколько стоит фича
support_chatцеликом; - какой
variantтратит больше токенов; - какие
user_idсоздают самые дорогие цепочки сообщений.
Из такого примера обычно следуют вполне земные решения. Для варианта "B" можно ограничить длину ответа, оставить подробный режим только для части тем и убрать лишние повторения. Для дорогих пользователей стоит проверить не модель, а сам путь в продукте: если люди массово приходят в чат из-за одной и той же путаницы в интерфейсе, дешевле исправить экран, чем оплачивать длинные диалоги каждый день.
Как разнести расход по трем измерениям
Путаница начинается не в расчете токенов, а в учете ответственности. Если у фичи нет владельца, расходы быстро слипаются в одну строку, и потом никто не понимает, кто поднял счет. Поэтому у каждой LLM-фичи должен быть свой feature_id и команда или менеджер, которые отвечают за бюджет.
В событии каждого запроса держите один и тот же набор полей:
feature_id;feature_owner;user_id;experiment_id;variant.
Этого уже хватает, чтобы собрать понятный отчет. Сначала вы видите, какая фича тратит больше всего. Потом внутри этой фичи можно сложить стоимость по каждому user_id и понять, кто реально создает нагрузку: один крупный клиент, новая группа пользователей или внутренняя команда тестирования.
experiment_id и variant должны жить рядом в той же записи, где лежат токены и итоговая цена. Не выносите вариант теста в отдельный лог и не пытайтесь потом склеить данные по времени. Такие склейки почти всегда ломаются на ретраях, очередях и фоновых вызовах. Если запрос ушел в вариант B, это должно быть видно сразу в строке расхода.
Сложнее всего с запросами, которые обслуживают две фичи сразу. Например, один вызов модели и отвечает пользователю, и сохраняет краткое резюме разговора для CRM. Тут не стоит придумывать новую логику каждый месяц. Выберите одно правило и не меняйте его без причины. Самый простой вариант - относить 100% расхода на ту фичу, которая инициировала запрос. Если этого мало, задайте фиксированное деление, например 70/30, и храните его в конфиге, а не в головах команды.
Для фоновых задач не оставляйте user_id пустым. Иначе ночные джобы, индексация, ретраи и автосводки попадут в отчеты по обычным людям или потеряются совсем. Лучше завести отдельного system_user, например system_user:nightly_sync или system_user:summary_job.
Такая схема хорошо работает и в обычном приложении, и через API-шлюз вроде RU LLM, где важен полный audit trail по каждому запросу. Когда фича, пользователь и тест лежат в одной записи, спор о расходах обычно решает один SQL-запрос, а не неделя ручной сверки логов.
Частые ошибки в логах и отчетах
Больше всего денег теряется не в модели, а в учете. Один и тот же запрос проходит через продукт, ретрай, фолбэк и отчет, а на каждом шаге часть полей теряется или меняется. После этого атрибуция выглядит аккуратно только на дашборде, но не отвечает на простой вопрос: кто потратил деньги и на что.
Частая проблема - разный нейминг одной функции. Сегодня команда пишет chat, завтра support_chat, потом support-chat. В отчете это уже три разные фичи, хотя деньги ушли в один сценарий. Лучше один раз завести справочник значений и не давать сервисам отправлять произвольные строки. Если имя фичи не прошло проверку, запрос должен падать сразу, а не попадать в лог как есть.
Не менее неприятная ошибка - потеря experiment_id на ретраях и фолбэках. Запрос стартовал в варианте B, словил таймаут, ушел на другую модель и внезапно стал "без эксперимента". Потом команда видит, что вариант B дешевле, хотя часть его расходов лежит в категории unknown. Один корневой набор атрибутов нужно создавать в самом начале запроса и передавать дальше без изменений, даже если меняется модель или провайдер. Это особенно важно, когда вы маршрутизируете вызовы через единый API-шлюз и часть логики живет вне приложения.
Еще одна типичная ошибка - старая цена в коде. Разработчик сменил модель, а расчет оставил прежний. Или заменил провайдера, но продолжил умножать токены на старый тариф. Так появляются точные на вид отчеты с неверной суммой. Цена должна приходить из того же источника, где вы берете факт использования: модель, провайдер, входные и выходные токены, время запроса и тариф на этот момент.
