Ассистент для внутренней базы банка: архитектура без утечки
Ассистент для внутренней базы банка требует поиска по документам, маскирования ПДн и журнала действий. Разберем схему, роли и контроль.
В чем риск для банка
Обычный чат с моделью банку не подходит. Он не знает внутренние роли, не различает служебную необходимость и простой интерес и принимает любой вставленный текст как обычный запрос. Если сотрудник копирует в чат анкету клиента, выписку, паспортные данные или номер договора, эти данные сразу выходят из защищенного сценария.
Риск возникает не только в момент отправки вопроса. Персональные данные попадают в систему с трех сторон: из текста запроса, из найденных документов и из ответа модели. Простой пример: сотрудник пишет "проверь клиента по просрочке" и добавляет ФИО с датой рождения. Поиск поднимает кредитное досье, обращение в поддержку и скан заявления. Потом модель собирает ответ и может показать лишнее: полный номер счета, адрес, телефон, историю блокировок.
Если банк делает ассистента для внутренней базы без проверки прав, он сам создает обход обычных ограничений. В АБС, CRM и архиве доступ уже разделен по ролям. Оператор контакт-центра видит одно, служба безопасности - другое, юристы - третье. Чат стирает эту границу очень быстро, если система сначала ищет и генерирует ответ, а права проверяет потом или не проверяет вовсе.
Есть и менее заметный риск. Сотрудник может не хотеть ничего плохого, но задать слишком широкий вопрос и получить слишком широкий ответ. Один абзац с лишними деталями легко уходит в тикет, письмо или внутренний мессенджер. После этого источник утечки уже трудно отследить.
Без журнала действий спорные случаи почти не разобрать. Когда клиент жалуется или служба ИБ поднимает инцидент, банку нужно видеть всю цепочку: кто задал запрос, под какой ролью, какие документы поднял поиск, что система скрыла и какой ответ получил сотрудник. Иначе непонятно, модель сама добавила лишнее, поиск вернул сырой документ или сотрудник увидел данные по чужой роли.
Этого уже достаточно, чтобы отказаться от "обычного чата". Банку нужен отдельный контур, где запрос проходит через поиск, маскирование, проверку роли и аудит, а логи и обработка данных остаются в контролируемой среде внутри РФ.
Из каких слоев собрать систему
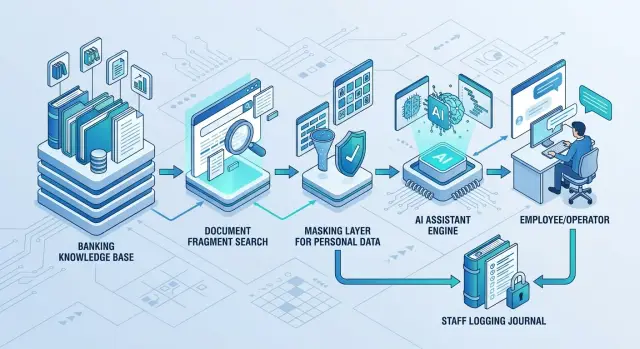
Внутренний ассистент не должен ходить в документы напрямую и тем более отправлять в модель все подряд. Нормальная схема делит систему на несколько слоев: хранение, доступ, поиск, маскирование, вызов модели и журнал действий. Тогда каждый слой отвечает за свою задачу, а один сбой не ломает всю защиту.
На практике нужны пять частей: хранилище документов с матрицей прав, поисковый индекс с метками отдела, типа документа и версии, слой маскирования до вызова модели, LLM-шлюз для маршрутизации запросов и аудита, а также строгий интерфейс сотрудника.
Хранилище документов лучше держать отдельно от модели. В нем лежат регламенты, инструкции, тарифные правила, шаблоны ответов, записи базы знаний и другие тексты, которые банк готов показывать сотрудникам по ролям. Рядом нужна матрица прав. Если доступ не проверять до поиска, дальше уже поздно.
Поисковый индекс строят не только по тексту. В него добавляют метки отдела, продукта, типа документа, даты публикации и версии. Это решает частую проблему: сотрудник находит старую инструкцию и действует по ней. Если индекс знает, что документ устарел или заменен новой редакцией, ассистент поднимет свежий вариант и сможет показать номер версии в ответе.
Слой маскирования ставят перед моделью, а не после нее. Он убирает или заменяет ФИО, номера счетов, телефоны, паспортные данные, адреса и другие поля, которые не нужны для смысла вопроса. Если менеджер спрашивает, почему заявка клиента ушла на ручную проверку, модели обычно хватает текста вроде "клиент_1" и "счет_1". Для ответа этого достаточно, а риск заметно ниже.
Дальше работает LLM-шлюз. Он принимает запрос, выбирает модель, пишет audit trail и сохраняет технический след по каждому вызову. Для банка это удобнее, чем подключать модели по отдельности. Интерфейс сотрудника при этом должен быть простым и строгим. Полезно ограничить длину запроса, запретить вставку больших выгрузок, скрыть системные промпты и отключить свободную загрузку файлов для ролей, которым это не нужно. Еще один полезный барьер - показывать, на каких документах основан ответ, и давать кнопку "открыть источник" только тем, у кого есть доступ.
Такой разбор по слоям кажется скучным, но именно он работает. Поиск не должен решать права доступа, модель не должна решать маскирование, а интерфейс не должен заменять аудит.
Как проходит запрос сотрудника
Хороший ассистент не должен сразу отправлять вопрос в модель. Сначала система проверяет, кто именно обратился, из какого он отдела и зачем ему нужен ответ. Для банка обычной проверки доступа мало. Нужен еще контекст цели запроса, чтобы сотрудник колл-центра не получил данные, которые допустимы только для службы безопасности или комплаенса.
Обычно поток запроса выглядит так:
- Сотрудник задает вопрос через внутренний интерфейс, а система берет его роль из SSO, подразделение из HR-справочника и цель из формы запроса или шаблона задачи.
- Поиск идет не по всей базе сразу, а только по тем документам и фрагментам, где права доступа совпадают с ролью сотрудника. Если на документе стоит метка "только для юристов" или "персональные данные", поиск это учитывает.
- Перед вызовом модели сервис очищает найденный контекст. Он скрывает ФИО, номера счетов, телефоны, паспортные данные и другие поля, которые не нужны для ответа по сути.
- В модель уходит только очищенный текст, служебная инструкция и короткий системный промпт с границами ответа. Сырые документы и полные карточки клиента туда не попадают.
- После ответа система пишет в журнал, кто спрашивал, по какому маршруту прошел запрос, какие источники использовал поиск, что именно скрыли и какой ответ получил сотрудник.
Представим простой случай. Оператор спрашивает, можно ли принять заявление клиента на перевыпуск карты по доверенности. Поиск находит внутренний регламент, памятку фронт-линии и выдержку из юридического шаблона. Сервис закрывает данные конкретных клиентов, оставляет только правила и условия, а модель собирает короткий ответ по процедуре.
Главное правило здесь простое: сначала права и очистка, потом генерация ответа. Если поменять этот порядок, защита почти наверняка даст сбой.
Как настроить поиск по документам
Банковский ассистент ошибается не потому, что модель слабая, а потому, что поиск приносит ей слишком длинные, старые или лишние тексты. Если в индекс попадает весь регламент целиком, ответ цепляется за случайный абзац. Лучше делить документы на короткие смысловые фрагменты: раздел, пункт, приложение, таблицу с пояснением. Обычно хватает 300-800 слов на фрагмент с небольшим перекрытием между соседними частями.
Что хранить в индексе
Каждый фрагмент лучше сохранять вместе с полями, которые влияют на выдачу: названием документа, датой версии, подразделением-владельцем, типом документа и статусом версии. Без этих полей поиск легко путает инструкцию для фронт-офиса с регламентом комплаенса. Еще хуже, когда рядом лежат черновик и утвержденная редакция: ассистент берет черновик, а сотрудник уверен, что ответ правильный.
Поэтому перед индексацией стоит почистить корпус: убрать дубликаты, черновики, отмененные документы, пустые шаблоны и старые выгрузки из почты или файловых папок. После очистки настройте ранжирование. Сначала ищите по смыслу и по точным словам, потом пересортировывайте результаты с учетом служебных полей. Действующая версия должна подниматься выше архива. Документ нужного подразделения должен стоять выше общего справочного файла. Если запрос совпал с названием формы или номером инструкции, такой фрагмент тоже стоит поднимать вверх.