С request_id команды тоже часто ошибаются. Если один идентификатор используют повторно, вы теряете границы между событиями. Два разных ответа могут схлопнуться в один, а один запрос может случайно получить чужую стоимость. request_id должен быть уникальным для каждого вызова. Если есть ретраи, добавьте отдельный trace_id для всей цепочки и храните оба поля.
И последняя ошибка выглядит безобидно, но создает лишний риск: в отчет тащат телефон и email, хотя для разреза по пользователю хватает user_id. Для финансовой аналитики почти никогда не нужны прямые персональные данные. В системах с требованиями 152-ФЗ это еще и лишняя головная боль. Держите в отчетах только то, что помогает считать расход, а не то, по чему удобно узнать человека.
Минимальный набор правил простой:
- одно каноническое имя на каждую фичу;
- неизменные атрибуты на всей цепочке запроса;
- цена из факта биллинга, а не из кода;
- уникальный
request_idна каждый вызов; user_idвместо телефона и email.
Если хотя бы один пункт нарушен, цифры в отчете быстро перестают сходиться с реальными расходами.
Проверка перед запуском
Перед релизом лучше потратить час на сверку логов, чем потом спорить, куда ушел бюджет. Если атрибуция настроена правильно, любой LLM-вызов можно найти, понять и отнести к конкретному пользователю, функции и варианту эксперимента.
Минимальный набор проверок такой:
- у каждого вызова есть
request_idи точныйtimestamp; - в каждом событии заполнены
user_id,feature_nameиvariant; - ретраи и фолбэки не смешаны с исходным вызовом;
- команда может вручную поднять 10 случайных запросов и пересчитать их;
- сумма в отчете сходится со счетом за тот же период.
request_id нужен не для красоты. Без него вы не свяжете пользовательское действие, запрос к модели, повторную попытку и финальную стоимость. timestamp тоже должен быть нормальным, с одной таймзоной и без округления до минут. Иначе расход по дням и тестам начнет плавать, особенно на стыке суток и отчетных периодов.
Поля user_id, feature_name и variant лучше считать обязательными. Если хотя бы одно поле пустое, такой вызов стоит пометить отдельно и не прятать в общую сумму. Иначе отчет по фиче покажет одно, а продуктовая команда увидит другое.
С ретраями и фолбэками путаница случается чаще всего. Первый запрос, повтор после таймаута и уход на запасную модель нельзя хранить как один и тот же вызов. У них должна быть явная связь, но разный статус и отдельная стоимость. Тогда вы увидите, что дорожает: сама фича, нестабильный провайдер или слишком агрессивная логика повторов.
Полезная привычка - раз в неделю брать 10 случайных запросов и проходить их руками. Откройте событие продукта, лог маршрутизации, число входных и выходных токенов, цену модели и итоговую сумму. Такой ручной тест быстро ловит пропавший variant, двойной retry и неверный курс пересчета.
Последняя проверка самая простая и самая жесткая: итог по отчету должен сходиться со счетом за период. Если вы работаете через RU LLM, сравните агрегат по логам со счетом за те же даты. Расхождение на копейки из-за округления допустимо. Все остальное уже не мелочь, а ошибка учета.
Что делать дальше
Не раскатывайте атрибуцию на весь продукт сразу. Она приносит пользу, когда вы быстро видите разницу между ожиданием и фактом. Для этого достаточно одной дорогой фичи, где много трафика или длинные ответы модели.
Хороший первый кандидат - чат поддержки, генерация писем или автосуммаризация звонков. Выберите место, где команда уже спорит о цене, задержке или лимитах. Тогда данные пригодятся в первую же неделю.
Порядок запуска может быть таким:
- возьмите одну фичу и начните писать в каждый запрос
user_id,feature_nameиrequest_id; - добавьте
experiment_id, даже если A/B-тест еще не запущен; - сверяйте раз в день токены, число запросов и деньги по провайдеру с внутренним отчетом;
- через 7 дней сравните фактический расход с плановым лимитом по этой фиче;
- только потом подключайте A/B-тесты, фоновые джобы и пакетные сценарии.