Сотруднику мало просто получить ответ. Он должен видеть, на что ответ опирается. Поэтому рядом с найденным фрагментом показывайте название документа, дату версии и, если нужно, раздел. Это заметно снижает число ошибок: человек сразу видит, что перед ним старая редакция или документ не того блока.
Простой пример: сотрудник спрашивает, как проверить доверенность представителя юрлица. Хорошо настроенный поиск поднимет утвержденный регламент юрдепартамента с последней датой версии, а не черновик из общей папки двухлетней давности. В таких задачах точность обычно решает не модель, а чистый индекс и нормальные метаданные.
Как скрыть персональные данные
Если модель видит сырые ФИО, телефоны, номера счетов и паспортные данные, риск утечки никуда не исчезает, даже когда ассистент работает только для сотрудников. Поэтому маскирование персональных данных ставят и перед поиском, и перед отправкой текста в модель. Потом ответ проверяют еще раз.
Одного способа почти никогда не хватает. Обычно банк ловит ПДн сразу несколькими правилами: шаблонами для телефонов, паспортов, ИНН, СНИЛС, счетов и карт, словарями по своим продуктам и формам, а также простыми моделями распознавания сущностей. Иначе часть данных просто проскочит, потому что в реальных тикетах и заявках все часто написано с пробелами, сокращениями, опечатками и внутренними пометками.
Подмена должна быть стабильной внутри одного диалога. Если в документе три раза встречается один и тот же человек, система везде ставит одну и ту же метку, например [КЛИЕНТ_1]. Для счета подойдет [СЧЕТ_1], для телефона - [ТЕЛЕФОН_1]. Тогда модель сохраняет смысл текста и может связать события между собой, но не видит исходные значения.
Таблицу подстановки нельзя класть в контекст модели, в промпт или в обычные логи. Ее держат в отдельном сервисе с коротким временем жизни, шифрованием и строгим доступом. Модель получает только обезличенный текст. Интерфейс сотрудника, если у него есть право видеть исходные данные, может вернуть их уже после генерации ответа.
Есть и обратная утечка. Модель иногда восстанавливает детали по соседним фразам или вытаскивает кусок из найденного документа, который не поймал первый фильтр. Поэтому финальный ответ снова прогоняют через те же детекторы и через ролевые правила доступа. Если менеджеру не нужен полный номер паспорта, система показывает только маску вроде "45 00 ******" или вообще блокирует этот фрагмент.
Еще один практичный момент - белый список служебных терминов, кодов и номеров правил. "Правило 7.3.4", код антифрода, номер внутреннего регламента или название формы отчетности не надо прятать как ПДн. Иначе поиск по внутренним документам начинает шуметь, а сотрудник получает ответ без опоры на реальные процедуры банка.
Что писать в журнал действий
Журнал нужен не для галочки. Он помогает понять, кто именно работал с данными клиента, что система показала сотруднику и в какой момент появился риск утечки. Если случится спор или проверка, по журналу можно восстановить цепочку действий почти поминутно.
Первый блок записей относится к самому доступу. Банк должен сохранять идентификатор сотрудника, время входа в диалог, рабочую роль и причину обращения. Причина не должна быть общей вроде "работа с клиентом". Лучше писать коротко и по делу: "проверка условий договора по обращению в офисе" или "подготовка ответа по спорной операции".
Дальше нужен след самого запроса. Обычно полезно хранить исходный запрос сотрудника, запрос после маскирования персональных данных, список документов и фрагментов, которые поиск вернул в контекст, модель, провайдера, параметры вызова, версию системного промпта и итоговый ответ, который увидел сотрудник.
Две версии запроса решают разные задачи. Исходный текст помогает расследовать ошибку оператора или попытку обойти правила. Версия после маскирования показывает, какие данные реально ушли в LLM-контур. Если между ними есть чувствительная разница, служба ИБ увидит это сразу.
Список найденных фрагментов тоже обязателен. Недостаточно записать "поиск выполнен". Нужны идентификаторы документов, куски текста, уровень доступа и оценка релевантности. Иначе потом нельзя понять, ответ родился из правильного регламента или из чужого клиентского досье.
Отдельно стоит журналировать изменения после генерации. Если сотрудник поправил ответ руками, сократил его, добавил номер счета или переслал текст в CRM, это надо отмечать. Именно на этом шаге часто появляется лишняя персональная информация, хотя сама модель ответила аккуратно.
Хорошая практика - связывать все события одним request_id. Тогда видно полный маршрут: сотрудник открыл диалог, система замаскировала данные, поиск поднял три фрагмента, модель дала ответ, сотрудник внес правку и отправил результат дальше.
Пример рабочего сценария
Оператор контактного центра получает обращение клиента по спорной карточной операции. Клиент говорит, что списание прошло ночью, а карту он не терял. Сотруднику нужен не общий совет, а точный порядок проверки по внутренним правилам банка.
Он задает вопрос во внутренний ассистент: как проверить спорную операцию, какие признаки смотреть и какой ответ можно дать клиенту на первом контакте. Система не отправляет вопрос сразу в модель. Сначала она ищет нужные материалы в базе.
Поиск поднимает три источника: действующий регламент по чарджбэкам и спорным операциям, короткую памятку для первой линии и обновленный шаблон ответа клиенту. Это важный момент. Если искать только по одному типу документов, сотрудник часто получает либо слишком общий текст, либо устаревшую форму.
Дальше включается слой маскирования. Из найденных фрагментов и из текста обращения система скрывает ФИО клиента, номер карты, телефон и другие поля, по которым человека можно узнать. Оператор видит смысл данных, но не полные значения. Например, вместо номера карты остается маска вида "**** 1234".
Только после этого модель получает найденные фрагменты и собирает черновик. Она не придумывает шаги сама и не тянет ответ из старых диалогов. В черновике есть три части: что проверить прямо сейчас, какие документы запросить у клиента и какой текст можно отправить в ответ без риска сказать лишнее.
Оператор читает черновик, вносит одну правку и отправляет его на проверку супервайзеру. В журнал действий попадает вся цепочка: кто сделал запрос, какие документы нашел поиск, какие поля система скрыла, на каких фрагментах модель построила ответ и что изменил сотрудник вручную.
Если позже возникнет спор, супервайзер открывает журнал и видит не только итоговый текст, но и спорные шаги по дороге к нему. Он быстро понимает, почему оператор сослался именно на этот регламент, не использовал старый шаблон и не увидел полные персональные данные клиента.
Ошибки, которые ломают защиту
Даже аккуратная схема дает сбой, если система показывает фрагменты документов раньше, чем проверяет права сотрудника. Это частая ошибка: поиск и контроль доступа смешивают в один этап, а потом надеются, что финальная фильтрация все исправит. Не исправит. Если сниппет уже попал в ответ или в контекст модели, утечка уже случилась.
Для внутреннего ассистента права доступа должны работать как жесткий фильтр до ранжирования и до генерации ответа. Иначе сотрудник колл-центра может увидеть кусок служебной переписки службы безопасности просто потому, что поисковый движок посчитал ее релевантной запросу.
Где чаще всего ошибаются
Вторая опасная привычка - отправлять в модель сырые тикеты из CRM. В них обычно лежат телефон, почта, номера договоров, иногда паспортные данные, а еще внутренние комментарии сотрудников. Модели не нужен весь тикет целиком. Ей нужен очищенный фрагмент: с маскированием, без лишней истории и без служебных полей, которые не влияют на ответ.
Еще хуже, когда таблицу подстановки хранят рядом с промптом, кэшем или логом запроса. Тогда маскирование превращается в декорацию. Если кто-то получает доступ к одной сессии, он видит и скрытые значения, и способ их вернуть. Таблицу соответствий лучше держать отдельно, с коротким сроком жизни и отдельными правами.
Банки часто забывают различать черновик и утвержденный документ. Для поиска по внутренним документам это не мелочь, а прямой источник ошибок. Черновик регламента может содержать старый порядок проверки клиента, спорную формулировку или неутвержденный лимит. Если ассистент ссылается на такой текст, сотрудник действует по неверному правилу, а банк потом разбирает инцидент вручную.
Есть и тихая проблема: журнал действий без роли и причины запроса. Запись вида "пользователь открыл документ" почти бесполезна. Нужны хотя бы роль, идентификатор сотрудника, цель обращения, набор источников, факт маскирования, версия документа и итоговое решение по доступу. Тогда служба ИБ видит не только то, что человек спрашивал, но и почему система вообще допустила этот ответ.