Такой порядок спасает от хаоса. Если начать сразу со всего, вы получите красивую таблицу, которой никто не верит. Если начать с одной фичи, можно вручную проверить 20-30 запросов, найти пропущенные поля и понять, почему стоимость выше плана: из-за длинного контекста, повторных ретраев или слишком дорогой модели.
Если вы уже шлете трафик через OpenAI-совместимый endpoint, не ломайте текущую интеграцию. Обычно достаточно сохранить те же SDK, тот же код вызова и добавить поля атрибуции в metadata или в журнал на своей стороне. Это заметно сокращает срок запуска.
Для команд, у которых трафик и требования по данным находятся внутри РФ, такую схему удобно собирать вокруг RU LLM и rullm.com: единый совместимый endpoint, биллинг в рублях и хранение логов внутри российского контура. Это упрощает сверку расходов по пользователю, фиче и эксперименту без отдельного слоя скриптов и ручных выгрузок.
Если через неделю цифры сходятся хотя бы по одной фиче, у вас уже есть рабочая основа. После этого можно добавлять лимиты, алерты и правила маршрутизации моделей уже не вслепую, а по реальным расходам.
Часто задаваемые вопросы
Зачем вообще нужен request_id?
Он связывает одно событие в продукте, запись в LLM-шлюзе и строку в отчете. Без него вы видите общий расход, но не находите конкретный запрос. Для каждого вызова нужен свой request_id, а для цепочки ретраев полезно держать еще и trace_id.
Какие поля стоит передавать в каждом LLM-запросе?
Обычно хватает request_id, user_id или account_id, feature_name, model, input_tokens, output_tokens и latency_ms. Если идет тест, сразу добавляйте experiment_id и variant. Такой набор уже позволяет понять, кто создал расход, где именно и почему он вырос.
Можно ли использовать email или телефон вместо user_id?
Нет, для учета расходов email и телефон не нужны. Берите внутренний user_id или account_id, и этого достаточно для аналитики. Так вы не тащите лишние персональные данные в логи и снижаете риск для комплаенса.
Почему атрибуцию лучше ставить на бекенде, а не на клиенте?
Потому что бекенд уже знает пользователя, tenant, feature flag и вариант теста. Фронт легко теряет эти данные или отправляет их в разном виде. Если метки ставит бекенд, отчеты получаются чище, а подменить атрибуты заметно сложнее.
Как учитывать ретраи и фолбэки без путаницы?
Не склеивайте их в одну запись. Каждый повторный вызов и каждый фолбэк пишите отдельной строкой с собственной стоимостью, а связь с исходным запросом храните в поле вроде retry_of или через общий trace_id. Иначе вы занизите реальные расходы и не поймете, где именно утекают деньги.
Как правильно считать стоимость одного запроса?
Считайте входные и выходные токены раздельно, потому что ставка часто отличается. Если у вас есть prompt caching, cached_tokens тоже храните отдельно. Цена должна браться из факта вызова в тот момент, а не из старого тарифа в коде.
Что обязательно логировать для A/B-теста?
Передавайте experiment_id и variant в каждом вызове, а не только в продуктовой аналитике. Тогда вы увидите не только конверсию, но и цену каждого варианта. На практике один вариант часто выглядит лучше в интерфейсе, но съедает больше токенов из-за длинных ответов или большого системного промпта.
Что делать, если один запрос обслуживает сразу две функции продукта?
Лучше выбрать одно правило заранее и не менять его каждый месяц. Самый простой вариант — относить весь расход на фичу, которая инициировала вызов. Если этого мало, задайте фиксированное деление, например 70/30, и храните его в конфиге.
Как проверить, что отчет по расходам считает правильно?
Возьмите небольшой период и сравните сумму по сырым логам со счетом за те же даты. Потом вручную проверьте несколько случайных запросов: request_id, токены, модель, цену и итоговую сумму. Если цифры не сходятся, ошибка почти всегда сидит в потерянных атрибутах, ретраях или старом тарифе.
С чего начать внедрение атрибуции, чтобы не утонуть в хаосе?
Начните с одной дорогой фичи, где уже много трафика или длинные ответы. Добавьте в каждый вызов request_id, user_id и feature_name, а затем несколько дней сверяйте токены и деньги с внутренним отчетом. Если вы идете через OpenAI-совместимый шлюз вроде RU LLM, эти поля удобно передавать в метаданных без переделки SDK и основного кода.