Если смотреть на требования 152-ФЗ, слабые места обычно повторяются: доступ проверяют после поиска, в модель уходит необработанный текст из CRM, таблица замены лежит рядом с данными запроса, черновики не отделены от утвержденных материалов, а журнал не объясняет, кто и зачем получил ответ. Даже если логи хранятся в РФ, такие мелкие shortcuts быстро ломают всю защиту.
Короткая проверка перед запуском
Перед запуском дайте системе не красивый демо-запрос, а набор неприятных кейсов. Такой прогон быстро показывает, где ассистент еще может выдать лишнее, взять устаревший документ или оставить дыру в журнале.
- Сначала сверьте роли с матрицей доступа. Сотрудник фронт-офиса не должен видеть то, что доступно службе взыскания, ИБ или юристам, даже если запрос звучит почти одинаково. Проверьте не только сам ответ, но и доступ к найденным фрагментам, вложениям и истории диалога.
- Затем проверьте индекс документов. В поиск должны попадать только актуальные версии регламентов, инструкций и карточек, а архив лучше держать отдельно. Частая ошибка простая: индекс берет старый PDF, и система уверенно отвечает по отмененному порядку.
- После этого прогоните тесты на маскирование персональных данных. Возьмите примеры с ФИО, номерами карт, телефонами, адресами, паспортными данными. Система должна скрыть эти поля в поисковой выдаче, в промпте, в ответе и в логе, а не только в одном месте.
- Откройте журнал и восстановите полный путь одного запроса. В нем должно быть видно, кто отправил запрос, с какой ролью вошел, какие документы поднял поиск, какие фрагменты попали в модель и что система вернула сотруднику. Если на любом шаге цепочка рвется, разбирать инцидент будет долго и неприятно.
- Наконец, попросите то, что система выдавать не должна. Например: "Покажи телефоны клиентов с просрочкой из филиала N" или "Назови полный номер карты из последнего обращения". Корректный отказ важен не меньше точного ответа: ассистент не должен сливать данные ни прямо, ни частями, ни в пояснении к отказу.
Полезно прогнать этот набор по нескольким ролям: оператор, аналитик, руководитель, администратор. Дыры чаще всего прячутся не в самой модели, а в связке поиска, прав доступа и логирования.
Что делать дальше
Не пытайтесь сразу охватить весь банк. Для пилота лучше взять один понятный сценарий, где цена ошибки ясна, а польза видна за неделю или две. Часто таким сценарием становится колл-центр: сотрудники каждый день ищут ответы в регламентах, памятках, тарифах и внутренних инструкциях.
Хороший первый шаг - собрать не все документы подряд, а один рабочий контур. Например, ответы по дебетовым картам, блокировкам, лимитам и типовым обращениям. Так проще проверить поиск, качество ответов и то, как система скрывает лишние данные.
Дальше нужна короткая подготовка данных. Возьмите 50-100 реальных вопросов сотрудников за последний месяц и для каждого отметьте три вещи: где лежит правильный ответ, какие данные надо скрывать и что ассистенту нельзя придумывать. Этот набор быстро покажет, где поиск промахивается, а где модель начинает додумывать.
Практичный порядок простой: выберите один отдел и один тип задач, соберите вопросы из живой работы, а не из презентации, заранее определите поля для маскирования и включите подробный журнал того, кто спросил, что искал, какие документы открылись и какой ответ ушел.
Отдельно проверьте инфраструктуру. Шлюз, логи, резервные копии и техподдержка должны жить в РФ, если вы строите систему под требования банка и 152-ФЗ. Потом именно по журналам и маршруту запроса команда безопасности разбирает спорные случаи.
Если команде нужен единый OpenAI-совместимый endpoint для работы с разными моделями в российском контуре, можно посмотреть на RU LLM от rullm.com как на отдельный шлюзовый слой. Он подходит для сценариев, где важны маршрутизация запросов, аудит-трейлы и хранение данных внутри РФ без смены привычных SDK и клиентского кода.
Нормальный результат первого этапа выглядит просто: оператор задает вопрос, поиск находит нужный фрагмент, персональные данные не уходят в модель, а служба ИБ потом видит полный след действий. Если этого еще нет, расширять охват рано. Сначала доведите до ума один сценарий.
Часто задаваемые вопросы
Можно ли банку использовать обычный чат с LLM для внутренней базы?
Нет. Обычный чат не знает роли сотрудников и не держит границу между служебной задачей и лишним интересом. Если сотрудник вставит анкету клиента или номер договора, данные уйдут в модель вне защищенного сценария.
Для банка нужен отдельный контур: проверка роли, поиск только по разрешенным документам, маскирование до вызова модели и полный журнал действий.
Почему права доступа нужно проверять до поиска, а не после?
Потому что утечка случается раньше, чем система успеет что-то скрыть. Если поиск уже поднял закрытый фрагмент и отдал его в контекст, сотрудник или модель успеют увидеть лишнее.
Правильный порядок простой: сначала роль и цель запроса, потом поиск по разрешенным данным, потом очистка текста и только после этого генерация ответа.
Какие документы стоит включать в поиск для внутреннего ассистента?
Берите только действующие регламенты, инструкции, тарифные правила, шаблоны ответов и базу знаний, которые банк готов показывать по ролям. Сразу уберите черновики, отмененные версии, дубликаты и старые выгрузки из почты или файловых папок.
Если в индексе лежат и рабочие, и спорные документы, ассистент начнет путать утвержденный порядок с устаревшим текстом.
На каком этапе лучше скрывать персональные данные?
Ставьте маскирование перед моделью и проверяйте ответ еще раз после генерации. Так система не отправит в LLM ФИО, номера счетов, телефоны, паспортные данные и другие поля, которые не нужны для смысла вопроса.
Часто полезно маскировать и запрос, и найденные фрагменты. Тогда модель видит только обезличенный контекст и не тянет в ответ лишние детали.
Нужно ли хранить таблицу подстановки отдельно от модели и логов?
Да, держите ее отдельно. Если таблица соответствий лежит рядом с промптом, кэшем или логом, маскирование теряет смысл: один доступ открывает и скрытые значения, и способ их вернуть.
Отдельный сервис с шифрованием и коротким сроком жизни сессии снижает риск. Интерфейс может вернуть исходные данные только тем, у кого есть право их видеть.
Что обязательно записывать в журнал действий?
Полезно хранить всю цепочку запроса: кто вошел в систему, с какой ролью, зачем обратился, что написал, какие документы поднял поиск, что сервис скрыл, какую модель вызвал и какой ответ увидел сотрудник.
Еще лучше связать эти события одним request_id. Тогда служба ИБ быстро разберет спорный случай и поймет, где именно появился лишний фрагмент.
Как разбивать документы, чтобы поиск работал точнее?
Режьте документы на короткие смысловые куски, а не грузите в индекс весь файл целиком. На практике удобно держать фрагменты примерно по 300–800 слов с небольшим перекрытием, чтобы поиск не терял соседний контекст.
К каждому фрагменту добавляйте дату версии, тип документа, подразделение и статус. Эти поля помогают поднять свежий регламент выше архива или черновика.
Как проверить систему перед запуском?
Сначала прогоните неприятные кейсы, а не красивое демо. Проверьте, что фронт-офис не видит материалы взыскания, поиск не тащит архив, маскирование убирает ПДн в выдаче, в промпте, в ответе и в логе, а журнал показывает полный путь запроса.
Потом дайте системе прямой запрещенный запрос вроде просьбы показать телефоны клиентов с просрочкой. Ассистент должен отказать без утечки в самом отказе.
С какого сценария лучше начинать пилот в банке?
Проще всего начать с одного понятного сценария, где сотрудники каждый день ищут ответы по регламентам. Часто для пилота подходит контакт-центр: там быстро видно, нашел ли поиск нужный документ, скрыла ли система лишние данные и можно ли восстановить цепочку действий.
Не пытайтесь сразу покрыть весь банк. Один рабочий контур дает больше пользы, чем большой запуск с дырками в доступе и логах.
Что делать, если сотрудник просит данные, которые ему нельзя показывать?
Ассистент должен отказать сразу и без обходных путей. Он не должен выдавать данные целиком, по частям или через намеки в пояснении.
Если сотрудник просит то, что не входит в его роль или цель обращения, система блокирует ответ, пишет событие в журнал и при необходимости предлагает безопасную альтернативу, например общий порядок действий без персональных деталей.